
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 陈林孝
陈林孝 
你知道吗,DeepSeek- V3、GPT、豆包这些大语言模型的“底层架构”是同一个东西,叫“Transformer架构”。你每天跟大语言模型打交道,却不知道它们为什么如此强大,又总是出现幻觉。那你就要学学Transformer架构!
Transformer有变压器、转换器的意思,但它有个更响亮的译名:变形金刚!(不是胡说,有专业书籍就这样翻译。)
变形金刚能从汽车转换成机器人,大语言模型把它阅读的海量文章转化成新文章:它们都是重组已有的零件。
现在会写作、画画的AI(生成式人工智能,AIGC)跟以前会刷脸、下棋的AI不一样,但它们用的都是“深度学习”。
什么是深度学习?
深度学习是当前AI的主流方法,也是机器学习的一种。机器学习有点像教鹦鹉说话:客人走进来时,给它示范说“你好”,再根据鹦鹉的发音偏差,多次调整,直到鹦鹉学会。有时为了强化效果,还要给鹦鹉不同程度的奖励。
用专业的话讲,客人走进来是给鹦鹉的“输入”,说“你好”是鹦鹉的输出,人工给的示范叫“已标注数据”,反复调整的过程叫“训练”,了解鹦鹉的水平叫“测试”。一般要把搜集到的数据分成训练集(例题)和测试集(试题)。AI相当于有大量参数的函数,机器学习的本质是通过刷例题,不断调整这些参数,让偏差最小。(没错,AI是一只“巨鹦”。)
深度学习的“深”,是指输入和输出之间隔了多层神经网络。此外,深度学习让AI自己总结出特征(比如人脸特征),不用人工提取特征,实现了降本增效。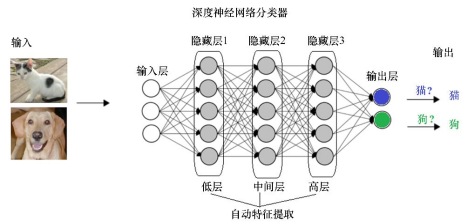
对于神经网络,每个神经元(图中的圆圈)包含多个需要调整的参数。为了给“鹦鹉”纠偏,就要从输出开始,反向逐层更新参数,这就是“反向传播算法”。
懂了深度学习,就懂了当下大多数的AI。我们常说的“大模型”,就是训练数据量(给AI刷的题)、参数量非常庞大的深度学习模型。大语言模型(LLM)是针对语言问题的大模型。
“变形金刚”是怎样炼成的?
细讲Transformer的内在构造之前,先说说怎么训练。
回到鹦鹉学舌的例子:如果教鹦鹉说长篇大论,就要给它提供海量数据。如果全靠人工示范,岂不是很累人?能不能让鹦鹉直接观察人类的对话,自己琢磨出来呢?但如果全靠鹦鹉自己总结,它会不会学一些废话、脏话,导致“已读乱回”呢?“预训练+监督微调”训练方法解决了这个问题。
说话的本质是蹦出一个又一个词或标点。所以,每次只要根据前文预测下一个词(或标点),反复进行这一过程,就实现了文字生成(也就是“找出词汇表里接下来出现概率最大的词”)。预训练阶段的作用是投入海量文章,让AI掌握预测下一个词的能力。而监督微调阶段是凭借人类乃至专家标注的数据,让AI能正确回答问题,而且安全、可控。这实现了训练成本与效果的平衡,极大降低了对人工标注数据的依赖。
Transformer架构可以分为输入、编码器、解码器、输出。
如果说编码器的功能是“阅读理解”,能理清每个词的语义和上下文关系,解码器的功能则是“写作文”,根据要求产出新的内容。输入和编码器的关键词是“一叶知秋”(熔全文铸一“词”),解码器和输出的关键词是“厚积薄发”(基于全文猜一词)。整个架构都讲求“既见树木,又见森林”。
基本过程是:文章完成分词后,经过“输入”部分的处理,进入“编码器”:通过多头自注意力机制,把对词的旧表示变成富含上下文复杂信息的新表示。词的新表示进入解码器,开始训练模型的续写能力。为防止“抄作业”,通过“掩码”让模型只看到已经生成的词,看不到后面的内容。再运用编码器-解码器注意力机制,充分利用编码器的阅读理解成果,最终得出概率最高的词。完整的新内容重新输入解码器,直到生成完毕。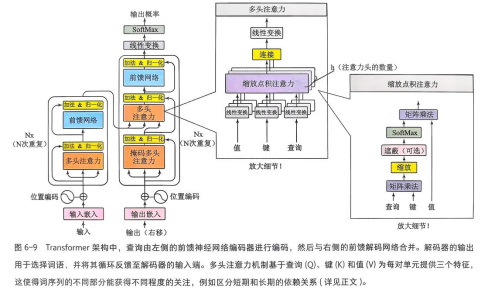
图源:[美]特伦斯·谢诺夫斯基《大语言模型:新一轮智能革命的核心驱动力》
输入:找车位,加序号
想把汽车变成机器人,要造好每个“零件”。词元(Token)就是文章的零件,是模型能处理的最基本的词或标点。想得到词元就要“分词”:对搜集到的文章,把废话去掉、拆分出句子、分割出词元。但分词还不够,要体现词的语义,这涉及三方面:词本身的含义、词在句子中的位置,还有上下文中词与其他词的相关性。
在词典里,词义总是用近义词解释的。能不能把语义上的远近关系,转化为几何空间里点的距离呢?
可以构建一个“停车场”,把词当成小车,停在适当的位置上,让它们的距离体现词义的远近:这叫做“嵌入”。立体(三维)车库一定比平地(二维)车库能停更多的车,而且车之间的距离会更加多样,也就是反映更丰富的词义。因此,“停车场”的维数一般比较高。我们把车位的坐标——如(第二列,第三行)——称为“向量”。嵌入就是通过训练,让每个词元都停进最适当的车位的过程。
此时,词元还是一堆碎片,需要引进词在句中的位置。好比“我看见”和“看见我”,意思大不一样。把位置编码也用向量表示,两个向量相加,就得到词元的表示啦!
编码器:词元说,关系密切的词我才多注意
刚才讲过,语义还包括词与文中其他词的相关性。举个例子:“猫坐在毛毯上,因为它很暖和。”我们怎么让模型明白“它”指“毛毯”呢?而且不能借助人工提示,要它自己发现!(AI表示:我太难了。)
说到相关性,可以联想到网页搜索:输入搜索关键词,和文章标题相关性最高的文章会排在前面,这涉及搜索关键词、文章的标题和文章内容。能不能实现“词元搜索词元”,也形成这样的相关性排序呢?
自注意力机制就做到了!
如果想把空间中的点“平移”到另一处,数学上相当于把点的坐标向量乘一个“矩阵”。我们可以设置三个不同的矩阵,里面的参数一开始是随机的,后续通过训练加以确定。让这三个矩阵分别乘已得到的词元向量,每个词就有了三个新向量:Q向量、K向量、V向量。Q向量表示查询的关键词,K向量代表词的“身份证”,V向量表示词义。在“输入”阶段,我们用点之间的距离反映词义的远近。现在,我们怎样表示词与词的相关性呢?
在数学上,向量不仅表示坐标,还表示从坐标系原点指向该点的有向线段。数学家定义了一种向量之间的乘法:“点积”。运算的结果是一个数,而不是向量。如果两个向量夹角较小,它们的点积就比较小:我们能用这种方式揭示词与词的相关性。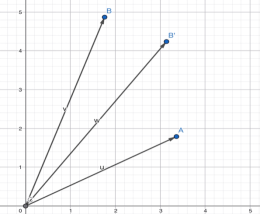
向量OA和OB的点积,大于向量OA和OB’的点积(OB和OB’等长)
因此,我们想挨个了解每个词(比如词A)和词汇表里所有词的相关程度,就是计算词A的Q向量(搜索关键词)和所有词汇的K向量(词的身份证)的点积。
为了保证训练过程的稳定性,我们把得到的所有点积进行“缩放”(除以K向量维数的平方根),得到“注意力分数”,再对所有注意力分数计算Softmax函数,词汇表的所有词就有了对应的概率(Softmax(x)通过指数函数保证分子大于零,再用该得数除以所有得数的总和,实现概率总和等于1)。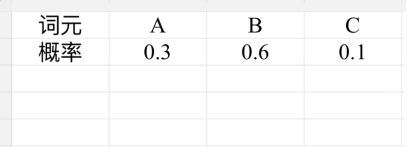
针对词元A,每个词元的注意力权重(眼熟吗?概率分布!)
这个表格叫做“注意力权重”,它意味着词A与词汇表的每个词分别有多少相关性,对不同的词分配多少注意力。回到“猫坐在毛毯上,因为它很暖和”的例子,通过学习,模型会总结出“它”与“毛毯”有最高的相关性,从而分配更多的注意力。
但用于生成的“零件”还没有成型。我们要继续优化词元的表示(新向量),让每个词元都包含上下文的信息。这样在重组文字的时候,能做到兼顾全局,而不是驴唇不对马嘴。
我们漏了什么呢?已经用了Q向量和K向量,表示词义的V向量还没用到!
对于词A,我们想把所有词整合到它的表示中,而且相关性越高的词,在最终表示中占比越大。而表达相关性的正是“注意力权重”,所以只要把每个词的权重乘以自身的V向量,再求和,就得到了全新的向量:它不仅包含词A的信息,还包括全文其他词的信息,并对相关性高的词分配了更多注意力。
可以用“一叶知秋”概括编码器的自注意力机制:最终输出还是词元的向量,但它蕴含了全文的信息。好比叶子经过春风秋雨,变得斑驳重重,叶片上的每个痕迹都关联着一场或大或小的雨,最终承载了整个秋天。
为了多次执行自注意力机制,捕获更复杂的信息,可以把输入编码器的词元向量先分成几段,例如把6维向量(a1,a2,a3,a4,a5,a6)分成2个3维向量(a1,a2,a3)和(a4,a5,a6),分两头进行刚才的过程,最后再拼接成6维向量。这种分头进行的注意力机制叫“多头注意力机制”(案例只是便于理解,实际维数大得多)。
还记得深度学习的神经网络吗?为了保证训练效果,先处理自注意力机制的输出向量(进行残差连接和层归一化),再输送给神经网络。神经网络像“高压输电”,先把向量的维数升高,使模型能捕获更复杂的特征,然后经过非线性的ReLU函数,再转化成低维的向量(就像低压电便于使用)。如果没有非线性的ReLU函数,这个变换只能将直线变成直线,不能模拟复杂的曲线(非线性意思就是非直线),会影响模型应对新问题的能力。
以上全过程要反复进行n次,得到“编码器最终输出”,才进入负责生成的解码器。
解码器:别看答案!看清要求!
喂给解码器的,一开始是编码器的最终输出,但此后就是已经生成的文字,也就是一串有顺序的词元。解码器的结构跟编码器有相似之处,首先是嵌入、引入位置编码,不同之处是中间阶段为掩码自注意力和编码器-解码器注意力过程,最后一样是神经网络——全流程也要循环n次。
所以,我们就说说掩码自注意力和编码器-解码器注意力。
生成文字本质上是蹦出一个又一个词元,应该只根据已生成的内容来续写,而不是预先知道后面的内容。比如用于训练的文章有一句“你好吗”,如果模型能看到“你好”后面的词,就会直接给“你好”续写“吗”,这不是抄答案吗?为了遮掩答案,引进了“掩码”。在编译器阶段,词元对相关性高的词元多加注意;在解码器阶段,我们希望除此之外,词元“不注意”还没生成的词。这要通过词元的序号进行“掩码”。
掩码自注意力机制的开头依然是产生Q向量、K向量、V向量,并计算出对于词A,所有词的“注意力分数”。对任何一个词元,把其后所有词元的注意力分数加上一个非常大的负数,这些词元的注意力权重就约等于0。这能保证模型不“偷看”答案,学会续写。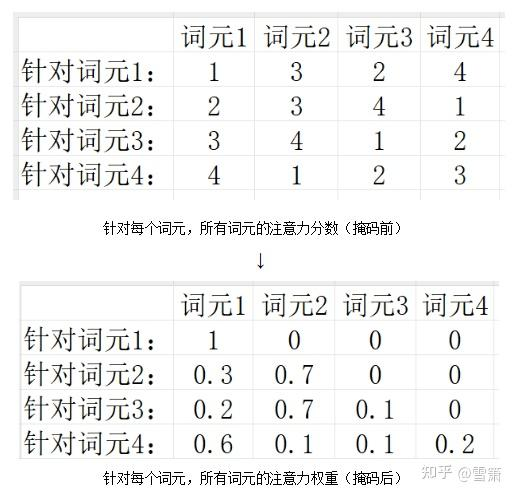
回头想想,编码器辛辛苦苦把文章和词元的语义浓缩成了精华,只给解码器投喂一次是不是很浪费?这样解码器不能参考编码器的阅读理解的成果,也很难做到上下文语义统一(就是抛开阅读谈写作)。
编码器-解码器注意力过程就是要解码器回顾编码器的最终输出。还是按自注意力机制的思路进行:新生成的内容作为Q向量(查询关键词),编码器的最终输出作为K向量(身份证)和V向量(含义)。用同样的方式计算注意力权重(体现的是生成内容和阅读理解成果之间的匹配程度),然后再和V向量加权求和,得到新向量。
你可能会疑惑:为什么V向量是编码器的最终输出,而不是来自解码器?因为注意力权重只是体现了相关程度,只有让编码器的最终输出作为V向量,才是真正引入编码器的成果。
输出:回到词汇表,求概率
你还记得最终输出应该是什么吗?
带概率的词汇表!所以不论解码器输出的维数是多少,都要通过线性层将维数转化为词汇量的数目。线性层的参数经过训练,对预测准确度和效率也有重要影响。此时线性层的输出类似于注意力分数,还要经过Softmax函数,就真正转化成了概率。只要找到概率最高的词元,就大功告成!
看完Transformer架构的逐步拆解,相信你也会感到“变形金刚”不好当!值得注意的是,基于Transformer架构的大语言模型,本质是基于给它学习的海量文章,预测最有可能出现的下一个词元。因此,这些文章的语言习惯和思想倾向会影响AI的输出。而且预测基于概率,这促使生成的文章符合大多数人的说法,往往显得四平八稳、缺乏独特性。AIGC领域还有一个未经理论验证的“规模定律”:训练数据量和参数量越庞大,效果越好。学懂了原理,这也不难理解:如果AI学习的文章风格丰富多样,其掌握的文风也就更丰富,能力就越强大,正所谓“转益多师是汝师”。
最近,OpenAI研究了大语言模型的“幻觉”现象(一本正经地胡说八道)。研究认为,这是因为一直在训练AI正确预测下一个词,而且奖励机制只鼓励流畅续写,没有鼓励“不知道就承认”,导致即使AI不了解相关事实,依然基于训练数据写出概率最高的答案(“不懂就蒙”)。
只有深入了解LLM的底层逻辑,才能真正理解它的强大和弱点,理解我们身处的时代。与其对AI感到恐慌,不如反思自己:我输出的内容比AI独特吗?我是同样不懂装懂,还是努力扩展认知?认识AI、超越AI,才是应对AI时代最好的解药。
注:文中对术语作了简化,Q向量即查询向量,K向量即键向量,V向量即值向量。
参考文献:
[1]谢雪葵.AI大模型开发之路:从入门到实践[M].北京:中国水利水电出版社,2024.7.
[2]刘云浩.具身智能[M].北京:中信出版社,2025.1.
[3](美)特伦斯·谢诺夫斯基著,李梦佳译.大语言模型:新一轮智能革命的核心驱动力[M].北京:中信出版社,2025.7.
[4]royceshao.3万字长文!深度解析大语言模型LLM原理[EB/OL].腾讯技术工程,2025-08-01[2025-09-14].https://mp.weixin.qq.com/s/JHdZxD-M0TvI-SGO0iehyA.
[5]huaxing.LLM学习笔记:最好的学习方法是带着问题去寻找答案[EB/OL].腾讯技术工程,2025-05-12[2025-09-14].https://mp.weixin.qq.com/s/T7aD9diSNymHhv68FSaSZA.
[6]LAOyu111.现代AI的架构之父:从浅入深讲解Transformer架构,非常详细,附带数据图![EB/OL].AsperAI,2025-07-22[2025-09-14].https://mp.weixin.qq.com/s/dkOMxIXCHAJvWUXUmzjVVA.
[7]Kalai,A.T. , Nachum,O. , Vempala,S.S., Zhang.E. Why Language Models Hallucinate[EB/OL].2025-09-04/[2025-09-14].https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
部分图片来自网络
来源: 陈林孝
