
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 重庆市科学技术协会
重庆市科学技术协会 
在当今数字化的世界里,我们面对的信息量越来越大,如何从这海量的信息中找到我们需要的知识呢?或许有一种神奇的技术,可以让数据变得"有灵魂",像一座无所不知的魔法图书馆,那就是——知识图谱!
你可能会好奇,知识图谱到底是什么呢?其实,它就像是一张巨大的网络地图,里面充满了各种各样的知识点。比如,它知道什么是大熊猫,知道大熊猫吃什么,还知道大熊猫和其他动物之间的关系。这些知识点之间还会相互连接,构成一个庞大而复杂的知识网络。
那么,知识图谱是如何工作的呢?首先,它需要"读取"大量的信息,就好像在收集各种各样的书籍一样。然后,它会对这些信息进行整理,找出它们之间的关系,就像是把书中的章节和段落归类整理一样。接着,它会通过一些魔法技巧,像是一个聪明的图书管理员一样,根据用户的需求提供相关的知识,让我们轻松地找到我们想要的答案。
知识图谱可以应用在很多领域,比如搜索引擎、电子商务、医疗健康等。在搜索引擎中,它可以帮助我们更快地找到我们想要的信息;在电子商务中,它可以根据我们的兴趣为我们推荐适合的商品;在医疗健康领域,它可以辅助医生做出准确的诊断和治疗方案。
所以,知识图谱就像是一座神奇的魔法图书馆,它让我们能够轻松地获取各种各样的知识,帮助我们更好地理解这个世界。

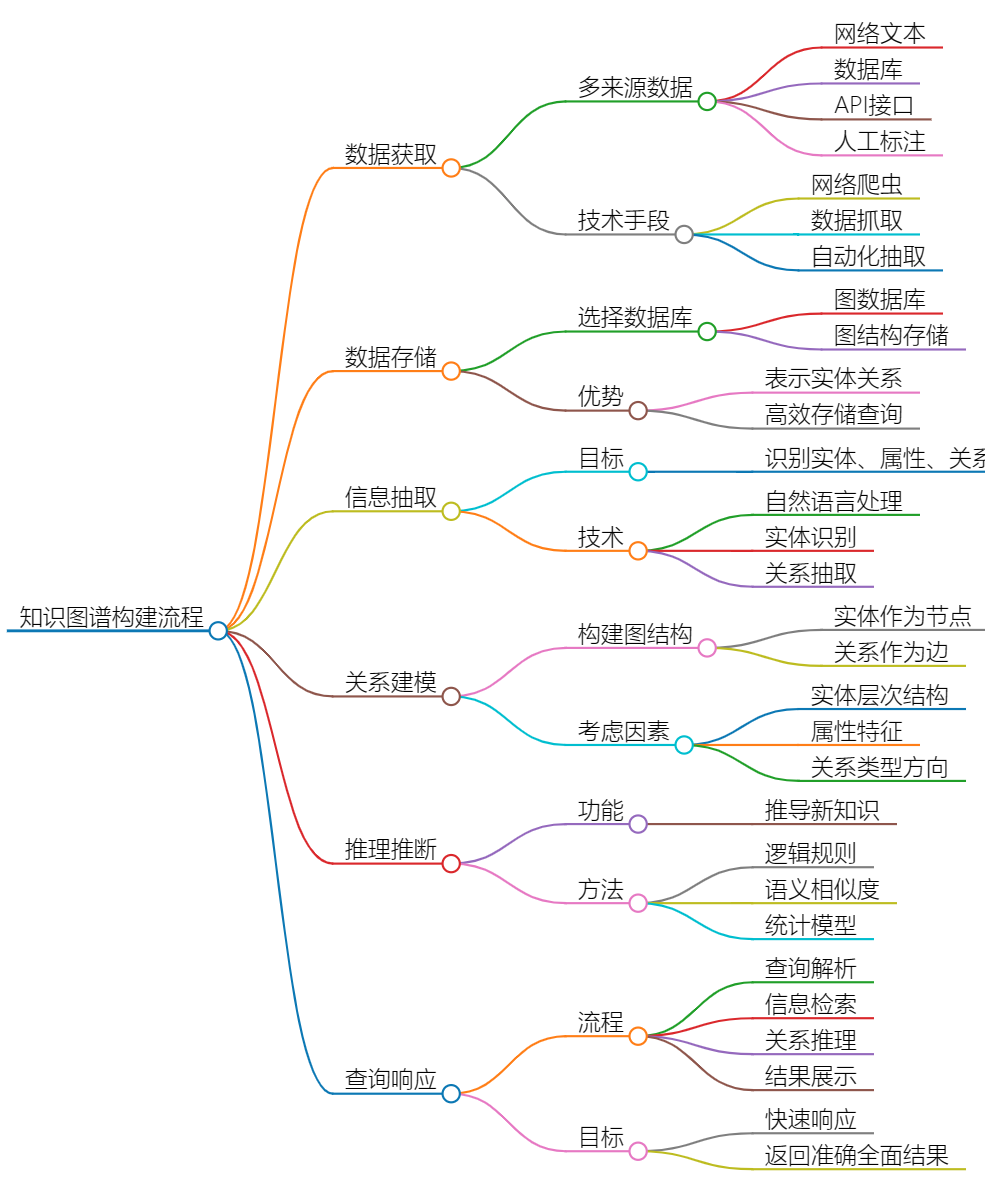
知识图谱的工作原理涉及多个方面,包括数据获取、数据存储、信息抽取、关系建模、推理推断和查询响应等环节。以下是知识图谱的详细工作原理:
数据获取:知识图谱的构建首先需要获取大量的结构化和半结构化数据。这些数据可以来自各种来源,包括网络上的文本、数据库、API接口、人工标注等。数据获取的过程可以采用网络爬虫、数据抓取、自动化抽取等技术手段。
数据存储:获取的数据需要被存储在合适的数据库中,以便后续的处理和查询。知识图谱通常采用图数据库或图结构存储数据,因为图结构能够很好地表示实体之间的关系。图数据库可以高效地存储和查询大规模的图数据。
信息抽取:在将数据存储到知识图谱之前,需要对数据进行信息抽取,将文本或半结构化数据中的实体、属性和关系识别出来。信息抽取的技术包括自然语言处理、实体识别、关系抽取等,可以根据领域特点设计相应的抽取规则和模型。
关系建模:抽取出的实体、属性和关系需要被建模成图结构,形成知识图谱的基本框架。在建模过程中,实体被表示为图中的节点,而实体之间的关系则被表示为图中的边。关系建模的过程可以根据具体的领域知识和需求进行,可以考虑实体的层次结构、属性特征以及关系的类型和方向等。
推理推断:知识图谱不仅存储了实体和关系的静态信息,还可以进行推理推断,根据已有的知识推导出新的知识。推理推断可以基于逻辑规则、语义相似度、统计模型等方法实现,可以用于填补知识图谱中的空白、发现潜在的关联关系以及解决推理问题等。
查询响应:当用户提交查询请求时,知识图谱需要能够快速响应并返回相关的查询结果。查询响应的过程包括查询解析、信息检索、关系推理和结果展示等步骤,以确保用户能够获取到准确、全面的查询结果,并帮助用户理解和利用知识图谱中的知识。
假设有一个名为"生物知识图谱"的系统,用于存储生物领域的知识,包括各种生物实体、它们的属性以及它们之间的关系。这个系统被设计为帮助用户查询和理解生物学领域的知识。
案例:查询动物的食物链关系
用户查询:用户想要了解大熊猫在食物链中的位置。
查询解析:系统接收到用户的查询后,首先进行查询解析,将用户的意图转化为系统能够理解的形式。系统分析用户查询的关键词,如"大熊猫"、"食物链",并将其转换成一个查询请求,以便在知识图谱中进行检索。
信息检索:系统根据查询请求在知识图谱中进行信息检索。它首先找到"大熊猫"这个实体,并检索与之相关的属性和关系。然后,系统根据大熊猫的食性属性,寻找其食物链关系。系统可能发现大熊猫是一种食草动物,主要以竹子为食。接着,系统检索与竹子相关的信息,如竹子的生长环境、特性以及与其他生物的关系。
关系推理:系统利用知识图谱中存储的关系和规则进行关系推理。它根据大熊猫食草动物的特性推断出大熊猫在食物链中的位置。系统可能得出结论,大熊猫处于食物链的高层次,它们的食物链顶端是竹子,而在食物链中的下一级可能是食肉动物,如狼、虎等。

结果展示:最后,系统将查询结果以可视化的形式呈现给用户。它可能展示一个食物链的图表,清晰地显示大熊猫与其食物和食肉动物之间的关系,帮助用户更直观地理解大熊猫在食物链中的位置。
通过这个案例,可以看出知识图谱系统如何根据用户查询,利用存储的知识、关系推理和结果展示等步骤,为用户提供准确、全面的查询结果,并帮助用户更好地理解生物领域的知识。
供稿单位:重庆市无线电科普体验中心
审核专家:杨耀辉
声明:除原创内容及特别说明之外,部分图片来源网络,非商业用途,仅作为科普传播素材,版权归原作者所有,若有侵权,请联系删除。
来源: 重庆市科学技术协会
