
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 HyperAI超神经
HyperAI超神经 
在合成生物学领域,研究人员将来自其他生物体的酶基因导入某种宿主体中,构建起新的代谢途径,可以让宿主生产出自己本身不能合成的物质,这一点已被证实并广泛应用于生物燃料、高价值化学品和抗癌药物等化合物的生产中。
然而,上述的代谢途径进化过程并非畅通无阻,一个重要的制约因素便是基因上位效应。
遗传学家 Daniel Weinreich 曾表示,基因上位效应类似于已知单个突变作用时,组合突变却产生「意外之喜」。具体来讲,上位基因可以抑制某个特定基因的功能性表达,这使得一些有助于优化代谢途径的基因突变无法发挥作用,造成代谢途径进化的不确定性。
自然状态下,由于基因上位效应的存在,一个酶的微小改造可能会使另一个酶阻碍代谢途径的发展,导致代谢功能增强或新功能挖掘需要经历较长的周期。因此,如何以更短时间、较少迭代次数快速达到数千年自然进化所需的效果,一直是该领域研究的难点。
针对上述问题,中国科学院深圳先进技术研究院合成所罗小舟团队利用自动化大设施平台技术,确定可控的进化轨迹,实现了代谢通路多个关键性基因的自动同步进化。同时,结合 ProEnsemble 机器学习框架来优化启动子组合,缓解进化途径中基因上位效应的影响,创造了一个高效的通用型底盘。
研究亮点:
* 融合自动化和机器学习的优势,提高底盘开发的速度和效率,缩短研发周期,降低成本。
* 为生物智能制造领域提供了前沿的技术路线和全新的解决方案。

论文地址:
https://onlinelibrary.wiley.com/doi/full/10.1002/advs.202306935
关注公众号,后台回复「代谢途径」获取完整 PDF
自动化平台加速代谢途径同步进化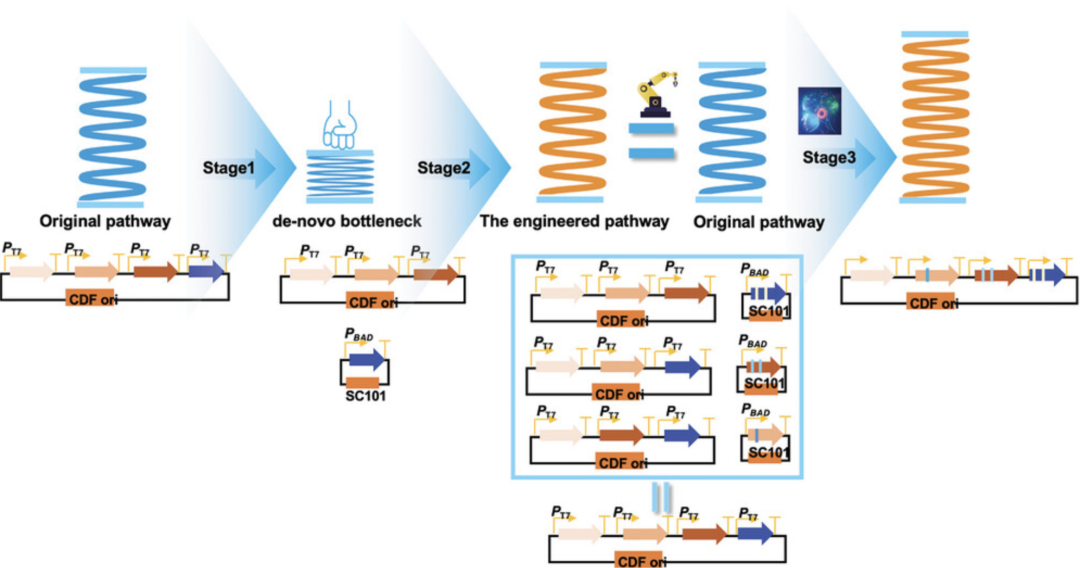
通路瓶颈设计与解除策略的三个阶段
本研究提出了一种通路瓶颈设计与解除策略的方案,以柚皮素为例:
第一阶段,搭载自动化大设施平台技术,让合成柚皮素的相关基因低水平表达(低拷贝数背景),构建一个柚皮素合成的人工代谢瓶颈。
第二阶段,筛选与原始突变体柚皮素产量相当的候选突变体 4CL-11C1 和 CHS-9H9,消除柚皮素途径的瓶颈。
第三阶段,通过人工智能介导的启动子工程,将单个基因的突变体放回原始通路并平衡代谢流。
研究结果表明,在清晰轨迹的范围内,人工瓶颈创造与解除策略可实现代谢途径的高效进化,也进一步证实了上位效应可能会限制途径进化的边界。
此外,对柚皮素关键基因所对应的三种酶进行定向进化可能会诱发代谢途径失衡。对此,研究人员借助机器学习框架 ProEnsemble 来优化进化通路的启动子组合,进一步优化每种途径酶的表达,提高柚皮素的产量。
数据集:历史公开数据筛选
数据集1:研究人员从文献资料中筛选出 42 个具有广泛动态范围的已报道启动子,最终筛选了 12 个强度差异显著的启动子,并将它们分为高强度、中强度和低强度三类。
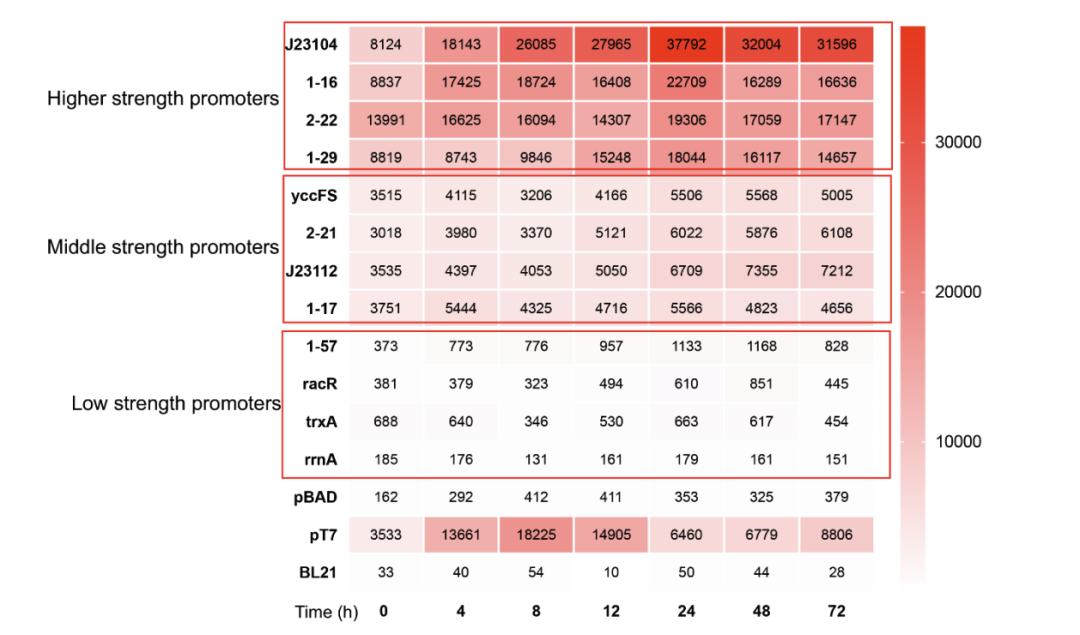
用于激活TAL-26E7, 4CL-11C1, CHS-9H9和CHI基因的12个候选启动子的表达强度水平;
PT7启动子为阳性启动子,PBAD启动子为阴性启动子
数据集2:研究人员通过 Al3+ 信号检测法筛选了大约 1,000 个能够产生高柚皮素浓度的突变体,并从中收集了一个平衡数据集。随后,选择了其中 108 个 Al3+ 信号高于 0.2 的突变体作为高产代表,又随机挑选了 50 个 Al3+ 信号低于 0.2 的样本,共 158 个突变体。其中,Top1 的 NAR1.0 菌株柚皮素产量比对照组高出 4.44 倍。
模型架构:ProEnsemble 优化启动子组合
研究人员提出了一种名为 ProEnsemble 的启动子组合预测框架,该框架旨在建立不同启动子组合与柚皮素产量之间的关系,即将 12 种不同类型启动子编码,对应的输出是柚皮素的产量。
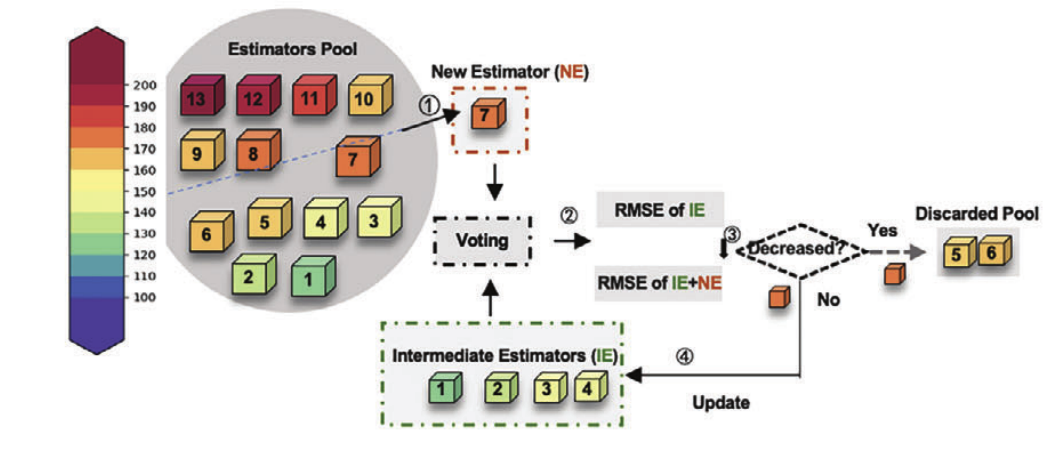
ProEnsemble 模型方案
具体来说,通过对上述包含 158 个突变体的数据集进行十折交叉验证,评估 13 种常规预测器的均方根误差 (Root Mean Square Error, RMSE)。
随后,通过前向模型选择,将误差最小的预测器依次进行集成,选择 RMSE 最小的集成模型作为最终的预测模型。最佳模型是 Gradient Boosting Regressor, Ridge Regressor 和 Gradient Boosting 的组合。
研究结果表明,该 ProEnsemble 模型预测的 Top5 菌株柚皮素产量均高于 700 mg/L,比随机采样(960 样本有 5 个高产菌株)更具高效性和准确性。
但是,该数据集的不平衡分布可能会限制模型的预测能力,导致 Top5 菌株产量均未超过 NAR1.0 菌株。
模型优化:平衡分布数据,增强模型性能
研究人员重新从另外 1,500 个克隆子中进一步扩大训练集,分别用柚皮素含量高于 400、500、600、700 和 800 mg/L 的数据集优化模型。
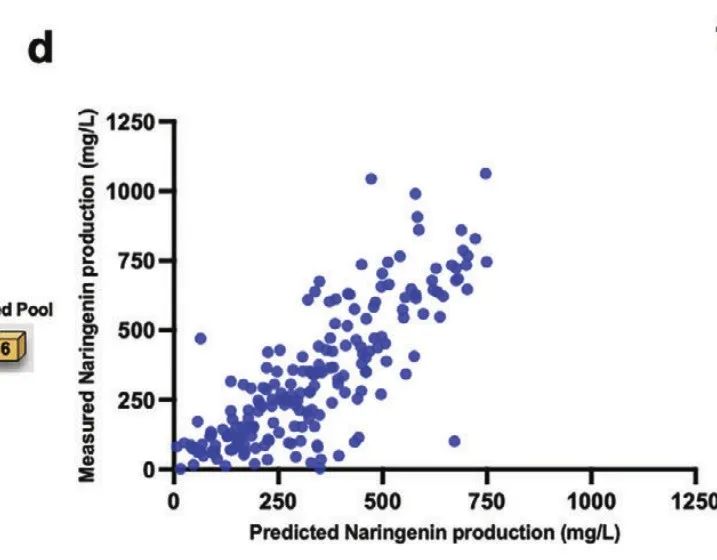
柚皮素测定值与最优预测模型预测值的 PCC
最终,在初始数据集中增加 27 个高于 600 mg/L 的数据集后,模型表现最佳,Pearson 相关系数 (PCC) 从 0.74 提高到 0.82,结果表明数据集平衡分布对增强模型性能的重要性。
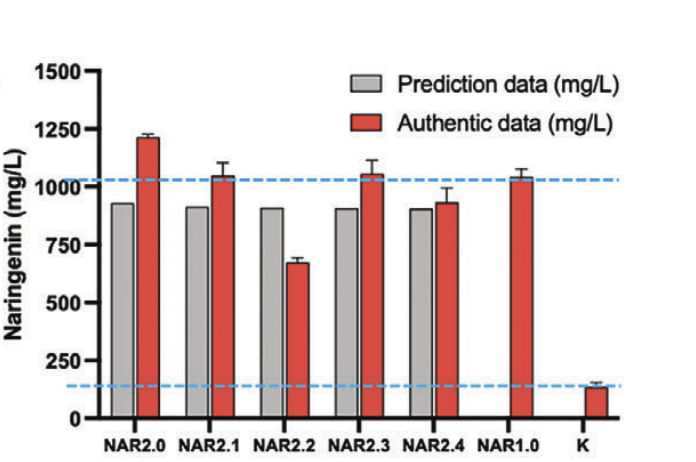
不同菌株中的柚皮素产量
通过检测不同菌株中的柚皮素产量,研究人员发现第二轮预测的 Top5 菌株均能高效合成柚皮素。最高产的 NAR2.0 为 1.21 g/L,比 NAR1.0 高出 16%,比未经启动子优化的初始构建体高 5.16 倍。
值得注意的是,随机启动子库中超过 99.11% 的菌株产量低于 1g/L,这表明 ProEnsemble 集成模型具有挖掘高产菌株的可能性。
实验结论:通用型底盘高效合成黄酮类化合物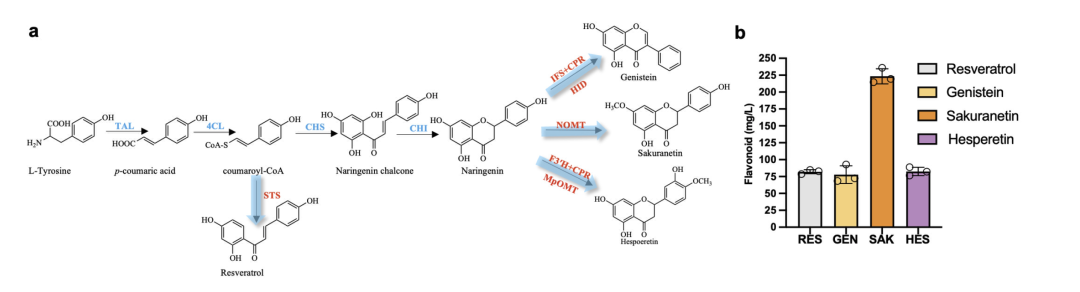
柚皮素底盘高效合成下游黄酮类化合物
为了进一步验证该研究所提方案的可行性,研究人员通过柚皮素底盘实现了染料木素、樱花素和橙皮素等黄酮类化合物的高效合成,其中染料木素产量达到 72.32 mg/L,樱花素产量为 223.39 mg/L,橙皮素产量为 82.50 mg/L,各黄酮产量均高于文献报告水平,这为生产高附加值化合物提供了新的思路。
中国的合成生物产业仍处于初级阶段
近年来,欧美等发达国家纷纷采取措施推动合成生物学及其相关制造业的发展,我国政府也对该领域给予了高度重视,并将合成生物技术列为引领我国产业变革的颠覆性技术,与之息息相关的代谢途径优化,成为了越来越多研究者关注的热点。
在 AI 与大数据时代背景下,机器学习技术的自动化学习、灵活性和强大的数据处理能力等,为代谢途径的优化提供了新的思考方向,也为合成生物学带来了新的生机。
事实上,国内早有先驱者投身这一新兴行业,本文的作者罗小舟就在 2019 年创立了一家专注研发合成生物技术的企业——森瑞斯生物科技(深圳)有限公司。该公司把大数据和 AI 技术用于生物合成,背靠院校的科研资源,快速研发和落地了一些高附加值的产品管线,成功攻克了多项合成生物生产工艺的难题,完成了细分品类的底盘细胞构建。
此外,今年 1 月份,罗小舟博士团队还曾提出了一种酶动力学参数预测框架 EF-UniKP,该框架基于预训练大语言模型和机器学习模型,实现了酶动力学参数的准确预测和特定酶的高效挖掘。据了解,目前研究团队正在与森瑞斯生物科技(深圳)有限公司展开进一步的合作,有望推动该技术的落地和转化。(点击查看详细内容:中科院罗小舟团队提出 UniKP 框架,大模型 + 机器学习高精度预测酶动力学参数)
可以说,罗小舟博士完美践行了「产研融合」,在深耕合成生物学研究的同时,也在推动优秀成果落地产业。面对全球合成生物学产业的蓬勃发展现状,罗小舟表示,尽管我国在合成生物产业取得了初步成就,但仍处于起始阶段。因此,进一步加强核心技术的研发,确保科研成果与产业实践的深度结合,是缩小我国与发达国家合成生物产业差距的关键所在。
参考资料:
1.http://cn.chinagate.cn/news/2018-11/16/content_72414672_2.htm
2.https://new.qq.com/rain/a/20230918A03TY700
3.https://sheitc.sh.gov.cn/dsxxjyzl/20231129/7321884958b14651abeac020f7802f8b.html
4.https://www.develpress.com/?p=4755
5.http://www.isynbio.org/news-detail.aspx?detail=8217&parm=1772
6.https://www.cn-healthcare.com/article/20221028/content-574249.html
7.https://isynbio.siat.ac.cn/view.php?id=814
来源: HyperAI超神经
