
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 HyperAI超神经
HyperAI超神经 
语言智能体的长期目标是通过自身经验不断学习与优化,最终在复杂的真实世界任务中超越人类表现。然而在许多环境中,仅依靠经验数据并使用强化学习训练智能体仍面临巨大挑战,这些环境或缺乏可验证的奖励信号(如网页交互),或需要低效的长时程轨迹回放(如多轮工具使用)。因此,当前大多数智能体仍依赖专家数据的监督微调,但这种方法难以扩展,且泛化能力较差。
为克服这一局限,Meta 超级智能实验室、Meta FAIR、俄亥俄州立大学联合提出一种折中范式——「早期经验」(Early Experience),即智能体通过自身行为生成的交互数据,其中未来状态作为监督信号,而无需依赖奖励信号。这一范式为后续强化学习奠定了坚实基础,使其成为模仿学习与完全基于经验驱动的智能体之间一个切实可行的桥梁。
论文链接:https://go.hyper.ai/a8Zkn
最新 AI 论文:https://go.hyper.ai/hzChC
为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI超神经官网(hyper.ai)现已上线「最新论文」板块,每天都会更新 AI 前沿研究论文。以下是我们为大家推荐的 5 篇热门 AI 论文,一起来速览本周 AI 前沿成果吧 ⬇️
本周论文推荐
1. Less is More: Recursive Reasoning with Tiny Networks
本文提出了极简递归模型(Tiny Recursive Model, TRM),这是一种更为简洁的递归推理方法,其泛化能力显著优于 HRM,同时仅依赖一个仅含两层的微型神经网络。TRM 的参数量仅为 700 万,在 ARC-AGI-1 任务上达到 45% 的测试准确率,在 ARC-AGI-2 任务上达到 8%,均高于多数大型语言模型(如Deepseek R1、o3-mini),而参数量仅为这些模型的不足 0.01%。
论文链接:https://go.hyper.ai/bUZ6M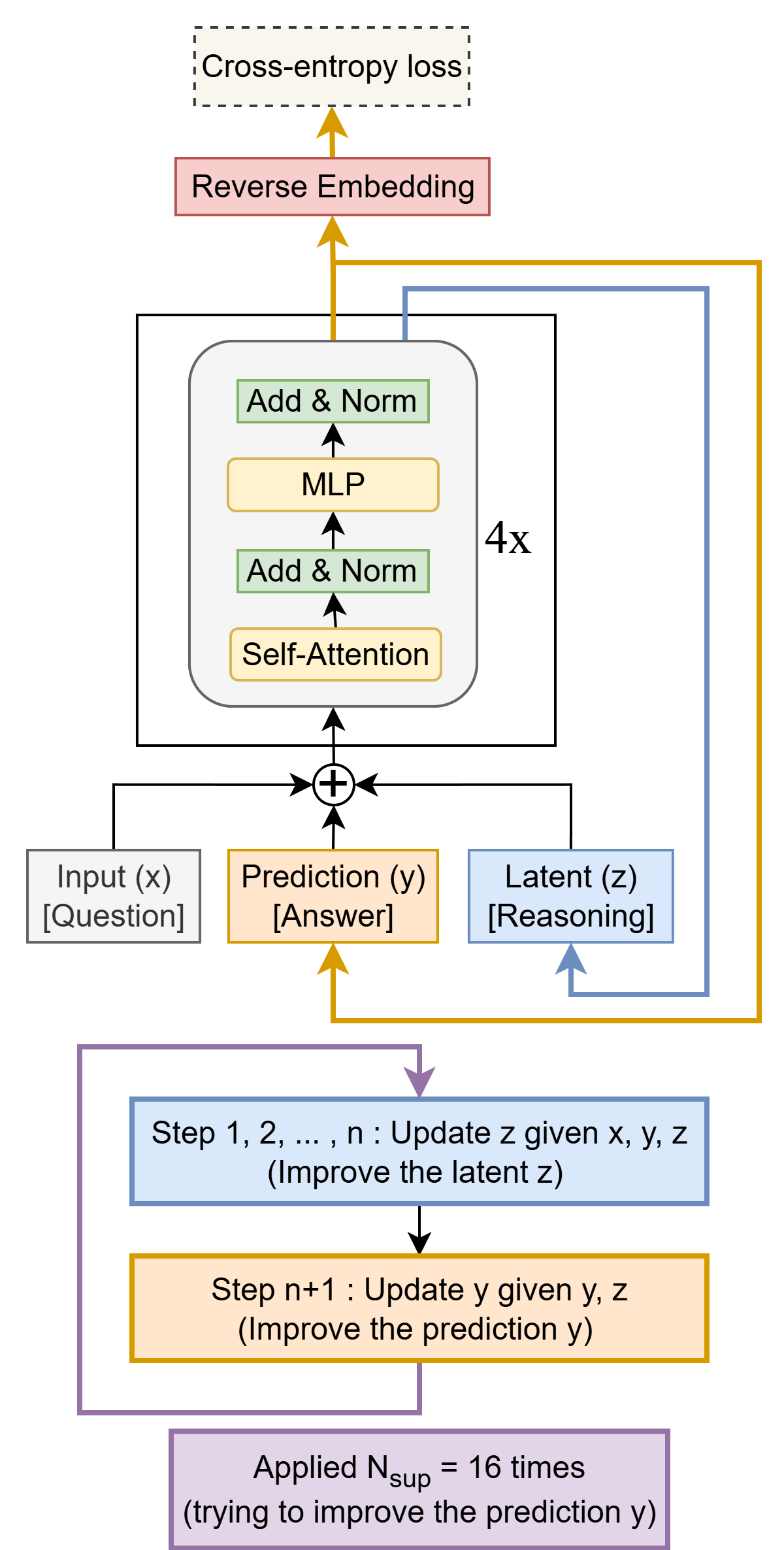
TRM 架构示意
2. PromptCoT 2.0: Scaling Prompt Synthesis for LLM Reasoning
本文提出了 PromptCoT 2.0——一种可扩展的框架,该框架用期望最大化(EM)迭代循环替代了人工设计的启发式规则,通过迭代优化推理过程来引导提示的构建。该方法生成的问题不仅更具挑战性,且在多样性上也优于以往的语料库。
论文链接:https://go.hyper.ai/jKAmy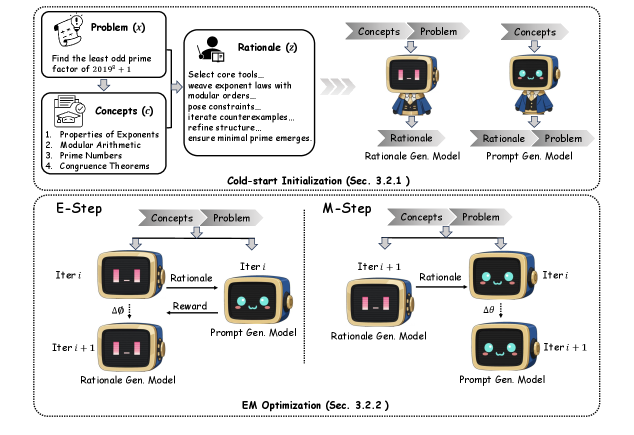
框架概述图
3. Looking to Learn: Token-wise Dynamic Gating for Low-Resource Vision-Language Modelling
本文提出一种轻量级解码器架构,包含三个关键设计:(1)基于 token 级别的动态门控机制,实现语言与视觉线索的自适应融合;(2)特征调制与通道注意力机制,以最大化有限视觉信息的利用效率;(3)辅助对比学习目标,用于提升视觉定位能力。
论文链接:https://go.hyper.ai/D178P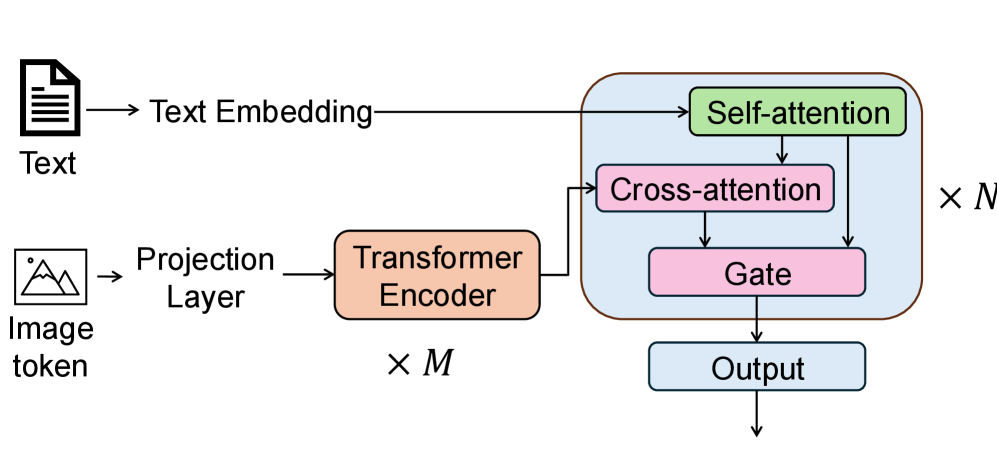
简化的双流架构
4. Agent Learning via Early Experience
当前大多数智能体仍依赖专家数据的监督微调,但这种方法难以扩展,且泛化能力较差。这一局限性源于专家示范的本质:它们仅涵盖有限的场景,导致智能体接触的环境多样性不足。为克服这一局限,本文提出一种折中范式——「早期经验」(early experience),即智能体通过自身行为生成的交互数据,其中未来状态作为监督信号,而无需依赖奖励信号。
论文链接:https://go.hyper.ai/a8Zkn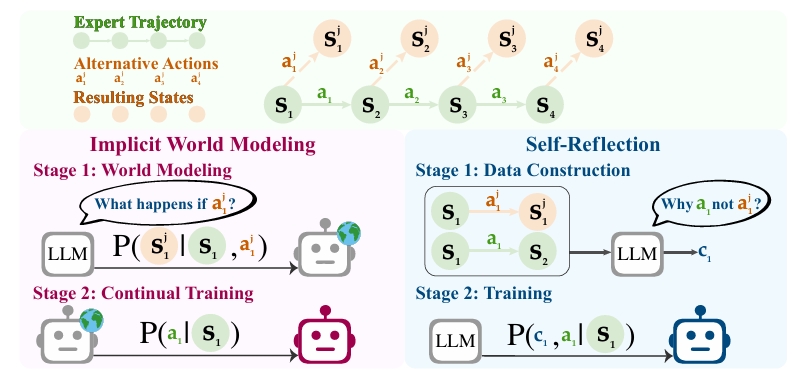
两种「早期经验」方法概述
5. Xception: Deep Learning with Depthwise Separable Convolutions
本文提出了一种受 Inception 启发的新颖深度卷积神经网络架构 Xception,其中 Inception 模块已被深度可分离卷积所替代。由于 Xception 架构与 Inception V3 具有相同数量的参数,性能提升并非由于模型容量的增加,而是因为更高效地利用了模型参数。
论文链接:https://go.hyper.ai/0BUt5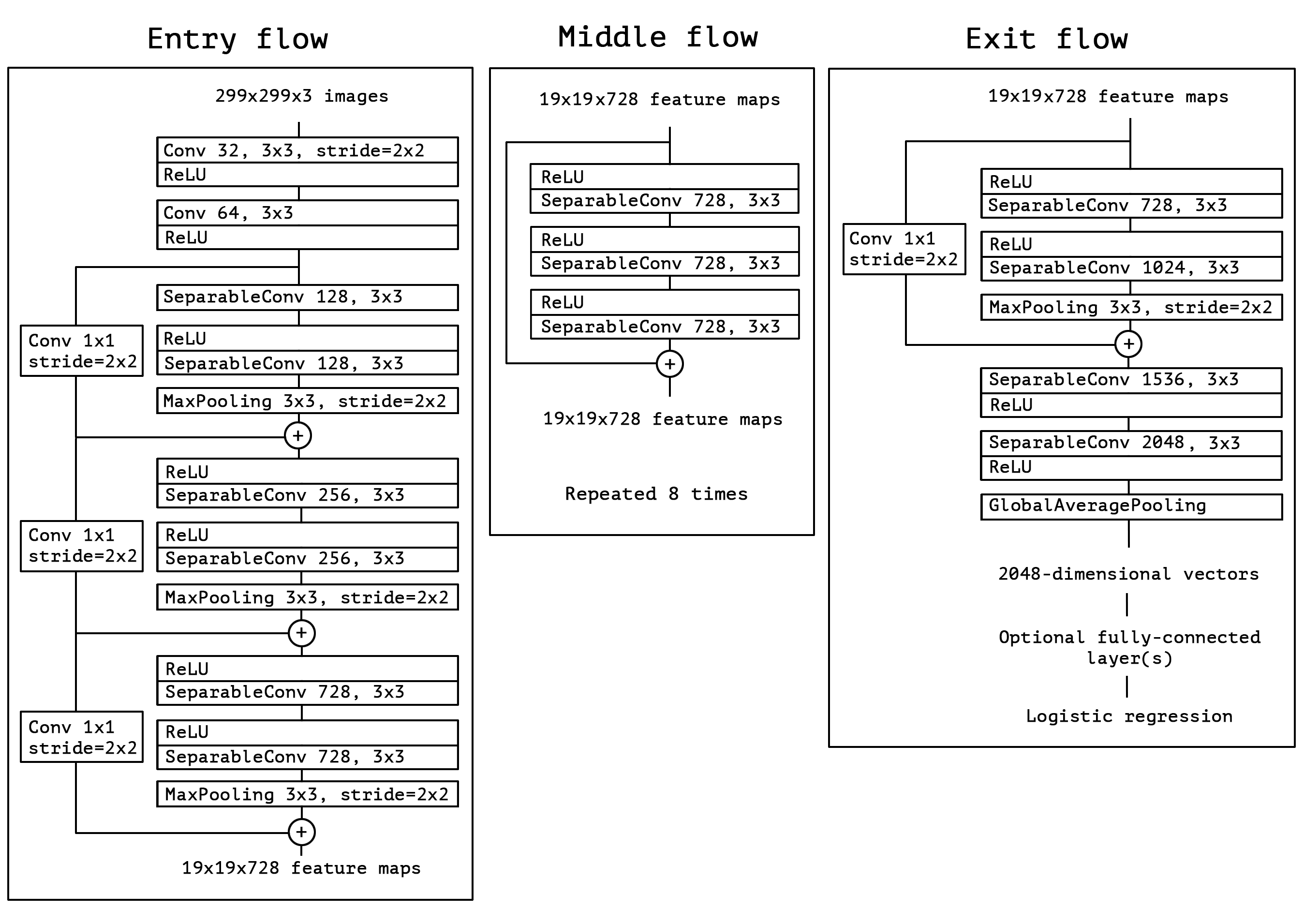
架构概述
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!
来源: HyperAI超神经
