
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中国人工智能学会
中国人工智能学会 
0 引言
中医学是中国传统科学中沿用至今的富有中国文化特色的医学,它具有系统的理论体系,独特的诊疗手法和显著的临床疗效等特征,在中华民族历史长河中,始终担负着促进健康发展的重要角色。在与 2020 年初爆发的新型冠状病毒疫情斗争的过程中,中医药通过临床运用,表现出良好的疗效,发挥了一定的防治作用。
传统的中医知识大多以古籍文言文的方式记载,后人在学习和理解过程中存在一定的难度。针对中医古籍文言文的信息抽取能降低学习成本,并且能有效地推广中医领域相关知识以促进其临床诊疗和应用。
1 中医古籍文言文信息抽取的研究内容
文本的信息抽取主要有实体抽取、实体关系抽取和事件抽取三种任务。对于中医古籍而言,信息抽取的任务更多关注实体抽取和关系抽取。相对于现代白话文,文言文写作方式简练,对应语料相对较少,因此对文言文古籍进行自动化信息抽取的难度更大。
1.1 中医古籍的实体抽取
实体抽取也称为命名实体识别(Named Entity Recognition,NER),主要是将非结构化文本中的人名、地名、机构名和具有特定意义的实体抽取出来并加以归类,组织成半结构化或结构化的信息。实体识别是文本处理的基础,对文本后续的分析和理解起着至关重要作用。
中医古籍文本中蕴含了丰富的理论知识及临床经验,通过信息抽取技术的介入,能大量、准确、自动化地提出所需要的信息。利用命名实体识别技术,挖掘中医领域实体具有一定潜在的应用价值。例如,中医领域的研究人员可以借助此技术识别文本中的中药名词和方剂名词,以加快中医药知识库的检索速度及准确率。
中医术语的自动识别指从中医文献中识别出症状、病名、脉象、方剂、中药材、功效等术语实体,以结构化的形式存入关系数据库中,供进一步查询或分析使用。例如,《中华药典》中有一段关于“生化汤”的描述,我们对其进行实体抽取,得到分别属于“方剂”“中药材”和“功效”这三类中的 7个实体,如图 1 所示。

图 1 从中医古籍文本中抽取实体信息展示
1.2 中医古籍的关系抽取
关系抽取是从一段文本中提取出发生在两个实体之间语义关系的任务。通过关注两个实体间的语义关系,最后得到一个“主体 - 关系 - 客体”的三元组,其中“主体”和“客体”都是实体在关系中的角色,在三元组中则指代在这一关系中对应角色的实体。
依然以《中华药典》中对“生化汤”的描述为例。根据文本内容可知,在生化汤这一方剂中,当归为君,川芎、桃仁为臣,黑姜为佐,灸甘草为使。那么可以得到的三元组有“生化汤 - 君 - 当归”“生化汤 - 臣 -川芎”“生化汤 - 臣 - 桃仁”“生化汤 - 佐 - 黑姜”和“生化汤 - 使 - 灸甘草”;同时还可以知道生化汤的功效为活血化瘀,那么又可以得到三元组“生化汤 - 功效 -活血化瘀”。关系抽取后得到的实体关系,如图2所示。
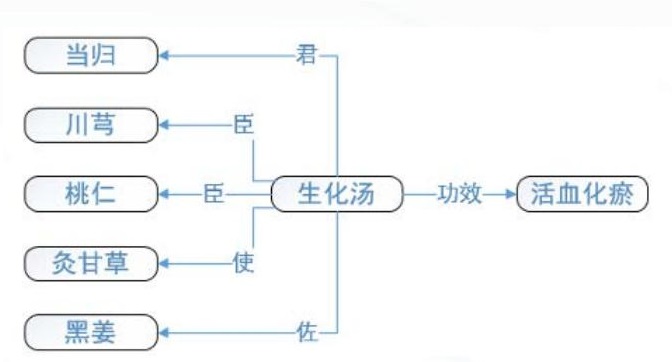
图 2 从中医古籍中抽取实体关系结果展示
2 信息抽取的相关技术
信息抽取是指从自然语言文本中 , 抽取出特定的事件或事实信息,从而将海量文本内容自动分类、提取和重构。下面主要介绍信息抽取过程中涉及到的相关理论与技术。
2.1 词向量与预训练语言模型
词向量是在自然语言处理领域中重要的基础,构建有效的词向量有利于对情感、句法、语义等方向进行深入研究分析。词向量的构成有很多方法,如 OneHot与词袋模型、预训练词向量和预训练语言模型。
2.1.1 One-Hot 与词袋模型
One-Hot 编码是一种非常原始的文本编码方法。其主要思想是,设语料库的词典大小为 n,那么设立一个 n 维的向量,假如某个词在词典中的位置为 k,这个向量的第 k 维置为 1,其他维全部置 0。这种方法只是将文本的字或词进行最简单的向量化,而没有考虑词序及其语义特征。
词袋模型则是针对句子或者篇章的编码模型。在上述提到的语料库中,假如一句话中包含三个词,这三个词在词典中的位置分别为 i、j、k,那么设立一个 n 维的向量,这个向量的第 i、j、k 分别设为 1,其他维设为 0。这种方法虽然实现了对文本句子或篇章的编码,但是没有考虑句子内部的上下文特征。
总之,上述两种方法只能实现最基本的文本向量表示功能,没有考虑文本的语义信息。
2.1.2 预训练词向量
为了解决 One-Hot 编码向量过于稀疏,同时又不包含语义特征的特点,研究者开始用维度较小的稠密向量来对字或词进行表示。现有的主流词向量表示模型有 word2vec、fastText、GloVe 等。
这类方法一般都是利用大量语料训练出针对词表中每个词的词向量表示,在后续任务直接使用。这种方法虽然使训练出的词向量具有一定语义特征,但是难以解决一词多义现象。比如词汇“小米”,它既可以代表一家公司的名称,又可以代表一种“五谷”中的粮食名称。然而,在上述的这些方法产生的词向量中,“小米”都只有一种向量表示,无法从这样的预训练词向量中分辨文本中出现的“小米”该属于哪种解释。
2.1.3 预训练语言模型
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 公司于 2018 年提出的一种预训练语言模型。它使用 Google 公司 在“Attention is all you need”一文中提出的Transformer 结构作为网络结构。在实际应用中,将句子输入 BERT 后,可以得到对应的编码结果,该结果可用于后续具体任务转化。鉴于 BERT 强大的性能,各种预训练语言模型如雨后春笋般地涌现 出 来。例 如 XL-Net、RoBERTa、BERT-wwm、ALBERT、ERNIE 等,均为基于 BERT 的思想衍生出来的预训练语言模型。北京理工大学的阎覃等基于 BERT-wwm,利用大量的古籍文本训练出了专门用于面向古汉语文本的预训练模型 GuwenBERT,该模型在 2020 年“古联杯”古籍文献命名实体识别评测大赛中取得了优异成绩。
2.2 双向长短时记忆网络
长 短 时 记 忆 网 络(Long Short-term Memory Network,LSTM) 是 继 循 环 神 经 网 络(Recurrent Neural Network,RNN)之后具有里程碑意义的神经网络。它的主要目的是解决序列训练过程中的梯度消失问题和梯度爆炸问题。LSTM 内部通过门控状态来控制传输状态,存储重要信息,丢弃不重要信息,因而它在序列相关问题中,与 RNN 相比有着更好性能。LSTM 的网络结构,如图 3 所示。
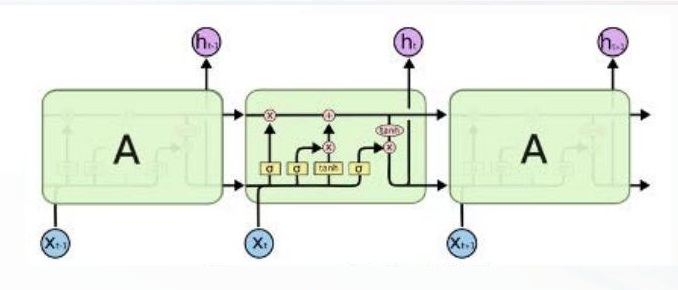
图 3 LSTM 的网络结构图
通常情况下,句子中字或词的具体含义除了其本身含义外,还要受到上下文影响。然而,单向LSTM 只能将上文的信息传递给下文,没有来自下文的内容反馈,这显然是不够的。因而,研究者们通过采用双向长短时记忆网络(Bi-directional Long Short-Term Memory Network,BiLSTM)来同时计算上下文对一个词的影响。
2.3 条件随机场
条件随机场 (Conditional Random Field,CRF) 是一种统计建模方法。它结合了最大熵模型(Maximum Entropy Markov Model,MEMM)和隐马尔可夫模型(Hidden Markov Model,HMM)的优点,形成了无向图模型,并可以考虑上下文信息,如图 4 所示。在一些需要预测样本之间依赖关系的应用场景中,CRF 是一种很好的方法。因而,CRF 被广泛应用于文本的序列标注任务中。
图 4 条件随机场结构示意图
2.4 注意力机制
注意力机制(Attention Mechanism)能实现信息处理资源的高效分配,是专家仿照人类注意力机制而提出的一种模型。例如,当一种场景进入人类视野时,人往往会先关注场景中的重点,如动态的点或者突兀的颜色等,其余的静态场景会暂行性忽略,在文本处理的场景中亦是如此。当程序处理到句子某个组分时,会着重考虑与该组分比较相关的其他组分,而暂时性忽略与其相关性较低甚至不相关的组分。
注意力机制最先被应用于图像处理领域,并取得了重要突破。近些年,越来越多的学者将其应 用 于机器翻译领域,同样取得了很好效果。Google 公司在“Attention is all you need”中提出的transformer 模型更是摒弃了传统的 CNN、RNN 方法,完全采用注意力机制对模型进行训练,使算法准确率有了大幅提升。此后,大量基于注意力机制的自然语言处理模型开始涌现,实验结果表明注意力机制可以有效提高关系抽取效果。
3 中医古籍文言文信息抽取的技术路线
目前,文本信息抽取方法可以分为流水线抽取和联合抽取。流水线抽取将任务分为两步:先进行实体抽取;然后基于实体抽取的结果进行关系抽取。联合抽取将任务看作一个整体,采用端到端的思想输入文本,输出“实体 - 关系 - 实体”三元组。
3.1 流水线抽取方法
3.1.1 文本的实体抽取模型
一般情况下,我们将实体抽取任务看作一个序列标注的任务。而当前在文本的序列标注领域,通常采用 BERT-BiLSTM-CRF 这样的网络结构。大量研究证明,这种网络结构与其他的模型相比能取得更好的抽取效果。在 BERT-BiLSTM-CRF 这样的网络结构中,各组件分别起到下述作用。
(1)BERT 作为编码器(Encoder)。它能把原始文本中的字或词,以及标点符号编码成含有丰富而又相对更加准确的语义信息向量。BERT 也能根据文本上下文信息,有效解决一词多义现象。
(2)BiLSTM 能进一步学习文本序列中的上下文信息。具体而言,LSTM 能有效改善文本序列中的“长期依赖”问题,而双向的结构使其能同时学习上下文信息,因而在序列标注任务中能取得更好效果。
(3)CRF 可以有效学习序列标签之间的依赖关系。在文本实体抽取任务中,存在多种标注方案,以最基础的 BIO 方案为例。在 BIO 方案中,B 表示实体的开头,I 表示实体中除了开头之外其他组分, O 则表示句子中不属于任意实体部分。在这一标注方案中,相邻的两个字或词之间可能会产生 BB、II、OO、BI、IB、BO、IO 和 OI 几种标注结果。显然,OI 这种标注结果是错误的。CRF 能有效避免这种不合理标注结果的出现。
中医古籍文本的实体抽取任务本质上与普通文本的实体抽取任务相似,关键是需要选择一种基于文言文的文本预训练模型,如上文提到的GuwenBERT。同时,也需要针对具体的语料设计相应的序列标注方案。比如,上文提到的有关“生化汤”的文本实例,其中包含的实体类型有“方剂”“中药材”和“功效”,我们可以将这三种实体类别分别用 FJ、ZYC 和 GX 来表示,那么序列标注结果就可能有 B-FJ、I-FJ、B-ZYC、I-ZYC、B-GX、I-GX和 O;或者可以针对每类实体构建一个序列标注的分类器来进行训练。
3.1.2 实体关系分类模型
在流水线抽取方法的实体关系分类模型中,获取到实体之后,针对每两个实体进行关系分类。实体关系分类一般属于多分类任务,即有一个以上的实体关系类别。上文举的“生化汤”例子中包含了“君”“臣”“使”“佐”和“功效”这五种关系类别;同时,像“黑姜”和“活血化瘀”这两个实体之间不具备上述提到的几种关系,它们之间的关系可以定义为“空”或者“无”。那么,候选实体间关系类别一共有六种,因此需要构建一个六分类器。
然而,这种分类方法的数据是严重不平衡的。同时,关系分类结果也严重依赖实体抽取结果,如果实体抽取出现错误,那么错误必然也会累积到关系分类中,这会进一步降低模型效果。
3.2 联合抽取方法
由于文本信息抽取的流水线方法存在一定缺陷,近年来大量的研究学者尝试将实体抽取与关系抽取任务进行联合建模。研究表明,这种方法相对于流水线抽取方法能取得更优效果。
2016 年,Miwa 等提出一种端到端模型,其使用了 LSTM 与 tree-LSTM 结构,基于词序和依存树结构信息来同时抽取实体及其关系。该模型被认为是实体与关系联合抽取的开山之作,后续很多研究都会与其进行比较。2017 年,Zheng 等将实体关系联合抽取看作一个序列标注任务,并且取得了非常好的效果。在之前联合抽取模型中,虽然通过共享参数等方法将两个任务整合到同一个模型中,但这两个任务实际上仍然是两个分离过程。Zheng 等设计了一种新颖的同时包含实体信息与实体间关系信息的标注方案,很好地将两个任务融合在一起。在这种标注方案中,增加了实体间关系角色。以上述“生化汤”的文本来举例。如“生化汤”与“当归”这两个实体存在的关系为“生化汤 - 君 - 当归”,那么“生化汤”的标注结果就是“B-JUN-0 I-JUN-0 I-JUN-0”“当归” , 的标注结果是“B-Jun-1 I-Jun-1”。其中,Jun 表示实体关系类别为“君”,0 和 1 则表示这两个实体在这个关系中的角色,即它们在三元组中的位置。这种方法也存在一个很明显缺陷,就是没有考虑实体关系重叠问题。例如,在描述“生化汤”文本中,“生化汤”这一实体与其他六个实体都存在关系,但是这种标注方案只能标注出它与其中一种实体的关系。
2018 年,Bekoulis 等将实体与关系抽取看作是一个“多头选择”问题,来解决之前联合抽取模型中存在的关系重叠问题。该方法不再将关系抽取当作一个关系之间互斥的多分类任务,而是看作每个关系之间相互独立的二分类任务,从而判断某一实体是否与其他实体存在多种关系。后续有很多研究人员在这一领域做了大量创新性工作。比如,Li 等将实体关系联合抽取任务作为一个多轮问答问题来处理,即每种实体和每种关系都用一个问答模板来进行刻画,根据这些模板化问题来从上下文中抽取实体和关系。例如,下面给出一个简单的问答模板。
问:文本中提到了哪种方剂?
答:生化汤
问:生化汤的“君”是什么中药材?
答:当归
问:生化汤的功效是什么?
答:活血化瘀
此外,研究学者从实际问题出发,探索出许多新颖标注方案,尝试解决实体和关系抽取中的关系重叠等问题。
4 中医古籍文言文信息抽取所面临的挑战 结束语
现如今,虽然文本信息抽取领域研究如火如荼,但是针对中医古籍研究和相关的资源相对较少。文言文和白话文之间存在较大差距,同时数据集等相关公开资源短缺也在一定程度上限制了这一研究领域发展。目前在面向中医古籍的文言文信息抽取任务中,主要存在以下问题。
4.1 源语言语义理解不足
古代文言文是一种意合的语言,其篇章的省略、指代称谓等语言现象较为复杂;特别是由于古籍横跨多个中国朝代,不同朝代的古籍之间也存在不同的语言表述,甚至发生谬误。如临床常用的穴位“三阴交”,在唐代以前的文献中是足内踝上三寸的“足太阴交”穴位置,是对《灵枢·经脉》谓足厥阴经脉“上踝八寸,交出太阴之后”的误判,源流可靠的“三阴交”穴在宋初戛然而止;而从宋代至今,高频度使用的却是被误解或异化的“三阴交”穴(朱兵《系统针灸学》)。此外,传统模型在识别和利用各个概念实体之间蕴含的语义关系上能力较差,这些都导致在信息提取过程中对源语言的语义理解出现偏差,进一步导致临床运用上的错误。同时,像“症状”“功效”这类实体或短语,表达起来非常灵活,同样的意思在文言文语境中存在多种不同表达方式,这也给中医古籍的信息抽取带来了挑战。
4.2 领域内标注信息质量及数量不足
虽然同为汉语,但文言文和白话文在词语表述、语法构成等方面均不相同,是汉语言跨时空、跨语境的表示方式,因此在数据累计上,并无过多可以复用的内容。此外,中医古籍领域作为具备独特语言学特性的书面文献,其行文中蕴含了较多概念实体,各实体间的关系体现出更为复杂的特征,因此增加了信息抽取难度。穴位名称的时代变迁即为其中一例,现存最早的敦煌卷子穴位图残存的 69 个穴位中,与传世文献同名同位的穴位仅有 11 个,异名同位的穴位有 19 个,其他均为同名异位(14 个)、异名异位(11 个)和存疑待考的穴位。即使在现代教材中,也会出现同一穴位不同名称,如“绝骨”又名“悬钟”,而在症状描述方面则存在更多差异。基于以上问题,若采用众包方式对数据进行标注,会出现由于对中医领域知识的认知不足,导致标注数据质量参差不齐的情况。目前能熟练并理解中医古籍材料的研究员较为稀缺,因此针对文言文这种特殊汉语表述,缺少一定量标注数据,给模型训练带来了很大困难。
5 结束语
本文介绍了中医古籍信息抽取的主要任务和挑战,同时阐述了中医古籍信息抽取中实体抽取和实体关系抽取这两项主要任务的基本情况及发展现状。
总而言之,面向中医古籍的信息抽取是文本信息抽取的一部分。中医古籍信息抽取技术的发展在很大程度上也依托于普通文本信息抽取技术发展。但是基于中医古籍文本的特殊性,需要开展大量针对性工作,包括训练数据的获取,以及算法的创新等。相信随着这一领域研究的深入,这项任务也会得到更进一步的发展。
来源: 选自《中国人工智能学会通讯》
