
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 北京科技报
北京科技报 10月8日,瑞典皇家科学院宣布,2024年度诺贝尔物理学奖授予美国科学家约翰·霍普菲尔德(John Hopfield)以及加拿大学者杰弗里·辛顿(Geoffrey Hinton),以表彰他们利用人工神经网络实现机器学习的基础性发现和发明。
此前大家预测的物理学奖热门领域(如凝聚态物理或量子物理)最终都没有获奖,出乎很多人的意料。虽然诺奖委员会强调,“两位诺贝尔物理学奖得主,利用物理学工具开发出当今强大机器学习的基础方法。”但还是有网友感慨,“物理学(奖)不存在了。”
近几年,人工智能(AI)在人们身边卷起了一股热潮,我们很容易认为这是一项近期的创新。事实上,人工智能以各种形式存在已有70多年了。回顾AI工具的研究发展历程,对于我们理解这个大热领域未来的发展之路会很有帮助。
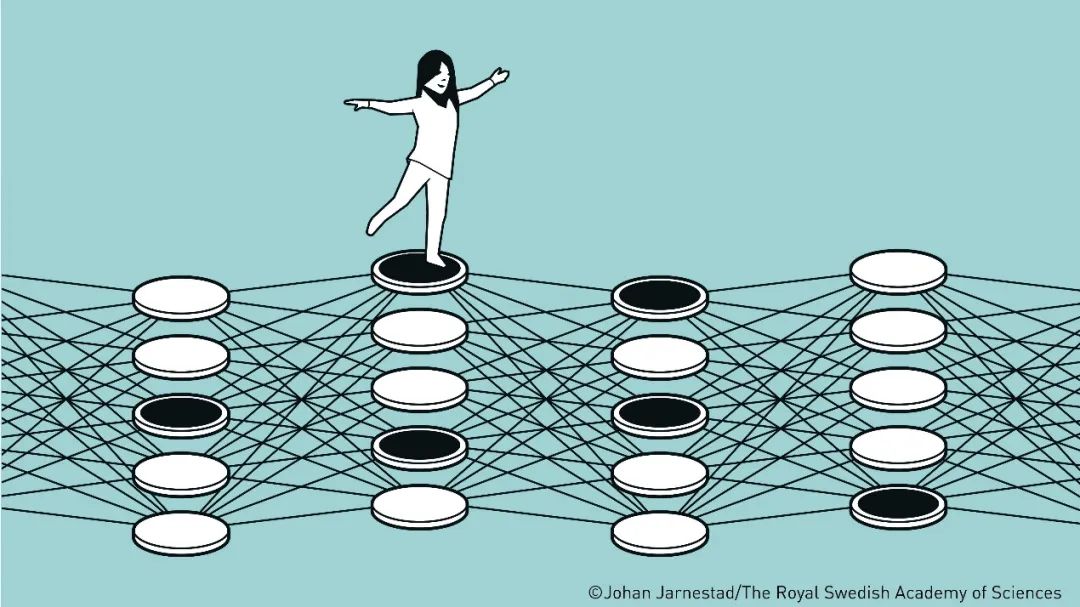
▲图片来源:瑞典皇家科学院
每一代AI工具都可以被视为对前代的改进,但值得注意的是,没有一种AI正在朝着“有意识”的方向发展。今年诺贝尔物理学奖获奖者之一,被誉为“AI教父”的杰弗里·辛顿也认为,虽然AI有可能变得比人类更聪明,但应该将其视为与人类完全不同的智能形式。
AI的发展历程可以大致分为三个阶段:符号主义AI、连接主义AI和当前的深度学习时代。
符号主义AI时代(1950s-1980s)
1950年,计算机先驱艾伦·图灵在一篇开创性的文章中提出:“机器能思考吗?”
并提出了“模仿游戏”的概念(现在通常被称为图灵测试)。在这项测试中,如果一台机器在纯文本形式对话中的表现无法与真人区分开来,就被认为是拥有智能的。
五年后,“人工智能”这个术语首次在著名的达特矛斯会议中出现,标志着AI研究的正式开始。这个时期的AI主要以符号主义为主导,试图通过类似于人脑的逻辑推理和知识表示来模拟人类思维。
从20世纪60年代开始,一类被称为“专家系统”(Expert systems)的AI分支开始发展。这些系统旨在捕捉特定领域的人类专业知识,并使用明确的知识表示。
这类系统是“符号AI”的典型例子,早期出现了许多广为人知的成功案例,包括用于识别有机分子、诊断血液感染和勘探矿物的系统。其中最引人注目的是名为R1的专家系统,据报道,1982年它通过设计高效的小型计算机系统配置,为数字设备公司每年节省2500万美元。
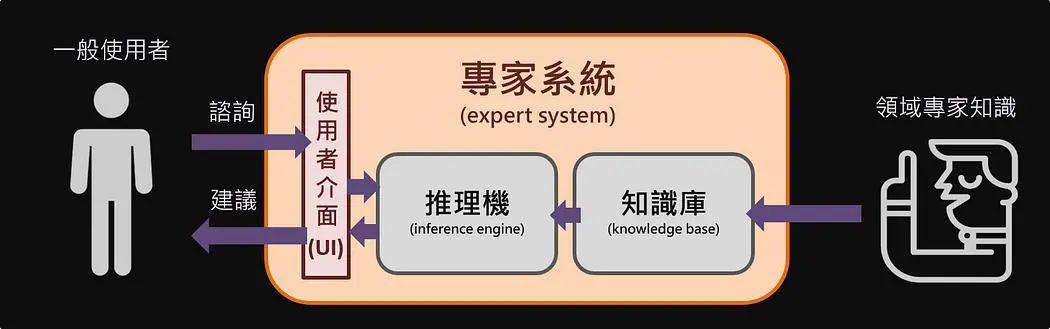
▲图片来源:medium.com
专家系统的主要优势在于,即使没有编程专业知识的某领域专家,也可以参与构建和维护计算机的知识库。专家系统中,一个被称为“推理机”(Inference engine)的组件能够应用这些知识来解决领域内的新问题,并提供解释性的证据链。
这类系统在上世纪80年代非常流行,各组织争相构建自己的专家系统。值得一提的是,专家系统至今仍是AI的一个重要组成部分。然而,专家系统也面临着一些限制,如知识获取瓶颈和难以处理不确定性问题。这些约束促使研究人员探索新的方法。
联结主义AI与机器学习的崛起(1980s-2000s)
人脑包含约1000亿个神经细胞(神经元),它们通过树突(分支)结构相互连接。受到人脑的启发,一个称为“联结主义”的独立领域也应运而生——与专家系统试图模拟人类推理过程不同的是,这种新方法试图直接模拟人脑的神经网络。
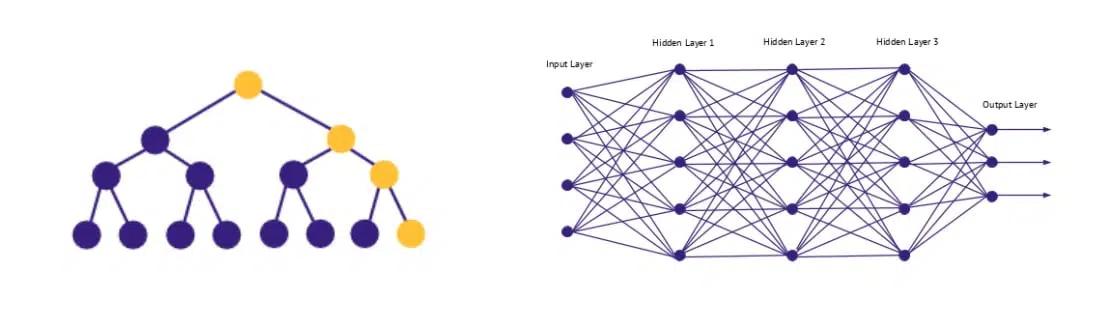
▲符号主义AI(左)和联结主义AI(右)示意图
早在1943年,两位美国学者沃伦·麦卡洛克和沃尔特·皮茨就提出了人类神经元联结的数学模型,每个神经元根据输入的二进制信号,产生对应的二进制输出。这为后来的神经网络奠定了基础。
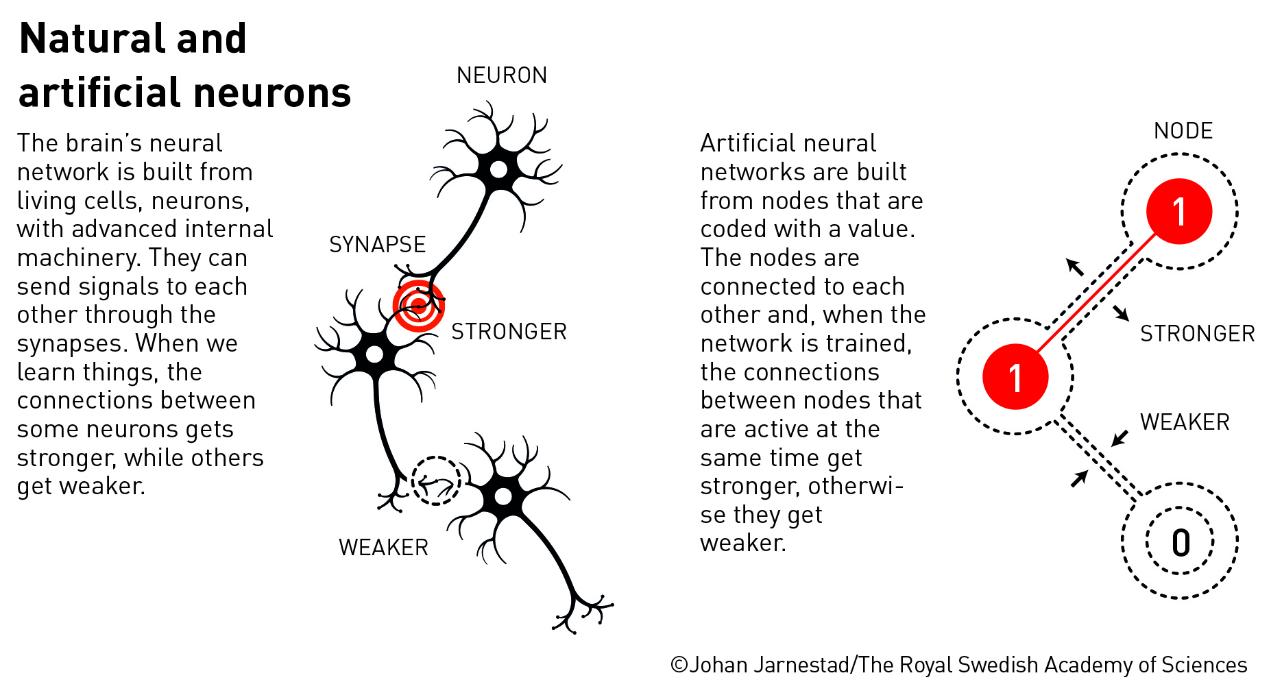
▲图片来源:瑞典皇家科学院
1960年,弗兰克·罗森布拉特(Frank Rosenblatt)提出了“感知器”(Perceptron)的概念,这是一种简单的人工神经网络。同年,伯纳德·维德罗(Bernard Widrow)和泰德·霍夫(Ted Hoff)开发了ADALINE(ADAptive LInear NEuron),这些是模拟神经元的最早实践,虽然有趣,但实际应用都很有限。
1969年,达特茅斯会议的发起人之一马文·明斯基和西摩·佩珀特(Seymour Papert)在他们的著作《感知器》中指出了单层神经网络的局限性,这导致了神经网络研究的短暂停滞。然而,这个挫折也促使研究人员探索“更复杂”的网络结构。
1986年,今年诺贝尔物理学奖获得者之一的杰弗里·辛顿,与几位合作者发表了一篇开创性论文,介绍了反向传播算法,这为“多层感知器”(Multi-Layered Perceptron,MLP)的学习算法奠定了基础。
反向传播算法允许神经网络探索数据内部的深层表征,因此神经网络才能解决以前被认为无法解决的问题。这是一项重大突破,实现了从一组示例(训练)数据中学习,然后进行归纳总结,以便对以前未见过的输入数据(测试数据)进行分类。
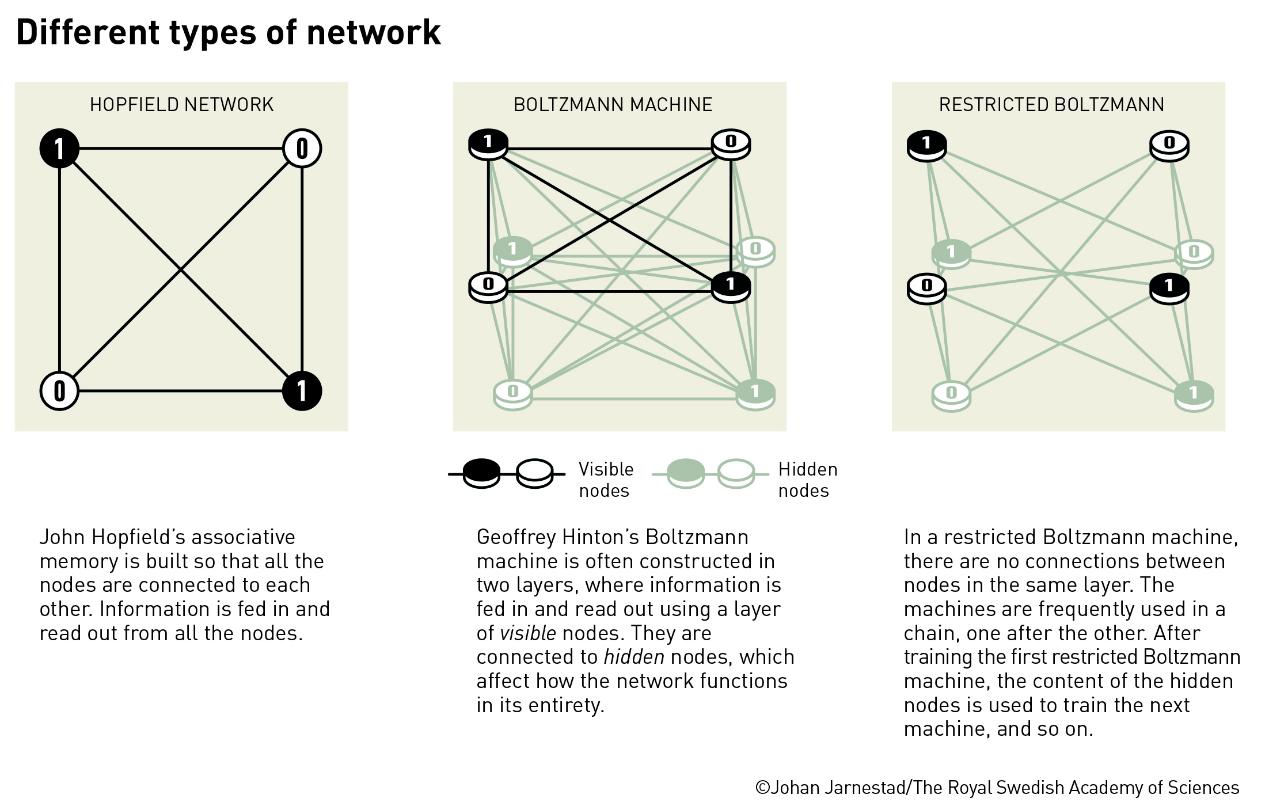
▲图片来源:瑞典皇家科学院
MLP通常是三层或四层简单模拟神经元的排列,每一层与下一层完全互连。MLP通过在神经元之间的连接上附加数值权重并调整它们来实现学习,以获得最佳的训练数据分类,以便对新的、未见过的数据进行分类。
在这个阶段中,今年另一位诺贝尔物理学奖获得者约翰·霍普菲尔德也做出了重要贡献。1982年,他提出了“霍普菲尔德网络”,这是一种递归神经网络模型,能够作为内容可寻址的记忆系统。霍普菲尔德网络的引入,为神经网络研究带来了新的活力,并为后来的深度学习发展奠定了重要基础。他的工作展示了如何使用物理学概念(如能量最小化)来理解神经网络的行为,为后续的神经网络研究提供了新的视角。
只要数据以适当的格式呈现,MLP就可以广泛处理各种实际问题。一个经典例子是手写笔迹的识别,但前提是图像需要经过“预处理”(Pre-processing)以提取关键特征。这个时期还出现了其他重要的机器学习算法,如支持向量机(SVM)和决策树,它们在某些任务上表现出色。
深度学习时代(21世纪)
随着计算机算力的显著提升和大数据时代的萌芽,深度学习在21世纪初开始兴起。2006年,杰弗里·辛顿提出了“深度信念网络”(Deep Belief Networks, DBNs),这被认为是深度学习时代的开端。
MLP取得成功后,开始出现了多种新型神经网络。其中一个重要的是1998年由法国计算机科学家杨立昆(Yann LeCun)等人提出的“卷积神经网络”(Convolutional Neural Network,CNN)。CNN与MLP类似,但增加了额外的神经元层,用于识别图像的关键特征,从而消除了预处理的需要。如今,CNN在图像识别和计算机视觉任务领域取得了巨大成功。

▲图片来源于网络
前面所说的MLP和CNN都属于擅长分类、判断、预测的“判别模型”(Discriminative Model)。而近几年来,不断涌现的各种能写诗、画画的“生成模型”(Generative Model),也开始大放异彩。
2014年,美国学者伊恩·古德费洛(Ian Goodfellow)等人又提出了“生成对抗网络”(Generative-Adversarial Networks,GANs)。GANs的一个重要组成部分是“判别器”(Discriminator),即一个内置的批评者,不断要求“生成器”(Generator)提高输出质量。GANs在AI图像生成、风格迁移等任务中表现出色。
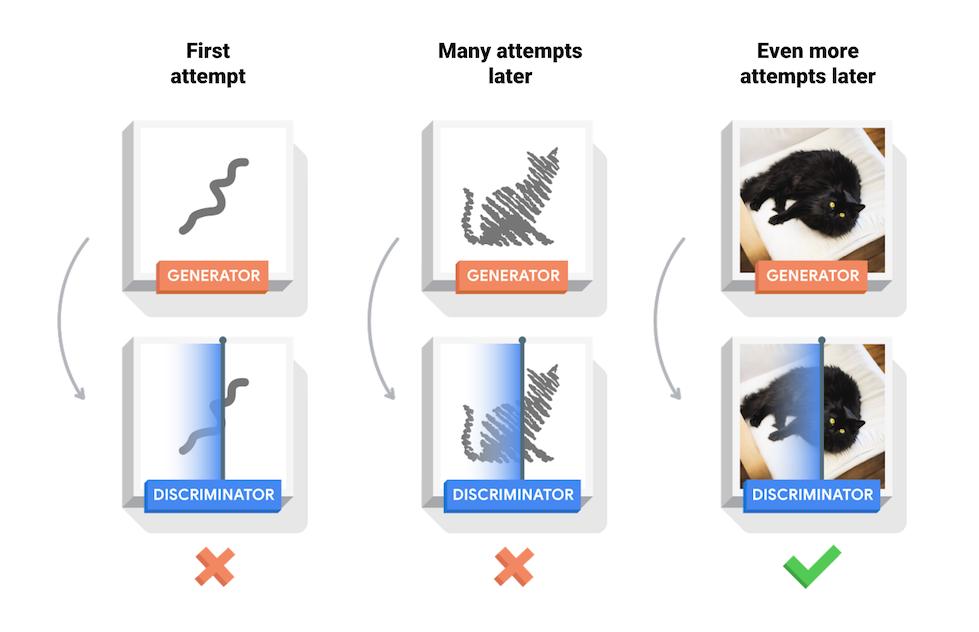
▲图片来源:tensorflow.org
2017年,谷歌的研究人员提出了“转换器”(Transformer)架构,这是一种基于自注意力机制(Self-Attention)的神经网络模型。传统神经网络的编码器需读取和处理整个输入数据序列,而新的架构并不按顺序处理数据,而是使模型能够同时查看序列的不同部分,并确定哪些部分最重要。
基于转换器的新兴模型(如BERT和GPT系列等),在自然语言处理任务中取得了突破性进展,推动了“大型语言模型”(Large-Language Models,LLMs)领域的发展。这些大型语言模型从互联网上抽取海量数据集进行训练。通过强化学习(Reinforcement Learning),人类训练师们提供的反馈进一步提升了它们的性能。
除了展现令人印象深刻的生成能力外,庞大的训练集使这些神经网络不再像早期AI那样局限于狭窄领域,而是几乎可以涵盖任何主题。这些模型在各种任务中展现出惊人的能力,包括自然语言理解、文本生成、问答系统等。
大语言模型的强大能力引发了一些关于“AI可能接管世界”的担忧。然而,这种危言耸听是不合理的。尽管当前的模型显然比早期的AI更强大,但发展轨迹仍然坚定地朝着更大容量、更可靠和准确的方向发展,而非朝着任何形式的“意识”进化。
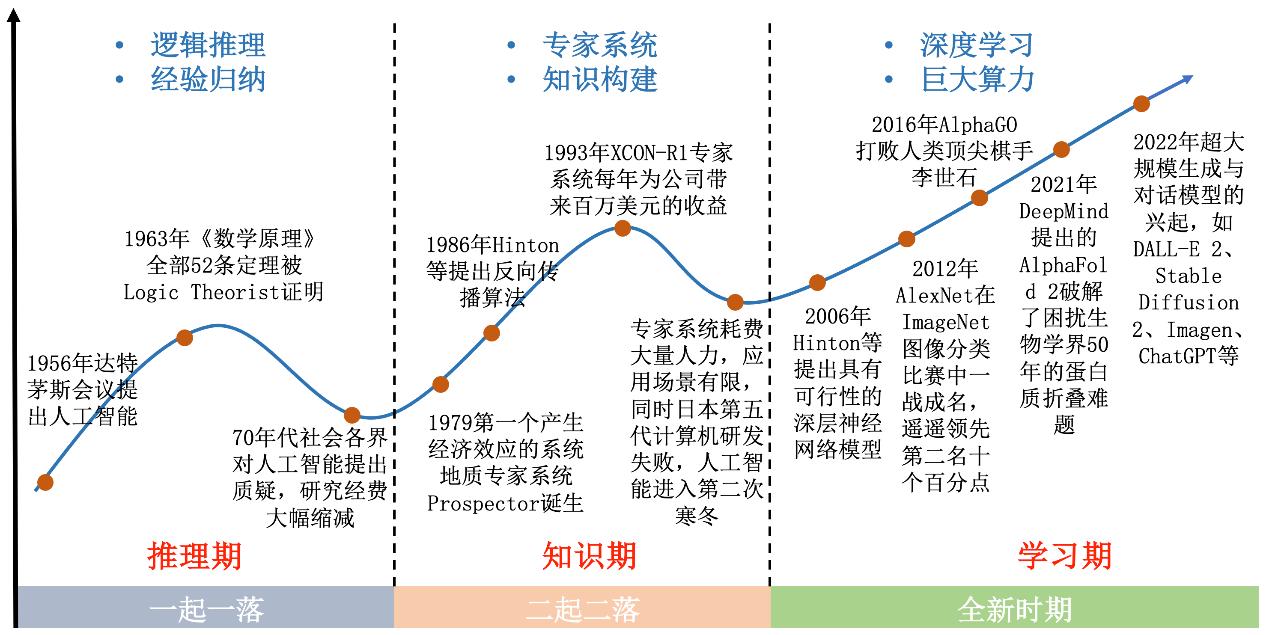
▲人工智能的发展历程(图片来源:github.io)
AI有许多积极和令人兴奋的潜在应用,但回顾历史可以看出,机器学习并非唯一的工具。符号主义AI仍然发挥着重要作用,因为它允许将已知事实、理解和人类观点纳入其中。未来的AI发展可能会融合符号主义和联结主义的优点,形成所谓的“混合式神经-符号人工智能”(Neuro-symbolic AI)。
例如,可以为无人驾驶汽车直接提供道路规则,而不是提供示例来开展学习。医疗诊断系统可以结合机器学习模型的预测能力和专家系统的逻辑性,根据医学知识验证和解释机器学习系统的输出信息。
回顾历史不难看出,AI技术的发展过程中,不仅吸纳了存在多年的成熟技术,也有不断涌现的新方法。未来,我们可能会看到更多的跨学科融合,如AI与脑科学、认知科学的结合,以及AI在科学研究、气候变化应对、个性化医疗等领域的广泛应用。
来源:北京科技报
来源: 北京科技报
