
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科小二
科小二 DeepSeek公司背景与发展
DeepSeek于2023年成立,其母公司幻方量化在量化投资领域成绩斐然,是国内顶尖的量化投资公司,管理规模曾一度突破千亿大关。2020年3月,幻方量化建立萤火一号算力集群,紧接着在2021年建立萤火二号,二者共同构成了当时亚洲规模最大的私有化AI算力池,拥有近万张A100 卡。当时,幻方量化出于自身量化投资对算力的需求建立此算力池,同时面向公众开放使用。这一举措为后来大模型的发展奠定了坚实基础,也展现了幻方量化在技术布局上的前瞻性。

DeepSeek模型发展历程
DeepSeek在模型研发上稳步推进,2024年初推出首个大模型版本,起初在行业内并未引起较大轰动。然而,2024年5月推出的V2版本开始崭露头角,性能对标GPT-4,而价格仅为GPT-4的百分之一。在国外学术圈和工业圈,它早早受到关注,特别是在代码开发领域表现突出,成为国外众多AI Coding软件中唯一集成的国产大模型。去年年底推出的V3和R1版本更是引起了国内外的广泛关注,其模型性能对标国外最顶尖的OpenAI-o1模型,充分展示了DeepSeek在技术研发上的实力。
DeepSeek技术优势剖析
基于强化学习的训练方式
DeepSeek-R1的Zero版本基于大规模强化学习进行训练,抛弃了传统的基于人类标注反馈数据训练的奖励模型,选择了客观评价指标作为奖励模型。这种奖励模型主要基于两个核心要点:一是回答的答案是否准确,即是否可通过计算规则进行检验;二是答案格式是否符合要求,即是否包含了思考的过程。以回答数学问题为例,若模型简单回答正确记1分,若通过逻辑推理得出正确答案则记2分,答案错误记0分;在代码生成任务中,通过编译器运行结果判断,符合预期记1分,编译失败或结果错误记0分,有思考过程会额外加分。与传统依赖人类标注的方式相比,DeepSeek的评价方式更加客观,有效避免了人类标注存在的效率和准确率问题,同时也规避了人工反馈带来的主观和价值观因素影响。

创新的模型架构
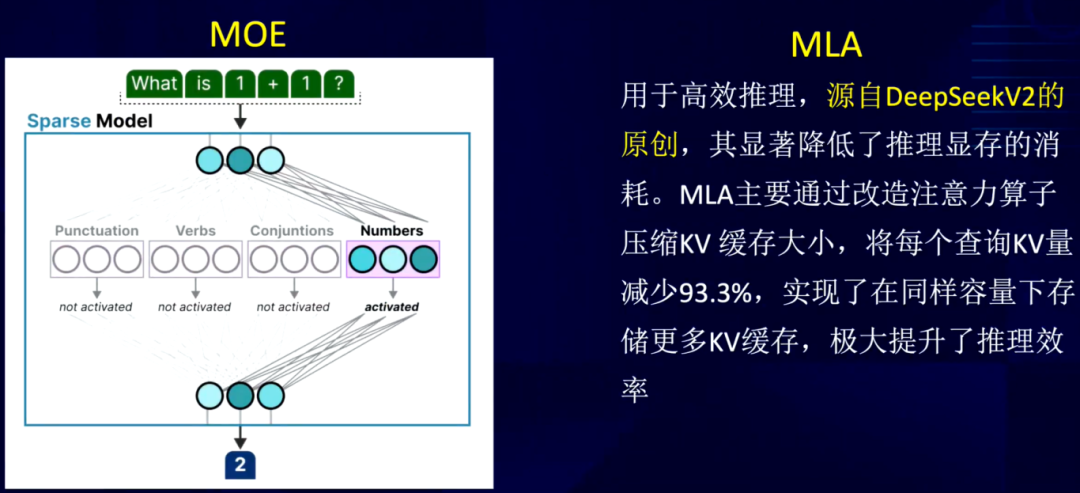
在模型架构方面,DeepSeek有诸多创新。DeepSeek采取目前流行的混合专家(MoE)架构,MoE借鉴了人类大脑的工作原理。大脑的不同区域负责不同功能,如前额叶负责逻辑推理,颞叶中的梭状回面孔区负责人脸识别、而海马体负责记忆等。MoE架构下参数量虽大,但特定任务仅由特定的一小部分参数处理,这极大地降低了计算消耗,同时也便于对参数权重进行定向优化。此外,DeepSeek自主创新的MLA模型通过算法调整,减少了推理过程的KV Cache,降低了显存消耗,进而提高了推理效率。这两种架构的结合,为DeepSeek的高性能表现提供了有力支持。
软硬件协同优化策略
虽然DeepSeek很早就建设了万卡集群,但是与国外同行相比,规模依然不足。面对算力资源的限制,DeepSeek采用了精细的调度算法,压榨硬件的每一分算力。传统方式在训练时,参数权重更新需一层一层按顺序处理,存在排队等待的情况,导致算力利用率不高。而DeepSeek的DualPipe调度算法类似于流程优化,通过合理安排前向过程、后向过程以及层间通讯,使有前后依赖的任务紧密协作,从而在最短时间内完成一轮迭代训练。这种软硬件协同的方式,在国产GPU算力与英伟达GPU存在差距的情况下,通过软件优化弥补了硬件的不足,为AI产业的发展开辟了新的路径。

DeepSeek的特点
DeepSeek的以下几个特点,使其成为独树一帜的标杆。
首先,其训练成本大幅下降,外媒报道仅需几百万美元,与之前动辄上亿的训练成本相比成本显著降低。同时,通过蒸馏DeepSeek生成高质量的推理数据,再利用这些数据微调像千问、Llama等开源小模型,用极低成本大幅提升了这些小模型的性能。
其次,DeepSeek将最大规模的671B模型参数完全公开,且开源协议非常宽松,允许自由修改、复制和商业化,这消除了企业在数据安全方面的顾虑,使企业能够放心地在自己的环境内部署私有化版本,将企业内部的文档、技术资料甚至财务数据用于大模型的问答和应用,扫除了大模型应用的最大障碍。
因此,DeepSeek彻底颠覆了AI产业原有的商业模式,原来通过商用模型部署的业务模式因DeepSeek的出现而发生巨大改变。

DeepSeek使用经验分享
访问与替代方案
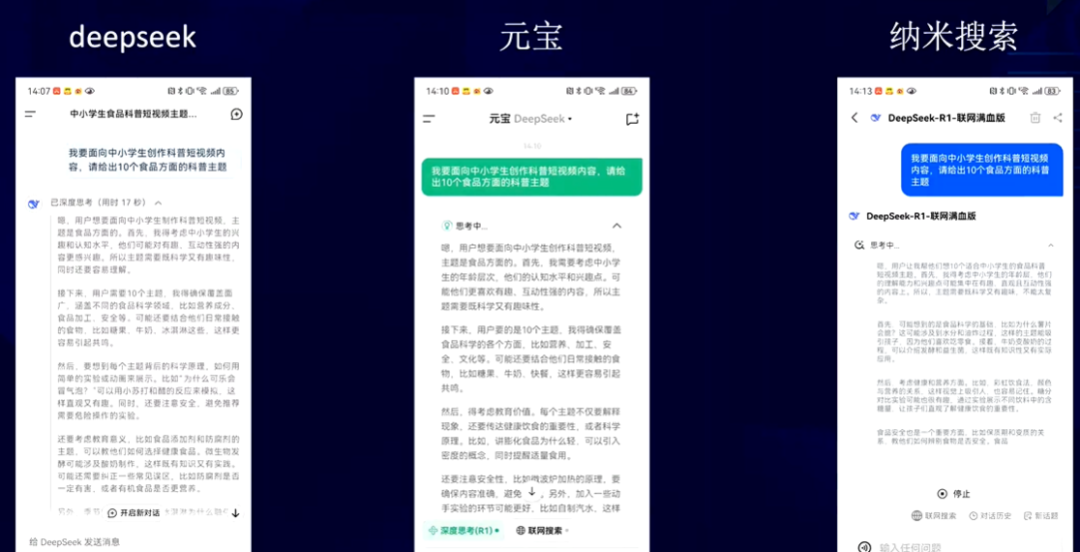
目前,DeepSeek提供了官网和APP供用户使用,但是因用户量爆棚,在使用时可能会出现不稳定的情况。在这种情况下,有一些替代方案可供选择,如腾讯元宝和 纳米搜索等。这些平台支持全尺寸模型的问答功能,还具备联网搜索和文件上传等功能,在DeepSeek官网不稳定时能为用户提供备用方案。
使用技巧与注意事项
使用DeepSeek时,打开“深度思考”开关至关重要,因为该开关关闭时使用的是V3非推理模型,而打开后则调用R1推理模型,能获得更强大的功能。在提问方式上,相比以往复杂的提示词工程,DeepSeek推荐使用更自然的表达方式。用户只需专注描述问题的背景信息、明确自己的目标以及添加风格提示等,例如要求“面向初中生以鲁迅风格写一篇食品类科普文章”。此外,强烈推荐用户阅读清华大学出版的关于DeepSeek使用介绍的 PPT,其中详细介绍了向DeepSeek提问的技巧,有助于用户更好地与模型进行交互。

如何将DeepSeek用于科普创作?
科普主题发掘
DeepSeek在科普主题发掘方面具有很大的潜力。它可以在特定领域,如前沿科技、城市生活常识、当下流行的伪科学等方向,为创作者提供科普主题。同时,还能根据不同的受众群体,生成相应的主题。例如,针对60~70岁的老人,DeepSeek会提供围绕健康管理方面的三高管理、科学饮食,以及退休后的心理健康指南等主题。此外,结合近期热点新闻,DeepSeek能从热点话题中筛选出有价值的科普主题,如根据近期小行星撞地球的热点话题,为科普创作提供灵感。
科普内容生成
基于给定的科普主题,DeepSeek能够为不同受众生成针对性的科普内容。以人造太阳的科普为例,当要求为小学三年级学生创作科普文章时,它会避免使用专业术语,尽量用浅显易懂的语言描述人造太阳的价值和功能;而当为高中三年级学生创作时,则会包含科学专业术语和相关数据,适合高中学生作为课外拓展阅读。DeepSeek还可以生成短视频脚本,为科普短视频的制作提供便利。同时,在科普分级读物方面,它具有生成不同难度文章的能力,通过难度设定可以精确匹配不同阅读水平的需求,这对于中文科普分级读物的发展具有重要意义。

此外,在科普访谈方面,DeepSeek可以根据访谈对象和主题,结合互联网上的相关材料,生成定制化的访谈提纲。访谈结束后,还能根据访谈文字稿辅助生成总结文章,提高工作效率。在处理国外前沿论文时,DeepSeek可以将论文内容转化为有趣的科普文章,在内容风格上并非机械解读,而是结合科普宣传的需求,吸引读者的注意力。
拓展应用场景
DeepSeek结合其他技术,能够拓展科普内容创作的边界。例如,结合简易AI自动化匹配视频素材并进行剪辑,再结合文本生成语音(TTS)技术,可以制作完整的科普短视频;结合豆包进行文本生成,实现图文混排,使科普内容更具吸引力;结合Kimi等相关工具可以制作科普PPT,用于展示科普知识;结合数字人技术生成科普数字人,为中小学生或特定用户群体介绍科普内容,这种应用在科普基地、博物馆等场所具有广阔的发展空间。

AI时代不缺好答案,而是缺好问题。提出好问题可能是人们未来需要学习、提高的重要素质。期待人工智能未来在科普内容创作领域发挥更大的价值,助力全民科学素质水平提升。
(作者:董霖,浙江省科普联合会副会长、每日互动创始团队成员、首席数据官)
本文根据浙江省科普联合会周四夜学内容整理
来源: 科小二
