
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普中国新媒体
科普中国新媒体 
这个春节,有一款国产AI大模型成了科技新闻里“最靓的仔”,甚至回老家过年,不少亲戚在饭桌上聊的“下饭话题”都变成了AI。我们这些在北上广互联网公司打工过的牛马,作为家人眼中唯一一个懂“修电脑”的人才,自然难免要被问到各种相关问题。

图库版权图片,转载使用可能引发版权纠纷
如何跟不了解科技行业的亲朋好友简单易懂地讲清楚DeepSeek,颇花费了我一番脑汁,但效果还不错,比如我妈听完后一拍大腿表示:八成懂了!(咳咳,有一说一,回答这个问题还是比“为什么不结婚/生小孩”,简单多了……ㄟ(▔,▔)ㄏ)接下来我就把我跟我妈讲的概括一下,希望能够帮你揭开DeepSeek的神秘面纱。
先总结一下,DeepSeek有三宝:
开源普惠,人人可复制嫁接
成本大幅降低
训练模式突破性创新
其中每一条都为人类通往构建AGI创造了有利条件——所谓AGI,指的是能够像人类一样完成各种不同任务的人工智能。它不仅能做一件事,还能学习、适应并解决多种问题。接下来,咱们就简单聊聊DeepSeek先进在哪儿,有什么特点。
DeepSeekR1强在哪儿?
DeepSeek之前,最为人熟知的大模型产品是ChatGPT,全球月活跃用户约4亿。但是大部分用户体验到的ChatGPT免费版本仍有许多不足。
比如,以前你问ChatGPT这样的问题:
“小美上午9点的心率是75bpm,下午7点的血压是120/80。她于晚上11点死亡。她中午还活着吗?”
Chatgpt就会被绕晕,给出不靠谱的答案。这说明彼时ChatGPT并不理解数字和数理之间,以及事物之间的逻辑关系,它回答对了可能是瞎蒙,可能是鹦鹉学舌。

注:由于现在的AI已经能解决这类问题,这里特地让ChatGPT扮演更老的版本以展示可能出现的错误
但DeepSeekR1在展示结果同时,显示了完整的思维力(Cot)推理过程,把问题一步步拆解分析,并且在学习数学题过程中,显示出了提炼总结数理公式的能力。

这就是DeepSeekR1在计算性质上不同于ChatGPT和GPT-4/4o的根本区别——R1是推理模型,后者不是。
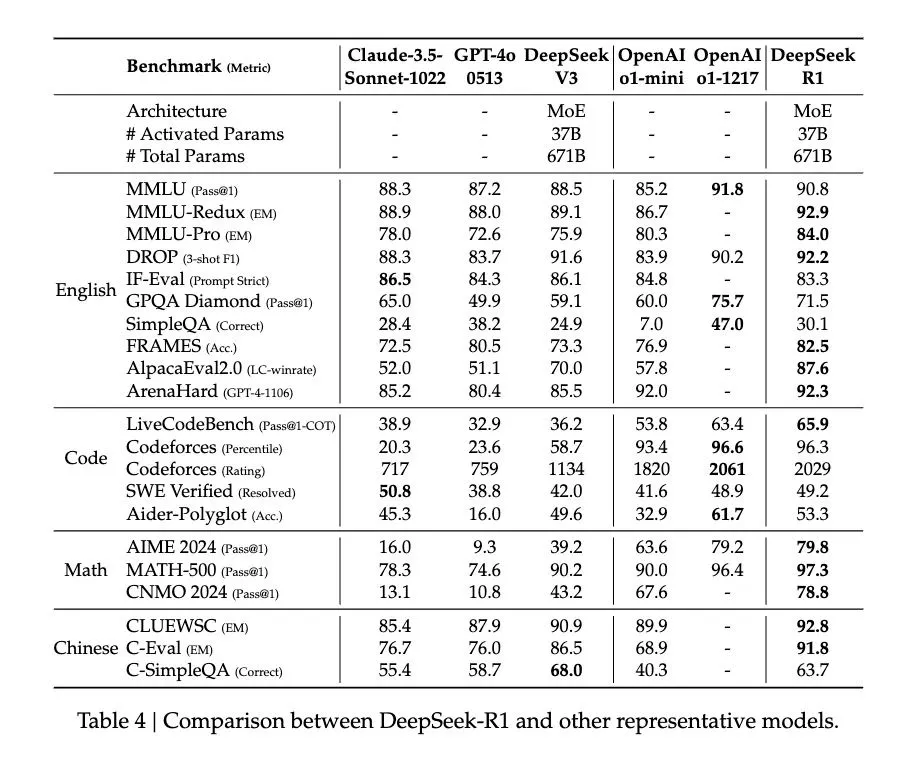
我们为了检验它是否真的学会了数理逻辑,而不是靠积累的语料数据“瞎蒙”,派他去独立解决各类数学和编程竞赛的问题,结果十分亮眼——在MATH基准测试中的得分为97.3,在AIME上的得分为79.8,超过了OpenAI的o1预览版。而在中科院物理所的竞赛比拼中,也取得了优异的成绩(参见 我们用最近很火的DeepSeek挑战了物理所出的竞赛题,结果……)
当然,这些测试只是从一个方面衡量了DeepSeekR1的能力,其他复杂的任务,可能会涉及不同的评估方法和指标。
为什么说R1-Zero是
AI界的“野生学霸”
如果说传统AI是“补习班量产的好学生”,成才主要靠辅导老师天天耳提面命,那R1-Zero就是靠自学的“天才少年”。
R1-Zero的“自学”过程依赖于强化学习(RL)算法,而非传统的人类标注数据。通过反复训练和优化,尽管没有人工干预,它仍在特定的反馈机制下自我优化,最后在数学题目中展示出了卓越的推理能力。
这个方法跟ALPhaGo有些类似,对,就是那个曾经战胜过人类最强棋手的“硅基棋王”——它并没有根据人类的围棋教程学习,全程也没有接受过任何人类输入的信号指导,完全依赖自己和自己“亿局局”下棋、胜负归纳总结,产生了强大的下棋策略。
更绝的是,DeepSeek的解题过程一步步推演,可以长达成百上千字,甚至上万,堪比《三体》里罗辑的面壁计划——每一步都充满“如果……那么……”的逻辑推演,而且连中学生都能看懂它的思维过程。
同时,它的训练方法还带来了效率提升,训练周期更短,资源消耗降低,由于省去了SFT和复杂的奖惩模型,计算量减少。
开源:技术界的“人民战争”
需要指出的是,DeepSeekR1并不是目前唯一的推理模型。OpenAI的o1模型在推理任务上表现也很出色,但是DeepSeek有个显著的不同。
那就是,OpenAI的o1模型像米其林三星餐厅——菜品惊艳,但厨房谢绝参观。而 DeepSeek直接把菜谱开源,邀请全世界极客来改良——有人往模型里塞《五年高考三年模拟》,训练出秒杀奥数冠军的AI;有人用R1给女朋友写情书,结果因为逻辑过于严谨被骂“直男癌”。这种“群殴式创新”,让AGI研究从高冷学术圈变成了全民参与的“黑客马拉松”(指限定时间内大家通过编程、设计等技能合作,做出有趣或实用的项目。)

版权图库图片,转载使用可能引发版权纠纷
更重要的是,模型开源,让全世界的科技人才,都有可能站在R1的基础上,进行改良再创造。科技的历史进程已经一次次告诉我们:基础技术的传播扩散,会引发更大量、更先进的前沿突破和实际应用的涌现。
科技树的点亮,没办法仅靠一个人或者一家公司,DeepSeek的开源,就相当于一次开枝散叶的重要过程,而这也会提高DeepSeek的声望和影响力。
省钱鬼才:成本仅用十分之一
大模型领域的研发其实是很“烧钱”的,很多知名的大模型,训练一次成本就高达数百万美元。
而DeepSeek最为人称道的,是它把成本抹了个零——是的,它直接把成本金额的末尾砍掉了一个“0”。简单地说,DeepSeek采用了一系列架构、算法和任务拆分等方面的优化和创新,这样就能只用较低的成本就完成训练任务,而这些方面的创造力正是DeepSeek的卓越之处。
更反常识的是,成本暴降的同时,性能反而飙升:它能够在一个请求中处理多达128000个Token、一次最多可以生成32000个Token(注:1个token视情况相当于1个词语或1个汉字),非常适合编写深度报告或剖析大量数据集,作为生产力工具效能极大提升,活生生把AI从“吞金兽”变成了“招财猫”,利人利己。
用推理实现环保
最新的研究和报道显示,随着人工智能行业的规模和影响力急剧扩大,维持人工智能增长所需的计算能力大约每100天翻一番。目前,ChatGPT每天需要消耗大约564兆瓦时的电能。
同时,支撑大模型运算的数据中心服务器会需要消耗大量的水资源来散热。有研究显示,ChatGPT-3在训练期间耗水近700吨,其后每回答20至50个问题,就需消耗500毫升水。
耗能、耗水、增加碳排放,曾经是我们担忧通往AGI之路的重要阻力,但是,DeepSeek的成功向我们揭示了——或许我们有其他更好的道路。
过去十年,AI界沉迷于“数量碾压”:堆算力、冲数据量、比谁烧钱多。但DeepSeek另辟蹊径——与其让AI死记硬背《百科全书》,不如教它“怎么像福尔摩斯一样思考”。结果在ARC-AGI测试(AGI核心能力基准)中,R1系统与人类表现不相上下。
这证明:也许推理能力才是打开AGI之门的钥匙,而钥匙孔里透出的光,正在被开源社区的手电筒照得越来越亮。
DeepSeek不是神话
是团队一步步创造的火种
虽然DeepSeek的故事听起来像一部科幻爽文:它用纯强化学习打破了数据垄断,用开源点燃了全球极客的激情,再用成本暴降,让AI能更好地从实验室走进我们的生活,但它绝不像某些流量自媒体为了博眼球说的那样横空出世,更不是什么抄袭了其他厂家AI的结果。
过去一年,DeepSeek团队一直稳扎稳打,从V2模型(2024年5月发布),到V3模型(2024年12月发布),到最近的R1和R1-zero模型,每一步都取得了显著的进步,走得很扎实,而且其创新有开源的信息为证。
因此,不要理会那些逆袭开挂爽文或是抹黑文,我们要相信的是,从人类集体进步的角度讲,投入时间、智慧和真正能点燃人的信念,突破式创新一定会涌现。
当我们惊叹于R1的优异表现时,也别忘了——它省下的每一度电、开放的每一行代码,都在为AGI降临积蓄能量。或许未来某天,当真正具备通用智能的AI回首历史时,会像人类铭记火种与轮子一样,为DeepSeek刻下一块里程碑。
参考文献
[1]《DeepSeek-R1:IncentivizingReasoningCapabilityinLLMsviaReinforcementLearning》 https://arxiv.org/abs/2501.12948
[2]DeepSeek-V2:AStrong,Economical,andEfficientMixture-of-ExpertsLanguageModelDeepSeek-V3TechnicalReporthttps://arxiv.org/abs/2405.04434
[3]DeepSeek-V3技术报告https://arxiv.org/html/2412.19437v1
[4]《研究人员发现算法可将人工智能能耗降低95%》
https://oilprice.com/Energy/Energy-General/Researchers-Discover-Algorithm-to-Slash-AI-Energy-Consumption-by-95.html
[5]DeepSeekR1-Zero与R1的结果与分析.腾讯云开发者社区.
https://cloud.tencent.com/developer/article/2493328
[6]GPT-4Can'tReason https://arxiv.org/abs/2308.03762
策划制作
作者丨木木 北京师范大学数学专业资深产品经理 人工智能创业者
审核丨于乃功 北京工业大学机器人工程专业负责人,北京人工智能研究院机器人研究中心主任,博士生导师
来源: 科普中国新媒体
内容资源由项目单位提供
