
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普江苏
科普江苏 随着ChatGPT、文心一言等AIGC(人工智能生成内容)工具的流行,AI(人工智能)技术已经悄然融入我们的日常生活,显著提高了我们的工作效率并丰富了我们的生活体验,同时也激发了我们的想象力和创新力。在这股AI 的技术浪潮中,AI 绘画技术凭借其带来的惊人创作成果,成了AI 领域的一个焦点。

那么,AI 绘画到底是什么?它具备哪些能力,又是基于何种原理和技术运作的呢?让我们进入AI 绘画的神秘世界里一探究竟!
AI 绘画解锁无限可能
AI 是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,也是新一轮技术革命和产业革命的重要驱动力量。在AI 技术的广泛应用中,AIGC 技术尤其值得关注。该技术基于先进的机器学习模型,通过分析和学习海量数据集,实现了生成文本、图像、视频和音乐等多种内容的能力。这不仅展现了AI 的创新潜力,还为内容创作者、设计师、工程师等专业人士提供了极大的便利和灵感。

AI 绘画作品
作为AIGC 技术的一个应用实例,AI 绘画已经在互联网和数字艺术界占据了显著位置。借助Midjourney、Stable Diffusion 和文心一格等平台,AI 绘画能够协助人们快速创作出大量高品质的图像作品。低成本、高可控性和高效率的特点,使其在教育、娱乐等多个生活领域扮演着重要角色。
米开朗基罗的话竟暗含AI 绘画的秘密
“雕像本来就在石头里,我只是把不需要的部分去掉。”
意大利艺术巨匠米开朗基罗的这句话是在描述他作为雕塑家的创作理念和方法,却也道出了AI 绘画的基本原理。AI 绘画的过程,从本质上来讲,是从一张含有大量随机噪声的初始图像出发,通过AI 的算法逐步去除“多余”的噪声,最终“雕刻”出清晰、具体的图像以满足特定的需求。这里的随机噪声,是指输入数据中的一种随机信息元素,犹如图片的噪点,它无法用一个明确的数学公式表示,在每次生成图像时会产生微小的变化,用于增加模型的多样性和创造性。
要理解这一过程,我们可以用AI 绘画工具Stable Diffusion 来进行解释。Stable Diffusion 的名字本身就隐含了它的工作原理,即“扩散”过程,其实也是训练过程。以《蒙娜丽莎》这幅世界名画为例,若我们将眼睛眯起来看,画面就会开始变得模糊,这正是AI 绘画中“前向扩散”(Forward Diffusion)的一个类比。在这一阶段,AI 通过分析模糊图像,学习并理解其形态特征,依靠深度学习从大量图像中提取特征数据,并与其文本标签相对应,构建起庞大的数据库。
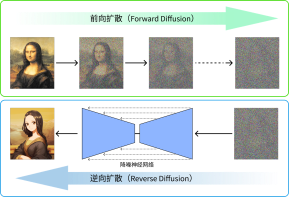
扩散模型的基本原理
当我们需要生成一张具有特定风格的蒙娜丽莎图像(比如动漫风格)时,训练好的神经网络便根据给定的提示词,在其数据库中检索相关特征,并开始“逆向扩散”(Reverse Diffusion)过程,即逐步减少图像中的噪声,以清晰化图像。通过这种方式,神经网络能够基于复杂的算法和庞大的数据集,将一张噪声图逐步转化为一张符合用户需求的清晰图像,就像是从石块中逐步雕刻出精美的雕像。
轻松开启AI 绘画的创意之旅
随着技术的进步和普及,AI 绘画的使用变得更加简单、直观。控制这一过程的核心在于向AI 提供一条精确的文字指令,即提示词。为了让AI 准确理解我们的需求,提示词中需要包含对图像主题、绘画风格以及图像参数的描述,描述越详尽,越有助于辅助AI 创作出符合预期的作品。
以Midjourney 这一AI 绘画工具为例,一条典型的提示词需要详细地描述图像的主体、风格、设定、组成、灯光等要素,还要设置图像参数。例如,你可以编辑如下提示词,“一幅小男孩在房间里读书的油画作品,小男孩穿着蓝色衬衫,背景为杂乱的房间、昏暗柔和的光线,正对视角,画幅尺寸为16:9”,就可以较好地指导AI 进行图像生成。
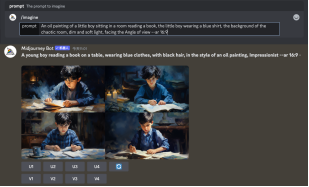
Midjourney 人工智能提示词(上)和图像生成界面(下)
根据提示词的指导,AI 将生成4 幅图像作为输出。界面上的“U”和“V”控件分别代表了放大输出和优化修改选项,每个按钮后的数字对应4 幅生成图像中的一幅。例如,如果第一幅图像符合需求,就点击“U1”,AI 将放大并输出该图像;若第二幅图像较为接近需求但需要进一步优化,则点击“V2”,AI 便会以第二幅图像为基础,再次生成4 幅图像。如果这一批次的图像仍不满足需求,用户可以通过调整提示词或点击界面右侧的循环按钮,指示AI 基于原始提示词重新生成4 幅图像。这些步骤构成了使用AI 进行图像生成的基本操作流程。
其他AI 绘图工具的操作也大同小异。在百度公司的AI 绘图工具文心一格中,用户同样只需要给出一条简单的提示词,同时在左侧的属性栏内设置好画幅比例、绘画风格、绘画模式等参数,直接点击“立即生成”,即可生成精美的图片作品。
AI 绘画可以变得更酷、更好玩
随着AI 绘画技术的持续迭代进化,一系列先进的生成方法和图像优化功能相继问世,极大地丰富了用户创作图像的方式和手段。这些功能不仅提高了图像生成的效率和便捷性,还赋予用户前所未有的能力来定制和优化他们的艺术作品,以更精准地满足个人的创作需求。还是以Midjourney 为例,我们来看看AI 绘画还可以怎么“玩”。
以图生图
当我们希望新创作的图片融合现有图片的某些元素时,可以将现有图片作为参考,连同提示词一并发送给AI。这样,新创作的图片就会在一定程度上反映出参考图片的特征。例如,我们有一张货船在江面上行驶的照片,并希望以油画风格重新诠释它,只要将这张照片和油画风格的提示词一起发送给AI,AI 便会以油画风格创作出全新的画作。

原图(左)与以图生图生成的图片(右)
图像混合
AI 可以将不同的图片(最多4 张)进行混合。AI 会先分析这些图片的内容和特征,然后将它们有机地结合在一起,创作出全新的作品。这个过程有时会带来一些出人意料的创意效果。例如,通过融合一张小男孩踢足球的照片和一张花园的照片,AI 能创作出一幅全新的画面,画中的小男孩在花园里踢足球。这幅新生成的图像能够保持小男孩与花园的原始特征,两个场景的结合也毫无违和感。

原图(左)与图像混合的生成结果(右)
局部重绘
AI 还允许用户对图像的特定区域进行细化或修改。这一功能极大地增强了对图像细节的控制能力,同时为创作具有创意的图像效果提供了可能。例如,若要在图像中的女孩脸部或头部添加新元素,如墨镜、口罩或安全帽,用户只需要利用此功能引导AI 对特定区域进行调整。如此操作,新添加的元素能够和谐地融入原始场景之中,确保整体图像的一致性和自然感。

原图(左)与局部重绘后的图片(右)
保持人物一致性
在AI 绘画领域,一直存在一个大问题,即AI 很难在多张图片中保持单个人物的一致性,这使得我们很难生成一些同一人物的连续性画面。然而,在最新的Midjourney 更新中,AI 已经可以根据我们提供的人物肖像以及提示词内容,在各种场景和动作姿势下保持生成人物的形象与参考图的一致性。这项功能的出现,让我们能够利用AI 来创作连环画、影视分镜甚至人物摄影作品。

原图(左)与AI 生成的连续性图片(右)
如今,AI 技术已经在影视、办公、医疗等领域得到了实际应用。在AI 的支持下,我们能够轻松地完成一些烦琐的工作任务,也能够轻易地将某些创意想法落实到现实中。尽管当前AI 绘画技术在可控性等方面仍面临挑战,导致实际输出结果与预期存在偏差,但是技术的迅速发展预示着它具有巨大潜力。AI 绘画正逐步成为艺术和设计领域的关键工具,为创意人士提供了探索新领域的机会。随着技术的持续进步,我们期待AI 绘画能够带来更高层次的创作能力,开创一个人类与AI 协作共创的新纪元!
文/姜斌、孟凡民 图/网络
来源: 科学大众
