
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普中国创作培育计划
科普中国创作培育计划 
作者 | 张文卓 前墨子号卫星团队成员
在2023年的上半年,量子计算领域尤其是超导量子计算方向取得了一系列重要的进展,先是谷歌初步实现了量子纠错技术,49个量子比特相比17个量子比特出现了更小的错误率。我国以南方科技大学为主的科研团队也成功展示了利用量子纠错技术延长量子比特的寿命。随后,IBM又演示了100多个量子比特的无需纠错的量子计算,祖冲之号也上线了176个量子比特的量子计算云平台。
那么量子比特和经典比特的区别是什么?量子纠错的意义有多大?量子比特会像经典比特一样遵循摩尔定律指数级增长吗?
量子比特是量子计算机处理的最小信息单元,也是最简单的一个量子叠加态。在数学上看,量子比特可以在一个复数空间的Bloch球面上取任意点。相比,经典比特只是这个球面上0和1两个点。
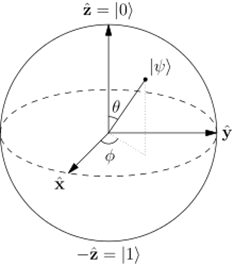
Bloch球面
因为经典比特在Bloch球面上是距离最远的两个点,所以想反转一个经典比特需要消耗一定的能量,经典比特相对稳定。但是对量子比特来说,它的取值在Bloch球面上是连续的,非常小的能量就可以让它在Bloch球面上移动,改变它的取值。因此量子比特对周围环境极其敏感,也极容易出错。在量子计算进行过程中,量子比特这种随时发生的错误会导致计算结果不可靠。
因此我们需要一种让量子比特在Bloch球面上保持不动的技术,这就是量子纠错。简单地说,量子纠错就是用大量的物理上的量子比特去维持一个逻辑上的量子比特不变。通过对大量物理量子比特的测量,得到错误的概率,即知道逻辑量子比特在Bloch球面上移动了多少。由于物理量子比特一被测量就会被破坏,所以要牺牲掉很多量子比特,然后对剩下的量子比特做操作,让其代表的逻辑量子比特恢复到Bloch球面上正确的位置,这就是一轮量子纠错。
一般情况下,能完成一次完整的量子算法,需要约1000个物理量子比特来维持一个逻辑量子比特。用量子计算Shor算法去破解一个1024位的大数分解,至少需要2048个逻辑量子比特,那就意味着物理量子比特的数量要乘以1000,即两百万个,才能实现量子纠错,得到正确结果。这就是为什么量子计算机离我们依然十分遥远。
以上指的都是通用量子计算机,即可以任意编程,跑任何量子算法。因为百万量子比特的目标太过遥远,所以现在量子计算机的研究瞄准的都是眼前不需要量子纠错的方向,我们称之为专用量子计算,或量子模拟。谷歌早些年实现的“量子称霸”指的就是特定问题的专用量子计算超越最快的经典计算机。
我国的九章号就是实现“量子称霸”专用的量子计算机,它不需要量子纠错,甚至连量子比特的不需要,但可以通过光子自身的玻色子性质比经典计算机快出上亿倍的速度完成玻色采样算法。不久前九章号通过该算法求解了一个图论问题。
无论是通用量子计算机还是专用量子计算机,增加一个量子比特或者量子态的难度都是指数上升的,因为新增的量子比特或者量子态要和之前所有的量子比特或者量子态产生关联。例如通用量子计算机,每增加一个逻辑量子比特,就要具备和之前任意一个逻辑量子比特产生量子纠缠的能力,从而实现量子逻辑门。可以说,每增加一个逻辑量子比特,或者说每增加1000个物理量子比特,量子计算机的难度都要乘2。专用量子计算机每增加一个量子态的难度也接近乘2。
相比之下,经典比特的在集成电路里由微小的晶体管承载,晶体管之间的连接构成逻辑门电路。晶体管相互之间没有任何依赖,可以批量的复制,因此可以实现摩尔定律的指数增长,即每18个月单位面积上的晶体管数量翻一番。
简单地说,经典比特的增长难度是线性,于是指数级的摩尔定律会让经典比特指数增长。相比,量子比特的增长难度本身就是指数的,那么即使是指数级的摩尔定律,也只会让量子比特的数量线性增长。这非常符合实际情况,每一年,通用量子计算机的量子比特数提高10-20个左右,注意只是物理量子比特数量的提高,至今还没有通过量子纠错实现一个完整的逻辑量子比特。而不需要量子纠错的专用量子计算机,量子态数量的增长可能快一些,但也难逃线性增长的规律。
总之,量子比特确实有它指数增长的摩尔定律,但这个摩尔定律已经体现在了增加量子比特的指数级难度上,于是最终的结果就是量子比特数量的线性增长。所以尽管经常能看到量子计算机的新闻,但都只是科研上的进展。真正能解决问题,带来生产力提高的量子计算机还遥遥无期。
本文为科普中国·创作培育计划扶持作品
作者:张文卓
审核:罗会仟 中科院物理所研究员
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司

来源: 星空计划
内容资源由项目单位提供
