
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 陈林孝
陈林孝 
你是否也曾惊叹于AI绘画的神奇?只需输入一段文字描述,如“一位宇航员在星空下骑马”,一幅充满想象力、细节丰富的画作很快便跃然屏上。

今天,我们就来看看AI是如何“学会”画画的。
首先要澄清一个误解:AI绘画并非从海量图片中剪切、拼接出符合你描述的片段。相反,它更像一个经过长期严格艺术训练的“数字画家”。这个画家的学习过程,我们称之为 “模型训练”。
想象一下,如果你想教一个外星人什么是“猫”,你会怎么做?你可能会给它看上百万张猫的图片,并不断告诉它:“这是猫”。
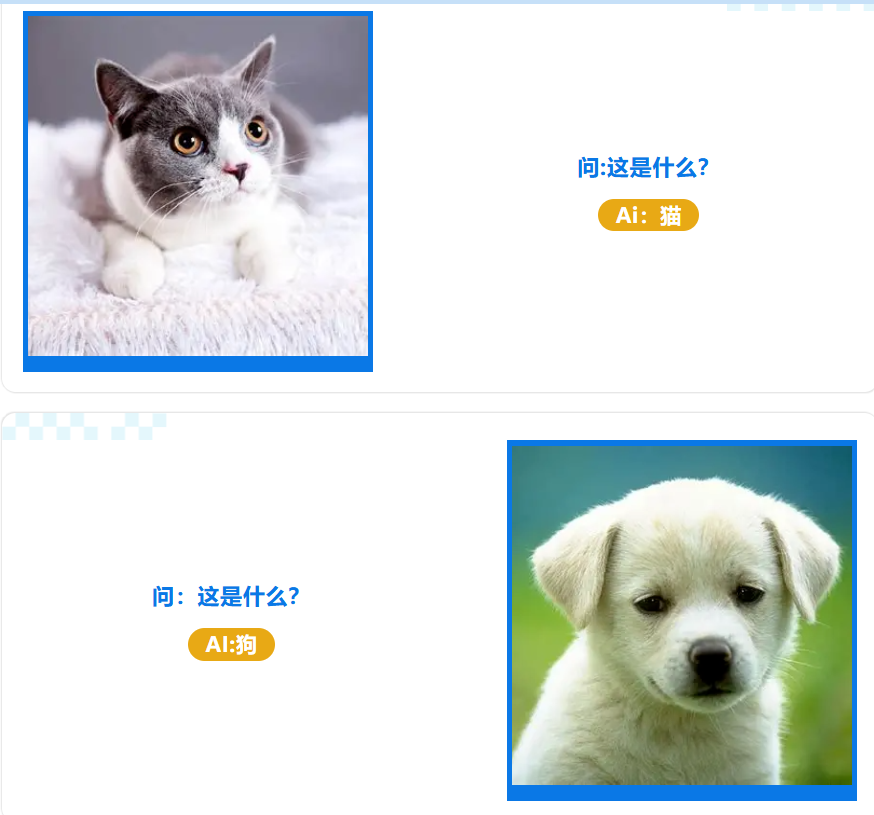
AI的学习过程与此类似。研究人员用一个包含了数十亿对 “图片-文字描述” 的数据集来训练模型。比如,同时给AI看一张猫的图片和“一只可爱的灰猫”这段文字。经过无数次这样的学习,AI逐渐在复杂的神经网络中建立了文字特征和视觉特征之间的深层联系。
它慢慢理解了“猫”这个词可能对应着毛茸茸的躯体、尖耳朵、胡须等像素规律;而“灰色”则对应着特定的颜色和光影分布。这个过程让AI构建了一个极其庞大的“视觉概念字典”。
现在,我们的AI“画家”已经学富五车,但它是如何从零开始创作的呢?这就要提到当今主流文生图技术的核心引擎——扩散模型。我们可以用一个“还原照片”的比喻来理解:
假设我们有一张清晰的猫的图片。我们不断向这张图片中加入微小的随机噪点(就像老电视的雪花屏),一步一步地加,直到图片完全变成一团毫无意义的、灰度均匀的静态噪声。
扩散模型的核心任务,就是学习如何将这个过程逆转。它被训练去观察每一张“被不同程度破坏”的图片,并精确地预测出“上一步”噪点更少的样子应该是什么。它需要学会从混沌中识别出秩序,比如从一堆噪点中看出“这里似乎应该有个猫耳朵的轮廓”。
训练完成后,当我们想让AI作画时,我们首先给它一团完全随机的噪声(一张“白纸”或“画布上的混沌”)。然后,AI开始运用它学到的“去噪”本领,一步一步地、有依据地抹去噪声。
那么,文字描述如何起作用呢?
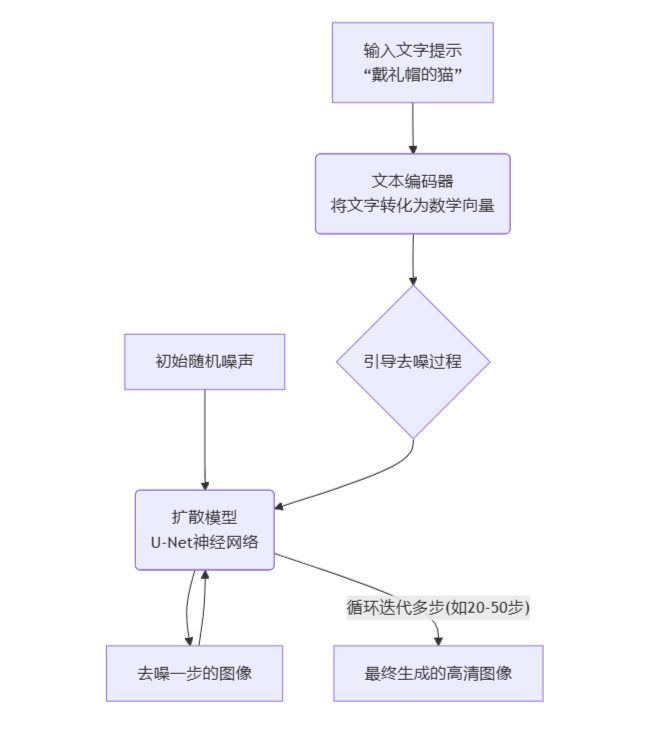
在去噪的每一步,AI都会“查阅”你输入的文字提示(比如“一只戴礼帽的猫”)。这个提示会通过一个文本编码器转换成数字指令,告诉AI:“在你去噪时,请确保最终结果趋向于一个‘戴礼帽的猫’的视觉特征。”
没有文字指导,去噪过程是随机的,可能会生成任何东西。有了文字指导,AI就会在去噪的每一步都朝着“戴礼帽的猫”这个目标进行修正和描绘,确保最终从混沌中浮现的,正是我们想要的图像。

简化流程图如下:
所以,AI文生图的原理可以概括为:
通过数十亿的“图片-文字”对,训练一个巨大的神经网络,让它学会文字和视觉特征的对应关系。
利用扩散模型,从一团完全随机的噪声开始,结合你的文字提示作为指导,一步步地、有指向性地去除噪声,最终“提炼”出一幅符合描述的全新图像。
它不是一个简单的图片检索器,而是一个真正理解了视觉元素构成规律的“创造性大脑”。从混沌到有序,从噪声到艺术,这既是技术的飞跃,也是人类向机器传递审美与想象力的一次尝试。
来源: 陈林孝
