
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 返朴
返朴 
嘉宾:马剑鹏 (国际著名计算生物学家、复旦大学复杂体系多尺度研究院首任院长)
整理:深究科学
蛋白质结构预测的历史回顾
蛋白设计也好,蛋白质结构预测也好,它归根到底跟一个问题有关系,就是叫蛋白质折叠。
我先来简单解释一下什么叫蛋白质折叠。我们知道,蛋白质首先是有空间结构的,而且有很多蛋白的空间结构是唯一的。蛋白质的氨基酸序列,是由遗传密码来决定的。遗传密码是一维的,所以它这里有个问题,就是如何由一维的蛋白质序列记住这个三维的结构,这就是所谓的蛋白质折叠问题。
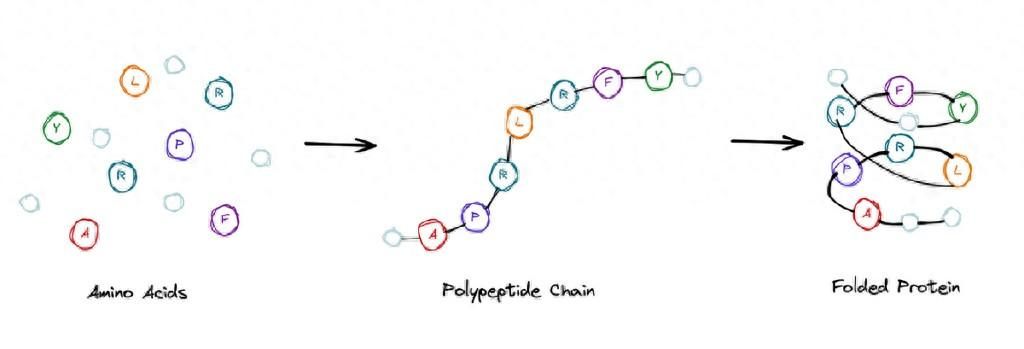
那么,为什么这个问题那么重要?有人说这个问题是太阳底下最难的一个科学问题之一,也是上个世纪末生物学里面所谓的一个“皇冠上的珍珠”。谁能解决这个问题,就肯定能获得诺贝尔奖,所以很多人都在为之努力。
这里有个关键,组成蛋白质的氨基酸主要有20种,氨基酸残基是线性连接的。大家可以从科普的角度上想象,它是一个氨基酸的链,就像一串珠子,一串念佛珠。如果这个珠子一共有20种不同的颜色,所谓的20种不同氨基酸的系列,把这串珠子往水里一放,它会很快折叠成每次折都一样的三维结构。
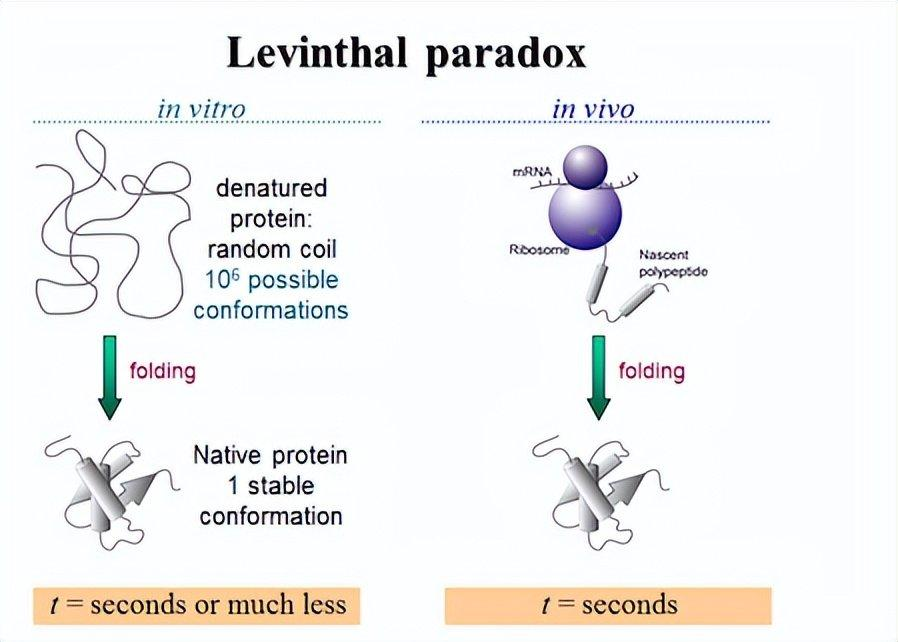
问题是,如果这个链的折叠过程是一个穷举的过程,要把这条链从展开的构型折叠成最后一个三维唯一的结构,这需要的时间可能会比宇宙的寿命还长。但事实上,蛋白质链在细胞里面被合成的一瞬间就很快就折起来了,折的速度远远比1秒钟要快。
这就来了一个问题,它怎么折的?因为它没有脑子,就是水里面有一些物理作用之类的这么折起来。蛋白折叠会非常快,所以这里显了一个悖论,到底是怎么折叠起来的?这就是著名的蛋白质折叠问题和著名的利文索尔悖论(Levinthal's paradox)。
从上个世纪中叶到现在,无数的前辈一直在孜孜不倦地研究这个问题,包括我们研究院的荣誉院长、2013年诺贝尔化学奖得主迈克尔·莱维特(Michael Levitt)教授等人。随着时间的历史推移,这个问题慢慢地就分化成了两个问题:一个是蛋白质为什么会这样,或者它是怎么折叠的;另一个问题相对比较实用一点,蛋白质结构预测问题。
关于第一个问题到现在还没有完全回答好,而第二个问题就是给你一个蛋白质的序列,告诉它最后的折叠结构就行,只关心终点,不关心怎么来的途径。关于途径这个事情是个基础科学问题,也是个物理学问题,很多人还在搞这个东西。
但后面这个问题,随着时间的推移,一开始做物理的人更起劲在回答,由于实用性的结构预测是非常困难的,所以几十年来有人孜孜不倦地在做,进步不是很大,但是有那么些人在做,包括今年获得化学奖得主David Baker,他这么多年一直在这个行当里面,是一个领军人物,做得比较好,但是他在很长时间内预测精度也只有40%。
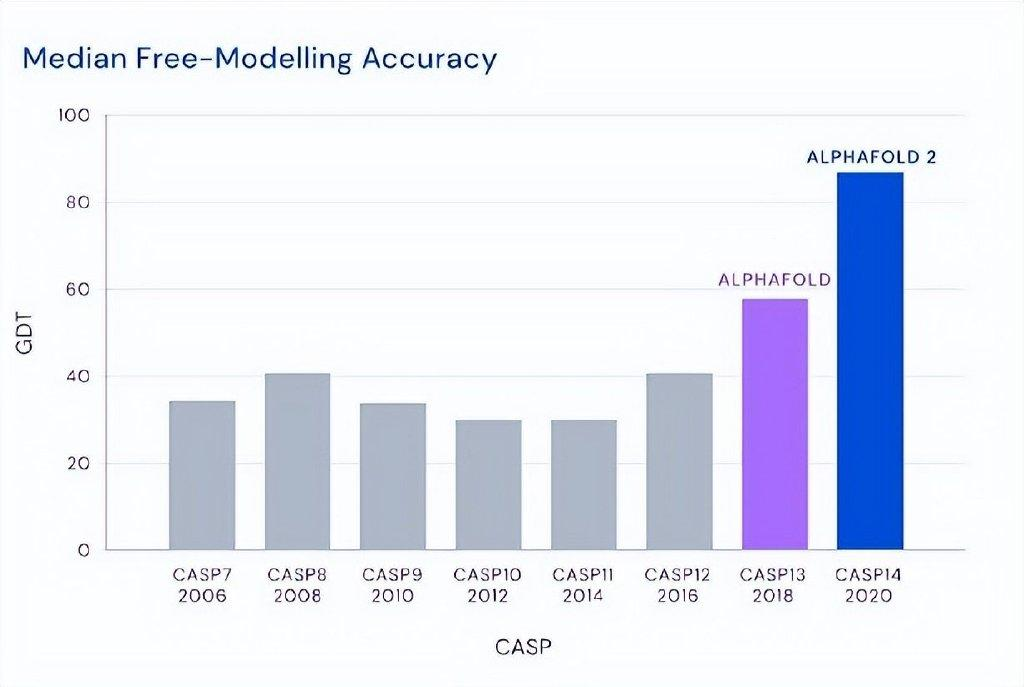
这个精度是指一个非常著名的国际比赛——关于蛋白质结构预测关键评估(CASP)的比赛。我们团队也参加这个比赛,做了很多努力。迈克尔·莱维特50年前创的这么一个行当,就是因为他一直是做计算的,他企图用计算机来预测这个问题,但精度一塌糊涂。由于这个问题非常重要,所以大家一直在做,但我说的精度一塌糊涂,就是说当年用计算机来预测出来的蛋白结构,就算达到40%的精度,也不足以让生物学家或者做实验的工作者觉得这是有用的。
然而,突然有一年,大概四五年前吧,出了个Alphafold。这个Alphafold第一次把这个精度从40%提高到60%,已经让人很震惊了。再过了两年,到CASP14的时候(2020年),它一下子达到了88%,88%这个数字很重要,因为实验的测定精度也只有90%,所以你接近88就接近90了。大家觉得这个问题几乎解决了,全世界都为之震惊。
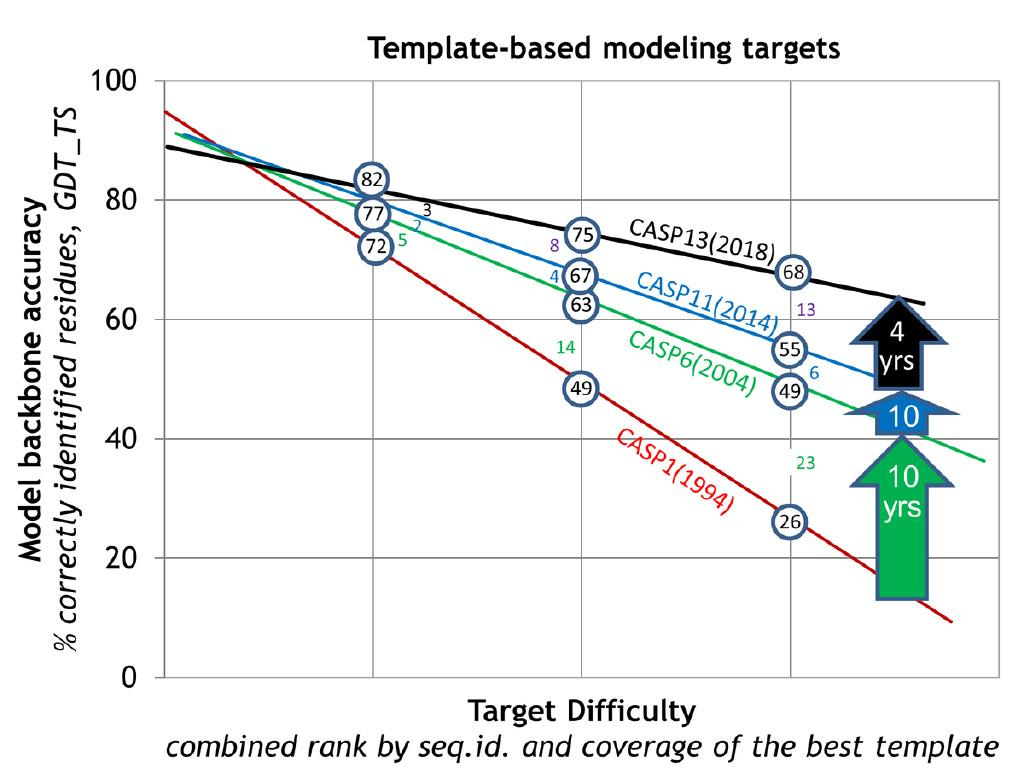
这里要强调一点,像迈克尔包括我就做这个行当的,大家孜孜不倦地在做,但我们都清楚,一路走来,这个问题计算机预测是不可能在我们有生之年得到解决的,当年我们这些人是这样走过来,没想到两下子,Alphafold 1、Alphafold 2一下就到了80%多,现在又有Alphafold 3了。
这个就是历史,非常简约的历史。
AI变革蛋白结构预测、蛋白设计
现在来讲讲这个Alphafold是怎么突然间两步就到位,几乎做成了结构预测,就是AI框架,在Alphafold 1出来以前,包括David Baker都是在用计算的。我现在讲的全都是用计算机预测蛋白质结构。

绝大部分人都不是用AI,也有一些人在用AI,但AI在这方面的展示结果并不好,都是用一些其他的物理方法,包括Baker,尤其是Baker。Baker以前不是用AI,我也不是,迈克尔也不是,但就是因为这个deep learning(深度学习)方法的介入,导致这个精度有了突飞猛进的进步。那么,这就要说到AI技术,这是两条不同的路径。
今年诺贝尔物理学奖给了AI领域,而化学奖则给了在蛋白质预测上有突出贡献的AI技术。在不久以前,大家都记得AI曾经打败过国际象棋,当时大家觉得不得了,国际象棋已经被AI打败了,但是后来什么事情没有发生,因为你要打败国际象棋,拿个计算机就可以穷举,你要把世界上所有的棋谱都学进去了,因为一个高手下棋不是要多想几步吗?计算机肯定比你想的快,它把所有的路都走完了,那把你打败也不奇怪。
deepmind公司的这帮人,尤其是今年诺贝尔奖的第二个得主哈萨比斯,他是一个计算机工作者,他就去找了一个科学问题,不仅找了个科学问题,还找了个太阳底下最难的科学问题,就是蛋白质结构预测问题。这个问题不是个新问题,它早就在那里存在的,Baker包括我们一直在做。他就捡起了这个问题,把这个问题朝前推了一大步,于是就有了Alphafold 1和Alphafold 2。
这下全世界整个变过来了,科学家也开始注意,原来AI这么厉害。这就是为什么现在有一个非常热门的词,叫AI for Science。以前从来没听说过,AI for Science里面,AI不是什么新词,AI很多年了,Science更是有悠久的历史。为什么现在才想起来叫AI for Science?原来这两个东西关联性不是太大,就是说AI本身是一个算法,或者是个工程技术,传统的做AI的人都是做视觉、人脸识别、无人机操控、自动驾驶之类工程问题上的应用,它的难度跟蛋白质折叠是根本没法比的。蛋白质的确是非常非常难,所以我说,大家都认为它是太阳底下最难的一个科学问题。
那么,居然在这么难的问题上朝前跨了一大步,所以现在它直接的效果就是导致AI for Science的出现,而且现在我们已经是人生无处不AI。原因很简单,就是大家全世界无论是做Science的人,还是其他领域的人,都注意到现在的这个deep learning这个东西,居然把这么难的一个科学问题也可以往前推这么一大步,那稍微简单点的(科学问题)就更容易了,所以这广泛的就应用开了。
今年物理学奖和化学奖的相互成就
今年诺贝尔化学奖,其实分两拨人。第一个就是Baker,后来是哈萨比斯和贾伯,哈萨比斯和贾伯是一个团队的,他们就是做Alphafold的那两个人。Baker跟Alphafold理论上没有关系,这不是他发展的,但他后来包括现在也在用。那为什么得这个奖?
自从用计算机可以用来预测蛋白质结构,所谓预测蛋白质,无非就是蛋白质结构建模,只不过是这个模型不是用实验数据来检测的,是用计算机来建的。有了这个能力以后,这个行当里面就可以大致分为两大问题:一个就是大家孜孜不倦地在追求的蛋白质折叠问题,我给你一个序列,你把它对应的结构给我弄准,这就是折叠问题,那也是Alphafold最大的贡献之一,它可以把蛋白折叠弄得比别人好得多得多。Baker也是做这个问题出身,Alphafold 2那两个人也是在这个时候有巨大的贡献。
诺奖委员会专门点了下蛋白设计,它的区别在于,这两个问题的关联度是极大,但也不完全是一回事。这两个东西的本质要求是必须得有一个蛋白质序列,把它的结构查一查。但是以前,我们连自然界已知的蛋白质序列给你,也未必搞得准。不是40%,对吧?后来88%了嘛,那你何来谈设计?
它区别就是纯粹的折叠,那就是把一个已知的序列,你把它结构弄准了就行了。但是设计显然是指你要设计一个自然界不存在的蛋白序列,至少是经过修改过的序列,那就说设计更难,但设计的底层逻辑肯定也是折叠,你不会折叠,你设计什么?但是会折叠不等于说你一定会设计。

在这两个方向上面的做世界上做折叠其实是非常多,Baker当然是个领军人物,后来就被Alphafold给取代了。但是Baker在Alphafold出来以后,他也踉跄了几步,因为他的折叠精度一下子被Alphafold给碾压了。但是他又很快崛起了,他最近几年主要是在设计上。所以诺奖里面就讲了很清楚,也就强调了蛋白设计这个事。
我一直讲,蛋白质的折叠是个基础科学问题,但蛋白质设计是一个艺术,就是你到底设计什么,这个选项是非常多的。那么这个时候,我要不得不强调一下,为什么把这个给Baker在这个奖里面。诺奖里面说David Baker主要以设计为主,其实他也是做折叠出来的,在Alphafold以前,他在折叠方面是做得最好。但是做设计,他在全世界几乎就是一个望尘莫及的存在,很多团队都企图做设计,但是做不过Baker。
做折叠还是有很多人,而且还有几个人不见得比Baker做得差,可能Baker做得比较早。但是设计是怎么也做不过他,这里面当然有很多的原因,但是我认为有个很主要的原因,就是Baker的团队除了很有钱,可以招到很多优秀的人才以外,他会做实验。Baker本人是做实验出身的,其实他后来改行做计算蛋白结构预测,这就充分说明了在蛋白质建模,尤其在设计这个行当里面,必须要干湿结合,不仅要有预测,设计也是先有预测,然后你要用湿实验去验证,就是设计出来的东西是很难继续用计算的方法来判别设计得对还是错,以及它的合理性。其实有一部分可以使用计算的,但是不可能100%的准,最后还是要通过湿实验来验证。
当然,做设计的人也可以去找一个实验团队跟你合作,但是合作一般比较难。这个Baker组的强项就在于此,他们本团队就有很强大的这个实验工作能力,所以说他的蛋白设计什么时就“喷”地一下出来了,这就是个关键问题。所以诺奖这三个人里面,Baker就是这个方面的贡献。其实他一方面是前面我也讲过折叠也做得不错,但是我刚才讲了,如果这个奖是给蛋白质结构预测的话,不应该光给Baker,肯定还有别的人。但是要强调设计的话,那它确实是独树一帜的。
那后面两个人是显然获奖的,那是Alphafold的发明人,因为他们把精度给猛推了一把。Alphafold这个方法主要是基于deep learning,deep mind公司做出来的,或者现在他们公司分出来就叫Isomorphic Labs。它是很了不起的,它的成功带动了一系列的应用。但我必须要强调一下,就是说其实Alphafold到今天为止,至少Alphafold的成功,它对AI这个领域的贡献或者它的影响力,就是它的作用,其实远远大于对蛋白质本身的影响。
因就是说Alphafold,包括现在Alphafold 3也是,它虽然很强大,但蛋白质结构预测也好,蛋白质建模这个问题并没有被解决,它只是往前推了一大步。但是它的伟大之处在于不仅把这个这个问题往前推了一大步,虽然它没有完全解决,它向全世界展示,你看,我在这么难的问题上也能往前爬一大步,那其他问题就更容易了。所以才导致了整个AI被全世界彻底接受,而且每个人都在用AI。
这也是为什么今年的物理学家给了AI这个奖项,他们去找回了他们原始的、这个最早的创始人。但是应该说,如果没有化学奖这几个人的成功,虽然化学奖发在物理奖后面,今年的物理奖是不会给AI的。
那未来AI应该做什么?那其中有一个使命,其实它更重要的使命多了,就是要来解决它两端能不能统一起来,就是数据驱动和逻辑驱动这两样东西。其实你看它这个奖,尤其是物理学奖,它如果离开统计力学没有那么远的话,这两者统一起来是有可能的。这也是AI界的一个前沿问题。
Alphafold预测蛋白侧链有短板
AF就是AlphaFold的成功,它对AI行当的冲击要比对蛋白质(结构预测)本身要大。怎么来理解?首先一点,我刚才说我们做蛋白质结构的侧链,侧链结构预测当中的一个分支就是蛋白质结构。蛋白质本来就有主链和侧链,我们花了很大的力气,现在还在做这个事情来分析。
就是AlphaFold 2也好,AlphaFold 3也好,它吐出来的结果,不是说它80%或者怎么的,这个精度很高,它到底走到哪,到底还有什么问题?其实,这是个非常非常聚焦的一个问题,或者是专业问题。它其实主要的误差就在侧链上。
我这么说的话,是有数据的。我并不是否认AlphaFold的贡献,它的贡献无穷大,但是它并没有解决这个问题,我觉得这个就是其中的一个原因,因为它的侧链不够准。所谓的侧链不够准,严格来讲,应该是这么说,就是说如果要是从药物设计的角度讲,药物设计、药物分子,大部分都是跟侧链相互作用的。要是从那个角度讲,纯粹的,注意纯粹地用AlphaFold来预测结构是不够的,绝大部分情况下是不够的。
但是这不等于说AI在新药创新上就无能为力了,相反它很有用。也就跟刚才讲的一样,如果你来折叠,我说这个折叠是凭空折叠,就从序列开始,把这个把结果搭起来,都能搭得那么好,虽然不是100%,主链侧还有很大的误差,那其他的问题,比方说小分子筛选,或者肿瘤诊断、制药,它有很多的环节,几乎每个环节上都可以来用,就这么来。你不能把AI赋能新药创新,就等价为是AlphaFold的这个预测,那就是两码事情。
计算生物学未来的发展潜力
因为药大部分都是跟蛋白相互作用。有些小分子药,是跟蛋白作用,或者是蛋白质药,那就是跟另外的蛋白质相互作用,或者是核酸药,核酸最后也要跟蛋白质相互作用。当然核酸也有可能跟核酸相互作用,这个是毋庸置疑的。但这个结构设计问题,其实是非常好,就是说Alphafold 3,最近在朝着这个方向上迈出了一个非常好的方向,但这个问题还远没有得到解决。怎么回事?就是说Alphafold 1好,Alphafold 2也好,David Baker也好,虽然今年诺奖的主题就是蛋白质结构的预测,对不对?
为什么AI、deep learning这套东西在蛋白质结构理论上取得了巨大成功?原因很简单,因为蛋白质结构已经有几十年的发展史,就是很多代的科学家做实验,他们累计了很多的数据。有个Datebase(数据库)叫PDB,protein database bank。正因为他们几十年的累积,提供了很多蛋白质结构的信息,才有可能让AI去学一把。所以这个蛋白质结构数据就建得比较好,这是数据驱动(data driven)的科学问题。
但世界上还有别的东西,还有生物材料,或者其他的各种东西,它就没有那么多的结构信息让AI去学。这个时候怎么办?AI还能起作用吗?这个问题AI就是做不到。你看Alphafold 2,不要说其他的生物材料,哪怕是蛋白质和核酸相互作用,或者蛋白质和小分子作用它也做不好。
这个方向朝前迈了不小的一步,但没有解决这个问题,不过这个方向是好的。所以,未来我相信,凡是生物学,哪怕包括化学,都会受到它巨大的影响。
今年2个诺奖给AI,下一步如何开辟未开垦的领域

某一个领域得了诺贝尔奖,这肯定是好事。为什么?这个领域受到了诺贝尔奖的肯定。我给你举个例子,今是2024年,它是给了AI。2013年,迈克尔·莱维特和我的博士生导师马丁·卡普拉斯,他们获得诺贝尔奖的时候,我们这个领域当然是非常振奋的。

在这个以前,计算生物学,尤其是像搞我们这种蛋白质结构计算的人,是不受待见的。什么意思?就是做实验的人是不把我们当回事,认为你这个东西没用,你们自己一群做理论的人,自己在那自娱自乐。确实是这么回事,是一个辅助性的学科。但他们2013年诺奖的成功,已经把计算生物学这个重要性显著地抬出来、抬上去了,但是还不够。

那现在Alphafold的成功,起初还没有获诺贝尔奖。就是前几年,它一下子让计算生物学从一个不太受人待见的、一个所谓的辅助性学科,而且它也比较难,因为它是个交叉学科,传统的学者、传统学生物的人做不了,传统学物理、数学的人又不懂生物,这确实是比较难。Alphafold的成功已经让计算生物学从一个所谓的辅助性学科变成了一个引领性科学,那现在诺奖已给(计算生物学领域),无论从AI算法本身,今年物理奖的肯定,又再加个化学奖,即在Science上的应用,那后面前途是无法估量。
当然了,你还可以反过来问这个问题:这个问题诺奖都给了,你还应该干什么?那不就没有创新了?这个也是一个很有哲学意义的问题。就是说,首先他被授予了诺奖,说明这个问题很重要,而且大家会大发展起来。但是那些领头羊们、要搞探险创新的人确实应该去想想,下一步未开垦的东西是什么?因为诺贝尔奖就不会给两次。
审核:梁前进 北京师范大学生命科学学院 教授
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司

来源: 返朴
内容资源由项目单位提供
