
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 北京建筑大学科协
北京建筑大学科协 机器人步态算法补充--强化学习与足式机器人
作者:邢伯阳
1、强化学习概述
随着Google DeepMind发布AlphaGo Zero后强化学习技术成为了近年来的热门研究领域。不同于上一代主要依靠监督学习的AlphaGo,AlphaGo Zero单纯依靠强化学习实现自我对弈,算法从零开始通过奖励信号进行策略迭代。作为一个通用的算法其不仅可以学习如何下围棋,还可以学习下国际象棋和日本将棋,这是史上第一次出现用单一算法来破解象棋和围棋的算法,也是强化学习发展史上的里程碑式。
强化学习是机器学习的一个分支,与有监督学习和模仿学习不同强化学习完全依靠由动作产生的反馈数据对策略进行优化,因此其在一定层面上也与目前的优化控制理论相关。以运动规划和随机规划为例,它们的目的都是基于目标函数(奖励或代价)寻找一个最优控制器或控制策略,然而在最优控制理论中往往需要知道系统精确的模型和约束,而强化学习则通过不断与环境交互试错实现达到相同的目的。
机器人是强化学习目前主要的应用领域和研究对象,其具有连续的状态和动作空间并且具有很高的自由度,所采用的传感器系统还存在着噪声和偏差,这些都为强化学习的应用带来了很大的挑战。同时,由于强化学习需要不断试错才能学习到有用的信息,随意性的控制输出对于真实的机器人来是十分危险的,因此目前主要借助计算机仿真技术完成对智能体的初步训练然后再向实际机器人中进行部署,但仿真引擎的误差和系统建模误差都会造成最终训练的结果与实际系统中截然不同,特别是对于高动态系统来说。
综上,强化学习技术相比传统控制理论来说原理简单,主要依靠数据驱动的方式实现控制设计,降低了理论和算法的难度,但目前的算法还存在着许多的不足,特别是在向真实机器人系统部署时面临着软件和硬件上的挑战。
2、强化学习算法研究现状
最优控制已经成为高性能、高动态和高效机器人的核心技术,其也被视作是强化学习的前身。最优控制方法通过高斯过程(GP)或贝叶斯网络(BN)等工具针对具体问题建立模型,从而来节省智能体与环境交互的成本。目前常用的最优控制算法有模型预测控制(MPC)、线性二次调节器(LQR)、线性二次高斯(LQG)和迭代学习控制(ICL)等;而强化学习属于数据驱动的方法,算法通过大量反馈数据估计系统状态与动作间最优的回报函数即最优动作策略。
如图1所示,强化学习目前算法可以划分为基于模型方法(Model-based)与无模型方法(Model-free)。两个算法的区别主要是是否为智能体提供模型,拥有模型能帮助智能体预测未来的系统状态并提前规划,但现实中无法建立系统的精确模型,而建模误差会导致在仿真中智能体表现的很好,但是在真实环境中达不到预期;Model-free强化学习是目前的研究热点,其不需要建立系统模型因此更容易实现,相对简单直观,开源实现丰富,比较容易上手,从而吸引了更多的学者进行研究。目前许多知名研究团队提出了DQN、PG、AC、A3C、DDPG、TRPO、PPO等优秀的强化学习算法。

在强化学习中,智能体尝试去最大化自己的奖励函数,以机械臂控制其状态为的当前手臂末端位置或关节角度,控制命令为关节的转矩,则强化学习的目的即最快、最精确地控制末端移动到期望位置,并以此为奖励函数训练智能体。可见,强化学习实际上是寻找了一个系统状态和动作映射(策略)来最大化智能体获得的奖励。传统的强化学习算法主基于马尔科夫链(MDP,下一时刻状态和奖励与当前状态与智能体的行为有关),其中最经典的就是Q-Learning算法。Q-Learning通过建立离散系统状态与行为的Q值表,基于贪婪算法不断更新获得奖励行为的权重,最终实现智能体快速自主地完成任务。针对Q-Learning目前提出了许多改进算法来提高获得长期奖励回报的能力,如Sarsa和Sarsa-Lamda等。可是,在实际机器人中系统状态往往是连续的,而如要采用Q-Learning算法需要对其状态和行为空间进行离散化,但随着维度的增加离散化后的工作空间会变得异常的巨大,许多机器人系统离散化后涉及的状态和行为的维数以百万计,而对每个状态行为进行价值(如人的满意度)计算也非常困难。
回顾强化学习的发展历史免模型算法只占很少一部分,但基于历史原因当前深度神经网络的免模型方法却得到了快速的发展。DQN(Deep Q-Learning)是拉开深度强化学习大幕的开山之作,其采用深度神经网络近似Q-Learning中离散的值函数,从而解决了连续状态空间问题,并进一步采用经验回放技术在每轮任务后随机抽取一些之前的经历进行学习,打乱了数据之间的相关性并解决其非静态分布问题,从而使得神经网络更新更有效率。
对于神经网络训练来说其最难以克服的就是过拟合问题,由于DQN使用贪婪策略使得次有和最优行为更新权重是一致,因此导致了估计误差随智能体行动次数增大而上升,最终导致次优行为的权重超过最优行为即策略陷入局部最优。因此研究人员进一步提出了DDQN(Double-DQN )改进算法,通过对神经网络模型结构修改将网络拆分为两部分,一部分只与状态相关另一部分同时与状态动作相关,通过将动作的选择和评估解耦开有效提高了智能体的学习效率和全局最优学习性。
上面介绍的几类方法主要通过构建行为、状态与奖励的值函数实现强化学习,但往往只能处理离散的动作集合,不能处理连续的动作集合,而在深度强化学习还有另一类算法基于策略为核心来较好地解决这个问题。策略强化学习方法中使用连续策略函数实现了连续动作输出,因此研究人员将值函数和策略方法向结合提出了演艺家和评判家(Actor-Critic,AC),实现了端到端的强化学习并能应对连续状态和连续动作空间的任务,同时通过引入值函数方法也解决了传统策略方法中回合更新带来学习速率较慢的问题,同时AC方法中两个子系统均可以使用深度神经网络来代替以提高学习效率。在DQN中采用经验回放的方式有效解决了网络过拟合的问题,但要求智能体只能离线学习,因此研究学者提出了A3C(Asynchronous Advantage Actor-Critic)异步学习的改进算法,采用多线程的方式实现多个智能体同时学习更新策略,采用并行化的方式直接来解决数据相关的问题取代经验回放,在节省记忆库存储空间开销的同时提高了网络收敛性、加快了训练速度。
虽然A3C较好地把策略方法和值函数法结合了起来并做到了单步更新,但由于采用并行训练导致其方差较大,无法保证每次训练后新策略回报的单调上升,因此研究人员进一步提出了回顾策略梯度(Trust Region Policy Optimization,TRPO)算法,其利用KL散度来限制新旧策略之间的距离,并且修改了目标函数保证训练回报能单调上升。
TRPO虽然保证了训练回报的单调不减,但是惩罚函数中的超参数需要采用约束优化的范数求解并且结果存在着近似误差,因此研究人员提出了(Proximal Policy Optimization,PPO)方法。PPO同样基于AC框架,对于TRPO中难以确定的超参数其直接使用对步长进行限制的方式来代替,另外目前还有一种新的改进方法PPO2采用更复杂的步长限制方法,在实验中PPO2取得了更优异的结果,其目前也成为OpenAI所推荐的深度强化学习算法,并在许多研究中得到应用。
在强化学习算法训练中往往仅依靠一个总体的奖励函数指导智能体学习,这也使得机器人在完成一个复杂任务时很难精确的对各中性能指标进行针对性的训练,因此研究人员提出了分层式强化学习(HRL)框架。HRL从策略的多个图层中学习,每一层都负责控制不同时间下的动作。策略的最下一层负责输出环境动作,上面几层可以完成其他抽象的目标。针对复杂任务传统强化学习算法主要通过长期信用分配和稀疏奖励信号的方式进行训练,而在HRL中由于低层次的策略是从高层次策略分布的任务所得到的内部奖励学习的,即使奖励稀疏也可以学到其中的小任务。另外,高层次策略生成的时间抽象可以让我们的模型处理信用分配,最终实现更高效的学习。
综上,无模型强化学习方法具有非常好的通用性,其主要研究内容集中在如何能保证智能体能获得长期的奖励回报,因此研究人员在学习模型和回报函数上做出了许多的改进,并提出了相应的改进算法。通过引人深度神经网络实现对值函数的高精度逼近和智能体记忆的存储,最终提高了强化学习的性能也使得其性能远远超过传统的控制理论,但强化学习本身可以看做一个黑盒其网络收敛性的理论证明仍待完善,同时网络训练的时间成本较大,需要进一步研究与传统模型理论相结合方法。
3、强化学习应用难点与解决方案
如前文所述强化学习在实际机器系统中的部署仍面临着很多挑战,目前其应用的主要难点如下:
(1)训练模型误差:针对连续状态和动作空间的强化学习问题研究人员已经提出了如DQN和AC等算法,并且在仿真中获得了不错的效果,但是在向实际机器人中部署时由于建模误差和执行器滞后造成智能体做出的行动与得到的反馈不一致,这直接打破了MDP的假设。
(2)状态反馈存在误差:在向真实机器人系统部署时许多状态信息都需要使用相应的传感器进行测量,其测量数据往往存在着噪声或者偏差,甚至有一些状态是无法测量的,而此时需要基于系统模型使用状态估计理论得到对应的估计值,这些误差都增加了训练结果的误差。为获取高精度的机器人反馈数据目前基于动态捕捉的系统被广泛采用,其已经被用于为无人机在室内提供精确的位姿数据,并作为如MPC或自学习等控制算法的反馈数据。
(3)训练样本少:不同于使用深度学习的图像识别算法,其能轻易获取上百万的训练样本,由于强化学习需要智能体与环境交互因此其学习成本十分昂贵,训练中往往只能获得数量较少的样本,另外样本往往也无法激活系统的所有的模态如机器人在运动过程中可能出现的疲劳和损坏或目标物环境的破坏,这些参数的变换都会造成截然不同的训练结果,为解决这个问题目前的强化学习主要借助于计算机仿真技术来降低样本的获取难度。目前的虚拟软件不但能模拟机器人的完整运动特性,如有几个关节、每个关节能如何运动等,还能模拟机器人和环境作用的物理模型,如重力、压力、摩擦力等。机器人可以在虚拟环境中先进行训练,直到训练基本成功再在实际环境中进一步学习。考虑到仿真软件仍然和实际机器人有误差,在训练中研究人员通过引入噪声或在一定程度上增加模型的不确定性来提高系统的泛化能力。
3、强化学习在足式机器人中应用现状
强化学习虽然不需要明确的系统模型并且能从反馈中学习到复杂的技能,但往往需要大量的调试和训练时间,由于网络输出具有随机性目前的许多强化学习应用主要还是停留在仿真环境中,并且实验场景可控、反馈数据明确易于获取,如AlphaGo实现的下棋博弈或如OpenAI完成的电子游戏等。对于机器人来说如果让其无约束地在物理空间中进行学习不但可能造成自身电气设备的损坏,严重的时候甚至会对实验人员造成人身伤害。
目前成功将强化学习技术应用在实际机器人系统中的研究成果较少,其中较成熟的案例是使用强化学习完成机械臂的抓取控制,另外也有研究学习成功将强化学习应用于无人机端到端视觉导航(如无人机视觉避障或地标降落),但上述方法中强化学习往往仅在顶层进行控制如为无人机规划飞行的轨迹或者机械臂抓取的轨迹,而直接对机器人本体的控制如姿态控制或伺服控制的案例较少,而对于足式机器人来相关的研究更是在近年来才有据可查。
Tan J等人提出了一种端到端的足式机器人强化学习系统,解决了传统足式机器人步态算法设计复杂和参数调节困难的问题。为加快网络的收敛其首先提供了一个开环的步态信号让机器人在虚拟环境下进行学习,通过建立精确的电机模型并且增加仿真延时来解决向实际机器人系统中的滞后,同时在仿真环境中为增加了模型的随机扰动来提高模型的泛化能力,最终其实现了四足机器人Trot和Gallop步态的学习并成功在真正机器人系统中部署,论文中使用PPO网络完成了网络的训练,系统状态为机器人关节角度和IMU测量姿态数据,最终输出期望的电机角度,而奖励函数则希望能最大化机器人的移动速度。

Singla A等人同样基于强化学习来实现对四足机器人步态的学习,为降低网络训练的复杂度他引入了 kinematic motion primitives (kMPs) ,最终通过PPO算法训练神经网络实现了对Trot和Gallop步态的学习并在实际机器人中进行了实验。通过kMPs结合主成分分析减少了训练所需迭代的次数,使得机器人能从少量参数动作中还原出完整的足端轨迹,由于最终的步态执行使用轨迹跟踪控制,降低了系统实际部署的难度,但无法引入力控和柔性控制技术使得该系统仅停留在小型机器人上。

Xie Z等人最终采用强化学习技术在双足机器人上进行了测试,提出了一种新的训练方法使得机器人在学习新步态的同时不会对已有的技能产生遗忘,其采用 实现了仅需要较少的训练样本就能达到有效学习的目的,同时将有监督学习与强化学习向结合,使用以收敛的策略作为参考通过增加新的奖励函数来学习新的技能,这样有效地保证了复杂任务学习的安全性和学习效率。最终,文献中提出的算法实现了在不需要如前面几个方法中主要增加模型随机扰动下就完成了部署,最终机器人在实现跟踪期望移动速度命令的同时还能抵抗一定的外力扰动。

Hwangbo J等人提出了一个目前结构最完整并且效果最好的足式机器人强化学习算法,其完全基于强化学习实现四足机器人本体步态控制,实验结果验证该方法相比基于模型的传统控制算法在提高机器人移动速度的同时降低了能耗,在应用于机器人倒地自恢复这种复杂策略的任务时,基于所提算法实现了100%成功率的自恢复站立。为减少执行器、数据通讯和减速组带来的模型非线性和反馈滞后,构建了单独的神经网络对执行器进行有监督学习,较好地估计出在增加减速组后驱动器的力矩输出。同时,增加了一个关节记忆存储网络来帮助检测机器人腿部触地,最终采用TRPO算法作为学习策略。考虑到动作空间为力时会增加网络训练的维度和复杂度,其采用了顶层机体移动命令到关节角度位置输出的端到端方案,并且在仿真环境中为机器人和环境增加模型不确定度以增加系统的泛化能力。为提高训练的效果其提出了一种难度层级训练方法,即由最容易的站立平衡到机器人快速移动设定不同难度目标的任务对同一神经网络进行训练,同时引入难度因子来更好的训练网络。该论文中提出的系统给出了一个未来强化学习的应用前景,仅需要保证机器人自身反馈数据和执行器的可靠就能在少量人工介入的情况下,快速自动化地完成复杂机器人控制器的设计,着相比传统模型控制理论的方法大大降低了研发的难度。
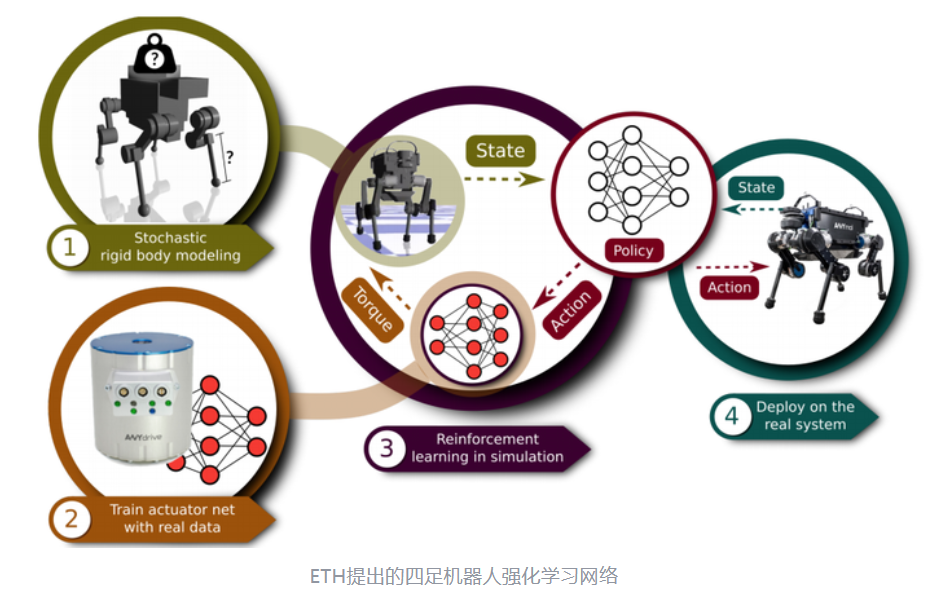
上述的相关研究人员在实验中均未将机器人在复杂地形下进行测试,虽然在平地上大多数算法都获得了较好的移动性能并能抵抗外力干扰,但仍然难以被复现。如Hwangbo J等人使用了一个非开源的虚拟仿真环境,其相比现有软件具有更优异的物理仿真性能,另外上述的算法大多输出的是关节角度命令,因此需要执行器具有较高的控制精度,针对不同的任务仍需要重新训练神经网络,并且要获取高性能的步态除了需要花费较长的时间在仿真中对模型参数进行调整外还需要经历多的训练时间。
4、总结
目前,强化学习技术的发展遇到了一定的瓶颈、应用范围仍难以进一步推广。相关的核心研究成果主要以国外的团队为主,很多工作内容仅有论文内容支撑而要复现这些工作十分的困难,第一是由于强化学习对代码和算法的调试很多情况下只能等待智能体与环境交互才能验证模型和奖励函数的设计是否合适,时间成本较大;另外,当向实际机器人系统中部署时的设备成本较高,除了可能造成的物理损坏外,训练结果的长期可靠性也无法保证。可见,目前强化学习在足式机器人中的应用特别在对本地步态算法层面上仍然需要技术难点进行图片,但采用强化学习在顶层为足式机器人进行规划控制缺是一个能快速落地的方向,如基于深度相机的端到端自动驾驶和自主避障都是一个不错的方向,而采用传统算法往往需要复杂的逻辑采用强化学习通过在不同环境下自主试错学习能获得比人工设计算法更全面和可靠的逻辑,同时由于其为顶层控制机器人自身的稳定性得以保证可以结合传统的算法进行切换融合,综合二者的优势。
来源: 北京建筑大学邢伯阳老师
