
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普中国创作培育计划
科普中国创作培育计划 

让我们一起来拆解一下"ChatGPT"这个词。首先,"Chat"在英语中是指聊天。因此,一眼看过去,我们可以判断这是一个用于交流对话的工具。

接下来,我们来看看"GPT"代表什么含义。为了更好地理解这一点,我们需要了解这个大语言模型是如何工作的。可以简单地概括为:当你提供一段上文时,模型会根据这段上文生成接下来的一个词语。举个例子,假设你有这样一个句子:“我吃饭”,其中“我吃”作为已知的部分(即上文),模型将帮助你生成下一个词语,在这个例子中就是“饭”。因此,“ChatGPT”的核心功能就是根据给定的上文生成下一个词语。
那么,"GPT"中的"G"代表什么呢?答案是"Generative",意味着生成。这正是模型的工作方式——生成文本。现在我们明白了"G"的含义。

接下来,我们来探讨一下模型是如何生成词语的。当我们听到“不听老人言”的时候,自然而然就会想到下一句是“吃亏在眼前”。这种联想能力源于我们日常生活中的经验。同样地,大型语言模型也需要通过一个过程来获取类似的经验。这个过程就是我们所说的“训练”。

以"ChatGPT"为例,其强大的回答问题能力来自于对海量文本数据的训练。具体来说,它接受了45TB的语言资料训练。为了让大家对这个数字有个概念,举个例子,一个高清电影可能占几GB的空间,而1TB等于1024GB。这意味着45TB的数据非常庞大。但需要注意的是,这些数据全部由文字组成,并非视频或图片。假设我们在电脑记事本里写下10万个汉字,文件大小大约只有几百KB。相比之下,45TB的数据相当于大约450万套《四大名著》的文字内容。这是一个巨大的数字。
训练过程是自动进行的,无需人为干预,这也被称为“无监督学习”。在人工智能领域,机器学习分为三种类型:监督学习、无监督学习和强化学习。无监督学习的特点在于,系统能够自主学习,无需外部指导。
最后,你可能会好奇模型是如何利用这些文本数据进行训练的。显然,它并不能像人类那样阅读书籍。这个问题的答案涉及到了模型内部复杂的算法机制,这些机制使得模型能够分析并学习文本模式,从而实现文本生成的功能。
让我们通过一个简单的例子来解释如何训练大模型以生成文本。假设我们要训练模型识别并完成像“四大名著”这样的经典文学作品中的句子。在这个过程中,“范文”就像是学生写作时参考的优秀例文。例如,如果我们有一句范文“我吃饭”,并且我们希望模型在给定“我吃”的前提下能正确生成“饭”这个字,那么它是如何实现这一目标的呢?

首先,我们需要明白计算机处理信息的方式。计算机内部处理的所有信息本质上都是数字。因此,我们需要创建一个“编码表”,将每个字符映射到一个唯一的数字上。比如,可以设定“我”对应数字1,“吃”对应2,“饭”对应3,这只是举例说明,并非实际的编码规则。
有了编码表后,我们就可以开始构建模型的计算逻辑。为了生成“我吃饭”这句话中的“饭”,模型需要解决一个数学问题:找到一组合适的权重(系数),使得输入字符的数字表示与期望输出字符的数字表示之间的关系成立。用数学语言来说,就是寻找一组权重A和B,使得下面的方程成立: 1×A+2×B=3
这里的1、2和3分别代表“我”、“吃”和“饭”的编码值。这是一个二元一次方程,可能存在多个解。例如,A=1,B=1和A=0.5,B=1.25都能满足方程。然而,在训练模型时,关键在于选择那些能够产生预期结果(即“饭”)的解。
这些权重或系数被称为“参数”。对于像ChatGPT这样的大型语言模型而言,它拥有极其庞大的参数数量——约1750亿个参数。这意味着模型能够处理极其复杂的语言结构和模式。在训练过程中,模型通过调整这些参数来学习从给定的上文中预测下一个词的最佳方式。例如,当面对“我不吃草”这样的句子时,模型会根据类似的方程进行计算,以预测出正确的下一个词“草”。
简而言之,训练大模型就像解数学题一样,通过不断地调整参数来找到最佳解,从而生成符合语境的文本。
当我们谈论ChatGPT时,确实有很多人对其表现出的能力感到惊讶,甚至认为它仿佛拥有了人类般的思考和理解能力。这种感觉主要源于其庞大的参数规模——1750亿个参数,这让它能产生出与传统人工智能截然不同的效果。为了帮助理解这种差异,我们可以做一个简化的类比:尽管这种类比并不完全准确,但有助于说明问题。
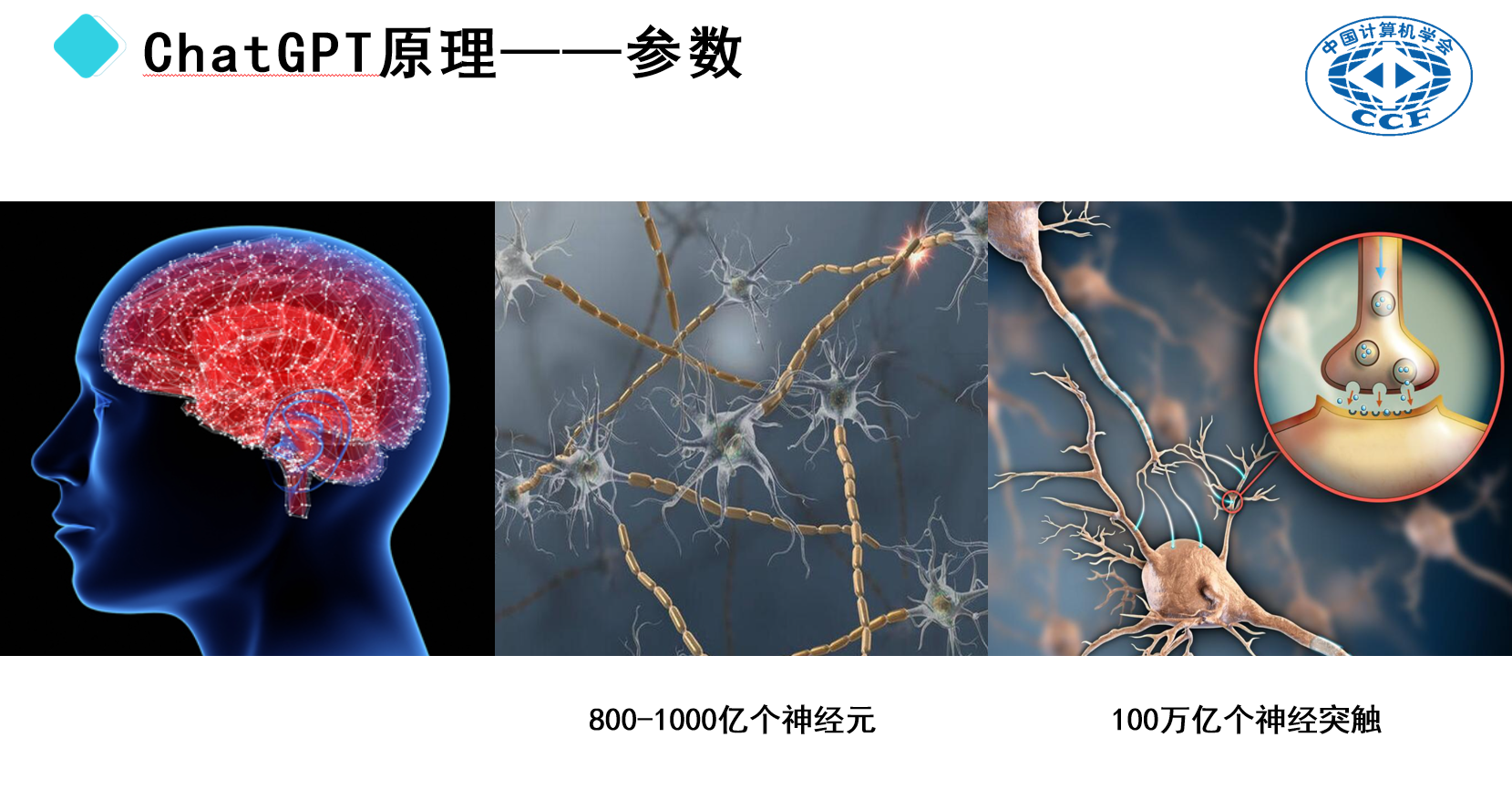
人脑包含大约800至1000亿个神经元,每个神经元又能与其他神经元通过数以千计的突触相连,共同构成了复杂的网络结构,支持着我们的认知过程。相比之下,ChatGPT的参数数量(1750亿)虽然巨大,但仍远不及人脑中突触的数量(约100万亿)。此外,参数与神经突触之间的功能差异也很大,因此,ChatGPT要达到人类智能水平还有很长的路要走。
尽管如此,随着技术的进步,一些大型语言模型已经拥有上万亿个参数,理论上讲,参数越多,模型的表现就越接近于“智能”。
值得注意的是,即使经过大量文本训练后,ChatGPT已经能处理一般性的语言问答任务,但在某些专业领域如金融、生物医药或信息技术等方面,它仍可能遇到挑战。这是因为这些领域的专业术语和表达方式与日常语言存在差异。为了提升ChatGPT在特定领域的表现,可以通过所谓的“微调”来对其进行进一步训练。这意味着在已有的通用模型基础上进行少量的调整,而不是从零开始重新训练整个模型。
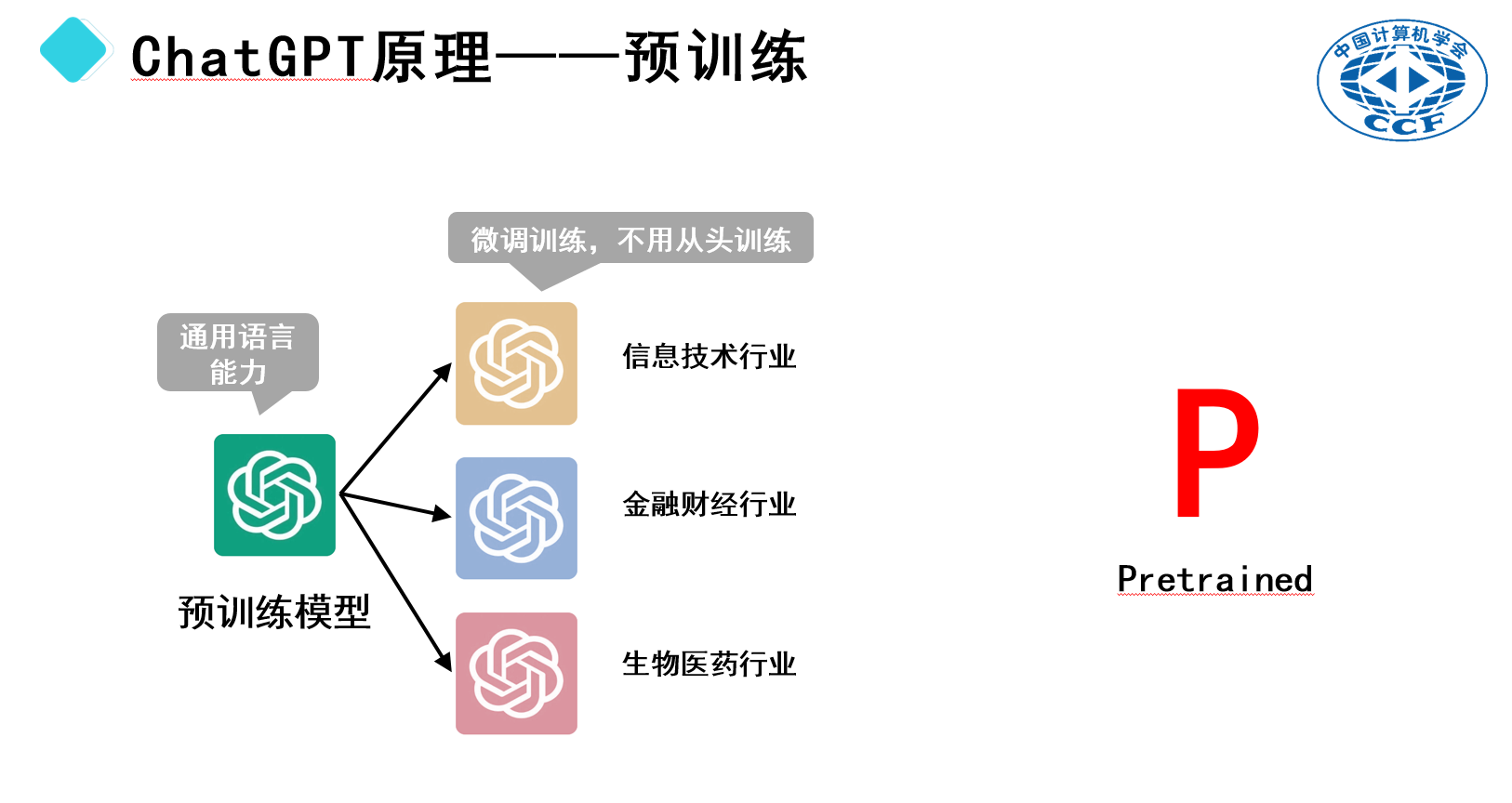
这种预先训练好的基础模型被称为“预训练模型”,英文中称为“pre-trained model”,简称“pre-train”。正如建楼时先打好地基一样,预训练模型为后续的特定任务提供了坚实的基础。
让我们回顾一下我们所经历的训练过程,这些训练显著提升了我们的大型语言模型的能力。然而,仍然存在一些问题影响着模型的表现。例如,在短语“我吃饭”中,我希望模型能够生成“饭”这个词。在这种情况下,“饭”的生成概率受到动词“吃”的强烈影响,而非主语“我”。将“我”替换为“你”,不应该改变最终的“饭”,但将动词从“吃”改为“喜欢”,就会显著改变预期的输出结果。

这说明了一个原则:上文内容对目标词的影响程度各不相同,通常来说,距离目标词越近的单词对其产生的影响越大。不过,并非总是如此,更复杂的例子展示了这一点。

以句子“我看到了隐藏在这个风度翩翩的绅士背后的令人不寒而栗的真相。”为例,当我们预测“真相”这个词时,最具影响力的因素并不是紧邻的“的”字,也不是“令人不寒而栗”,而是“看到”、“隐藏”、“背后”。这体现了所谓的“长程依赖”现象,即远离目标词的元素也可能对预测产生重大影响。
早期的聊天机器人和问答系统普遍面临着这一挑战,导致性能不佳。直到2017年,Google推出了Transformer架构,引入了注意力机制来解决这一难题。
注意力机制的工作原理类似于人类处理信息的方式,即专注于核心内容而忽略无关紧要的细节。以一张包含一只猫、草地和篱笆的图片为例。

大多数人会立刻将注意力集中在猫身上,即使它并非位于图片中心。我们的大脑自然而然地优先关注主要对象,正如Transformer中的注意力机制允许模型集中精力于句子中最关键的部分,如“看到”、“隐藏“、”背后”,以准确预测出“真相”。
综上所述,Transformer的注意力机制有效地解决了长程依赖问题,使模型能够专注于句子中的关键部分,从而生成更准确的结果。这一创新已成为开发先进语言模型的基础,包括ChatGPT在内的许多模型都采用了Transformer架构,其中的“T”即代表Transformer。

尽管Transformer极大地提升了大语言模型的能力,特别是在注意力机制方面,但仍存在不少挑战需要克服。例如,当你要求模型根据“朋友啊朋友”这一提示生成后续文本时,它可能会意外地产生”你可曾想起了我”之类的歌词内容,而不是你期望的回答:“你现在在哪里?”
这种情况的发生是因为模型接受过大规模语料库的训练,其中包含了歌词等内容,这些歌词在训练数据中可能更为频繁或突出,因此模型倾向于生成与之相关的回应。这显然不是我们想要的结果。为了解决这类问题,研究人员提出了一个新的解决方案:
具体来说,既然训练数据存在问题,研究者决定引入人为因素。他们找到一些人来准备一系列预定义的问题及其对应的答案,类似于企业内部使用的常见问题解答(FAQ)。这些精心设计的问答会被作为示例提供给ChatGPT进行训练。
这是一个涉及人为干预的过程,因为人们需要准备这些FAQ。这种方法被称为监督学习,这是我们了解到的机器学习领域的第二种类型,之前我们提到的是无监督学习。
即使使用监督学习解决了部分问题,但仍有一些挑战未被克服。比如,如果向模型提出“如何摧毁地球?”这样的问题,在早期阶段,ChatGPT或其他大型语言模型可能会详尽地列举出各种方法,包括具体的步骤,如果按照这些步骤操作,后果将不堪设想。
在这种情况下,我们发现这些模型在经过不断优化后,虽然能够提供高质量的回答,但却缺乏人类的价值观。对于正常的人来说,面对此类问题时,绝对不会给出实际的操作指南。为了解决这一问题,研究人员采取了一种新的策略:
他们邀请了一些人对ChatGPT的回答进行评分。如果模型给出了详细的步骤,即使回答准确,也会因其违反人类价值观而得到低分,比如一分或零分。相反,如果模型的回答是“我是一个人工智能,无法提供此类信息”,或是提倡保护地球的态度,即使没有直接回答问题,也会获得高分,比如满分五分。
随着时间的发展,研究人员不再依赖人力来进行评分,因为这样做成本较高。早期,OpenAI公司在某个非洲国家聘请了一些劳动力成本极低的人员来评估ChatGPT的回答是否符合人类价值观。这一做法后来被媒体曝光并受到了批评,称其为“血汗工厂”。随后,研究人员改进了技术,开发出一套自我评估系统,用于判断模型的回答是否符合人类的价值观。
通过引入人类的评价标准,使得ChatGPT能够进一步学习,这一过程被称为强化学习,这是机器学习领域的第三种主要学习方式。因此,我们可以看到,ChatGPT实际上已经综合运用了机器学习中的三种主流学习方法。
我们已探讨了ChatGPT的工作原理,现在让我们回到先前提出的问题:ChatGPT这样的大型语言模型是否真正理解语义?我的答案是“否”。这是因为这类模型是基于概率生成的,而非真正意义上的理解。
所谓的基于概率生成,意味着模型根据已读取的大量文本数据来预测下一个词或句子。例如,如果一个特定词语“吃”后通常跟着“饭”,那么模型在生成相应内容时也会倾向于使用这个词。这种倾向性是基于它在训练数据中观察到的模式,本质上是一种概率计算,而非真正的理解。
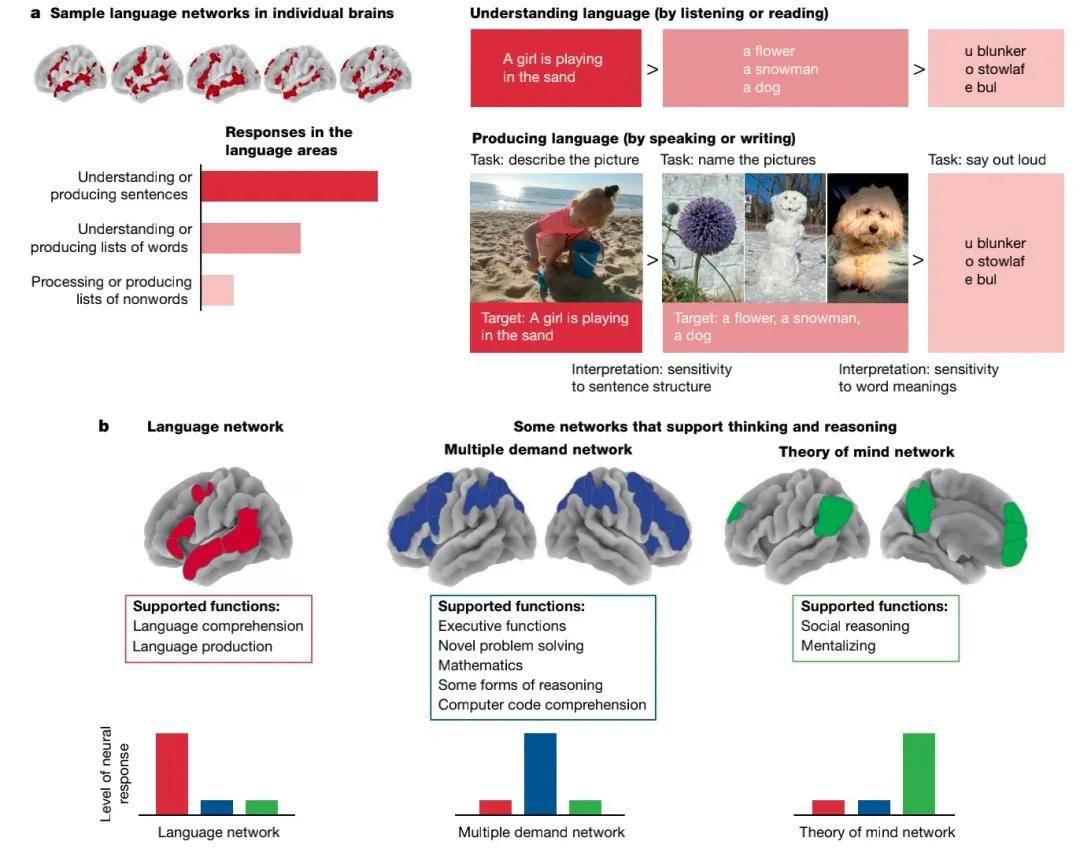
因此,将大型语言模型视为能理解人类情感的观点在我看来并不准确。近期,《自然》杂志上发表的一篇由麻省理工学院研究人员撰写的文章进一步支持了这一看法。该文章探讨了语言作为交流工具而非思考工具。

文章指出,语言最初是为了满足人际间沟通需求而产生的。即便在缺乏语言的情况下,人们仍然能够进行思考。研究者通过观察聋哑儿童的成长过程进行了论证。尽管这些孩子无法听到或说出言语,但他们仍能学习数学、进行逻辑推理和建立因果联系,说明他们的思维能力并未受到影响。
这篇文章强调了语言模型仅依赖于语言和文字训练的事实。既然语言主要是一种交流工具而非思维工具,期望通过语言训练得到具有思考能力的模型无疑是不切实际的。尽管某些情况下模型表现出了看似智能的行为,但这仅仅是模拟的结果。
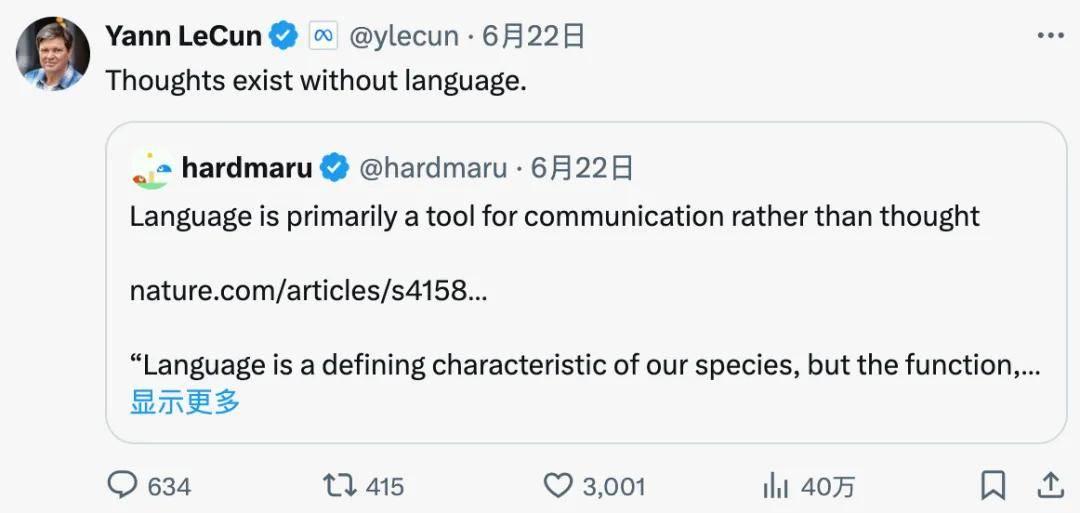
值得一提的是,Facebook(现Meta)的人工智能首席科学家杨立昆也曾表达过类似观点。他认为思维与语言并非等同,即不能简单地假设通过语言训练就能使模型具备真正的思考能力。杨立昆是人工智能领域享有盛誉的专家,他曾荣获计算机科学领域的最高荣誉——图灵奖。
本文为科普中国·创作培育计划扶持作品
作者:孙善明 中国计算机学会GESP技术委员会主席;中国计算机学会PTA技术委员会常委;中国计算机学会科普工委委员;中国计算机学会高级会员;CCF2024年度杰出演讲者;中国电子教育学会青少年教育分会副秘书长;
审核:崔原豪 南方科技大学系统设计与智能制造学院副研究员
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司
来源: 科普中国创作培育计划
内容资源由项目单位提供
