
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普中国创作培育计划
科普中国创作培育计划 
AI视频
AI生成视频技术的快速发展,让许多人开始重新思考视频制作的未来,AI究竟会给视频行业带来什么影响?它又是如何生成视频的?
要搞清楚这些,我们先从与AI生成视频最接近的电脑动画视频说起。
AI在动画视频制作领域的机会
传统动画视频的制作过程极其繁琐且昂贵。
在2008到2018年期间,美国每部动画电影的成本依然在4000万到7000万美元上下。
AI的出现,让动画视频的制作成本和制作周期都有机会大幅压缩。比如,仅仅考虑AI的图片生成能力,它已经能在动画视频领域帮大忙了。
在过去制作动画视频的时候,场景、人物素材都需要由手动绘制。AI的图片生成能力,让它可以直接生成原画素材,在这个基础上人类插画师动画师再进行调整,这远比从零开始绘制要快得多。
AI能做到的还不止这些。
2024年初,Open AI发布了视频生成模型Sora,它再一次展现了AI在视频生成领域的强大潜力。
其实,Sora并不是第一个视频生成模型,在2023年2月和6月,Runway就分别发布了Gen-1和Gen-2。Stability和Pika 也都在2023年发布了自己的视频生成模型。
但和之前的模型相比,Sora生成的视频时间更长,最长的甚至能达到1分钟之久。而且在Sora生成的视频中,人物的动作、镜头的移动看起来也更加自然流畅,乍一看就像是别人拍摄的视频,或者是某家动画公司制作的。
AI生成视频的原理
那Sora到底是如何生成这些视频的?
根据Open AI 发布的技术报告,Sora能有这样的视频生成能力,跟两个技术有关,首先是扩散模型。
扩散模型在训练的时候包括两个重要的过程:前向扩散和反向扩散。
前项扩散可以理解成照片上的像素点逐渐变得混乱,逐渐杂乱无章的过程。而这个过程的逆过程,就是反向扩散,模型需要还原出被打乱之前的图像画面。通过大量的训练,AI就能根据提示词,还原出预期的图像。
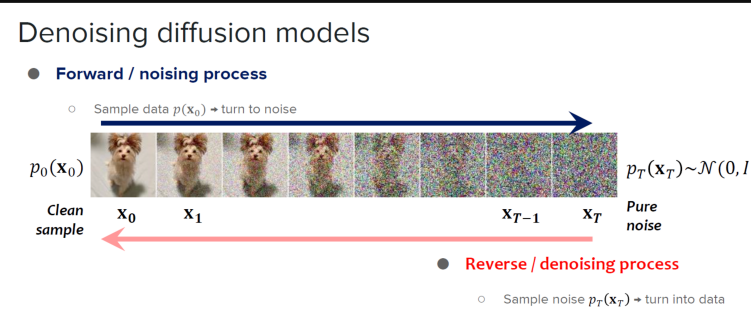
很多图像生成模型和视频生成模型,比如Runway的Gen-2,Stable Diffusion,还有Sora使用的都是扩散模型。
但仅仅能够生成精美的图片还不够。
Sora还从大语言模型的架构中找到了灵感,它是一个diffusion transformer【可以直接在网站里圈出Sora is a diffusion transformer这句话↓】。

Transformer是GPT、BERT之类大语言模型的重要架构。
Transformer会对针对文本中的每一个字词进行拆分,把它们作为分析的token,对token中的语义进行学习,并且在处理长文本信息的时候,也能记住上下文文本之间的关联。
而Sora这样的模型在进行训练的时候,也会把视频中的画面、时间要素拆分为基本单元patch,通过对patch的学习,AI就可以找到这些视频画面内部的逻辑,进而根据要求生成新的视频。
Sora可以基于文本生成视频,也可以直接针对输入的图片生成视频,或者对已有视频进行前后扩展、优化调整。
不过,Sora也不算完美,如果细看Sora生成的视频,也会看到很多不符合客观世界规律的情况,比如这个杯子打碎的过程就跟客观世界的规律不太符合。另外,有些动物也会凭空消失或者出现,而这个椅子的表现就更加奇怪了。所以,AI想要生成出符合客观世界规律的完美视频,依然有很长的路要走。
Sora只是个开始
在Sora发布之后,各大科技公司也纷纷发布了自己的视频模型。
比如Luma Labs发布的Dream Macine,以及stable diffusion发布了Gen-3,它们展示出来的文本到视频生成能力,并不亚于Sora。
另外Picsart AI Resarch等团队联合发布了StreamingT2V,它声称能够生成120秒的长视频,比Sora的1分钟长出1倍。
而在AI视频生成领域,我们国家的科技公司也发布了自己的模型,比如快手的可灵,生数科技的Vidu,阿里的EMO,百度的UniVG等等。
这些工具生成视频的成本和使用门槛都很低,在教育动画、电影制作、以及广告设计等领域会带来天翻地覆的变化。
同时,在这些视频生成工具的帮助下,普通人有机会把自己的创意想法变为视频,降低了视频制作的门槛。相信,这样的技术将给视频行业以及媒体行业带来新的新质生产力工具。
对此,让我们拭目以待。
作者:云纪御 科普创作团队
审核:秦曾昌 北京航空航天大学 自动化科学与电气工程学院 副教授
文章由科普中国-创作培育计划出品,转载请注明来源。
来源: 星空计划
内容资源由项目单位提供
