
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中国自动化学会
中国自动化学会 导读:2023年10月20-21日,以“智能涌现 生成未来”为主题的第二十五届中国科协年会通用人工智能产业创新发展论坛在安徽省合肥市成功召开。中国科学院自动化研究所紫东太初大模型研究中心常务副主任、武汉人工智能研究院院长王金桥受邀出席并作题为“视觉大模型的实践与思考”的主题报告。报告指出,随着自监督学习的预训练模型爆发式发展,以ChatGPT为代表的语言预训练大模型取得了显著进步,但视觉的多任务统一模型仍存在许多问题亟待解决。报告基于多任务统一学习的视觉自监督预训练大模型学习机制和训练方法,探索了自回归和重建损失的联合优化方法;提出面向通用物体分割的FastSAM的加速方法。
以下为报告全文。
ChatGPT推出以来,大语言模型技术的发展取得突破性发展。然而,人工智能应用的广泛落地一直面临着视觉通用性的关键挑战。过去十年,人工智能广泛应用的通用性难题长期存在。以前,我们侧重于处理大数据、构建小模型、解决小任务,但这些模型的能力有限,主要的缺点在于依赖于大量标注数据、泛化能力差,难以适应不同场景。尽管目前技术上已经取得了一些突破,但人工智能落地应用仍然未能实现商业闭环。视觉与语言不同,实现通用的视觉能力尤为具有挑战性,涉及到二维、三维、时间等多个维度的处理,需要解决复杂的设计、计算力、语言与视觉之间的对齐等问题。
一、视觉领域面临的挑战
人类的感知过程中,大约70%的信息是来自视觉。与语言不同,视觉信息是非结构化的,所以训练视觉模型面临着更大挑战。如何实现视觉信息与语言单词的对齐、如何激发多模态的涌现能力,都是亟待解决的复杂问题,如图1所示。视觉信息涵盖多个维度,包括对象的外观、形状、颜色、质地,以及与对象相关的场景和光照信息。此外,不同应用场景,如人脸识别、车辆识别等,需要构建不同的小模型,导致应用的碎片化。视觉问题还涉及长尾问题,与语言相比,视觉模型的部署成本相对较高。
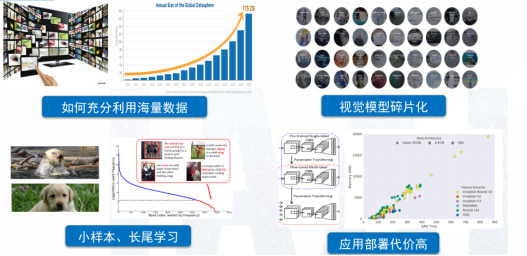
图1 视觉领域计算方法面临的挑战
二、视觉大模型研究现状
在视觉领域,自监督学习的应用一直备受关注,尤其是通过预测下一个单词实现海量学习。国内外学者进行了广泛的研究,包括比对学习、自回归预测和掩码预测等方法,如图2所示。然而,视觉自监督学习仍面临多个挑战。由于视觉信息的多维性,需要考虑全局信息,同时也需要强调局部信息。不同的视觉任务涉及不同类型的信息,如检测、分割、分类和回归等,这增加了通用模型设计的复杂性。通用性和专用性之间存在一定矛盾,既要关注特定任务的识别,又要涵盖全面的视觉知识来训练视觉模型。多任务学习和通用模型设计是当前研究的重点,尽管现有模型的能力仍然有限,特别是在处理未知类别和自动标记方面存在挑战。因此,解决这些问题需要更多的研究和技术创新,以实现更通用和高性能的视觉学习。
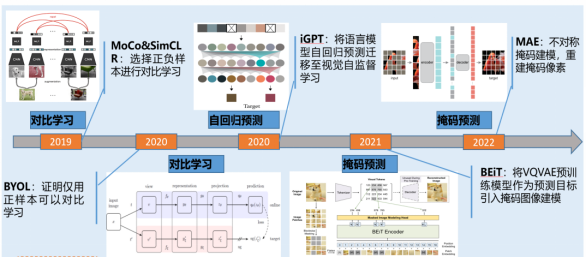
图2 视觉自监督学习
2021年,随着一系列视觉推理模型的涌现,如ViLD、M-DETR等,视觉自监督学习迎来迅速发展。与语言领域的大模型相比,视觉大模型在模型规模、训练数据、多任务学习和智能涌现方面仍有较大差距。因此,国内外的研究机构和公司,如META、Google、华为、商汤等都在持续改进图文融合模型。在图文对话中,仅使用图像对话往往信息量不够,而图文交错结合的回答能提供更精准的信息和更丰富的体验。此外,将文本模态与视频和声音相结合也会提供不同的感知和理解。因此,通用的纯视觉模型仍需进一步的发展和完善。
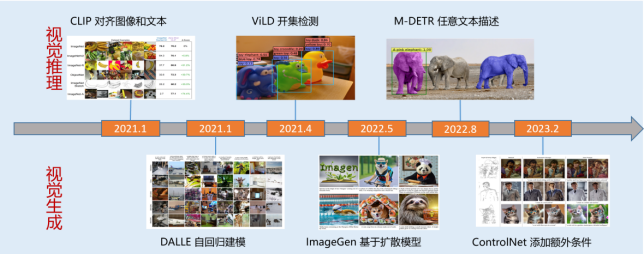
图3 视觉推理与生成
三、视觉大模型的探索和实践
中国科学院自动化研究所紫东太初大模型研究中心在视觉基础模型领域进行了大量探索,自2020年起,成立了国内第一个大型模型研究中心。紫东太初大模型致力于构建全站自主可控的大型模型,以确保数据安全和隐私;其次,在视觉模型领域,持续探索视觉自监督学习的新路径。引入可变形Transformer局部块结构,它具有自适应预测每个局部块的空间位置和大小的能力,如图4所示。这意味着模型可以根据目标场景的结构和语义信息,灵活地预测每个模块的大小,从而解决传统固定大小滑块在处理语义结构时的不完整性问题。这种可变形结构不仅有助于减少参数量,还能提高模型效率。
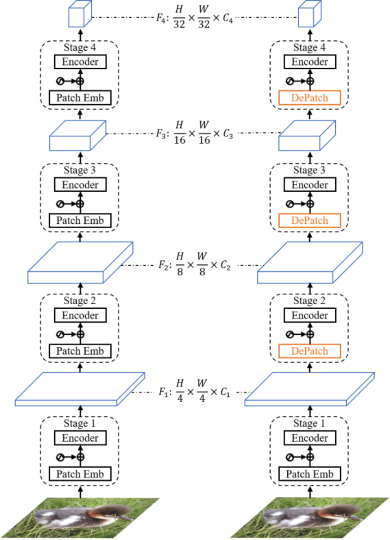
图4 可形变视觉Transformer模型
此外,紫东太初大模型在视觉自监督学习领域作出新的尝试,如将掩码的重建与比对学习相结合。在研究时不仅关注掩码的重建特性,还注重相似度和比对损失,通过构建动态的视觉掩码机制,显著提高了模型的收敛速度。这一模型相较于传统的比对学习,其收敛速度通常能提高2-8倍,而且在大约100轮训练后,即可达到主流效果的精度水平。
在图像重构过程中,不仅考虑单一目标或场景,还要深入挖掘目标与场景、目标与区域之间的有效关系。这使得多层次和多粒度的自监督学习能够实现,不再局限于单一目标的学习方式。该方法能在样本数量仅占总样本数1%-10%的情况下,超越传统的自监督方法,同时不受特定场景的限制,增强模型通用性和语义特性。
在视觉自监督学习领域,紫东太初大模型提出了一些方法来应对随机采样可能导致的不均匀性问题。无论是掩码重建还是自回归方法,随机采样常常难以确保全面采样和均匀分布。为了解决这一难题,紫东太初大模型引入了并行的掩码机制,以确保采样的数据相对均衡。另外,通过对损失函数进行优化,建立一致的预测损失,根据不同掩码特性提高预测准确性,如图5所示。这一优化将整个训练的效率提高了6.65倍,并在性能方面也取得了显著提升。通过以上创新方法,紫东太初大模型实现了视觉编码与自监督训练的对齐,并通过弱监督数据自适应地实现语言和数据的对齐,为多模态学习带来了新的可能性。
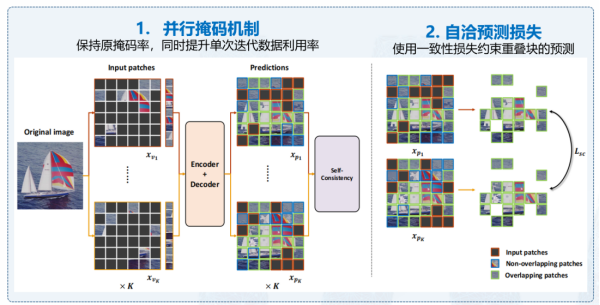
图5 高效掩码自洽模型
紫东太初大模型已成功建立了多模态环境下的多任务统一对齐机制,通过构建多任务自回归预测结构,实现模型的一致性。该视觉多任务统一模型,通过图像和语言编码,能够以多边形形式统一表示各种任务,包括检测、分割和关键点等。基于视觉知识的统一大型模型不再需要在不同场景下使用不同模型,而是能够根据需要,输出所需任务的结果。此外,紫东太初大模型还引入了基于视觉多任务的微调机制,使模型能够根据指令输出所需结果,无需构建多个不同的模型,还可以通过反馈学习来进一步完善意图对齐和结果输出。
四、视觉大模型应用
首先,紫东太初大模型可以自动识别海报中的内容,其次,可以进行知识进行推理。第三,可以进行工业场景自动定位目标应用。最后,模型还具备判断能力,能够识别图像中的对象,例如可以判断出“这不是一棵树,而是一个穿着外套的男人”。
大模型还可以深入理解这些图像中的情境和动作。在图7中,人们在进行拍照活动,其中一名女性持手机在拍照,另一张图中描述了一个人在挑选衣服,这些场景是与新零售相关的应用,大型模型能够根据每个场景的需求提供长尾问题的解决能力。上述示例展示了大模型视觉模型具备的多种语义推理能力。
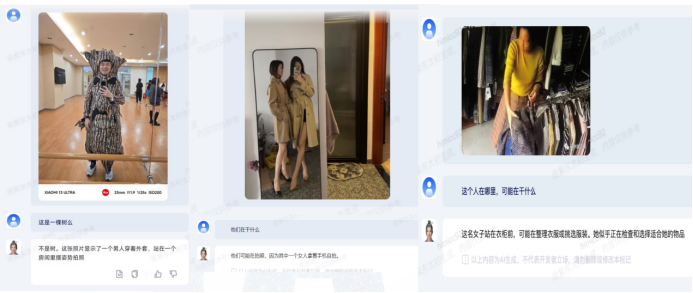
图7 图文理解/推理能力
除了通用模型,我们还研发了专门针对特定应用的模型,其中一个显著的例子是FastSAM,如图8所示,它是一个通用目标分割模型,性能比SAM高出50倍,在Hugging Face上177 like,Github已达5.8k stars。另一个重要应用是工业异常检测,我们开发了通用工业检测模型,适应于工业领域碎片化数据和有限样本情况,能够有效检测任何文本描述的正常和异常情况,为工业环境带来广泛的应用前景。
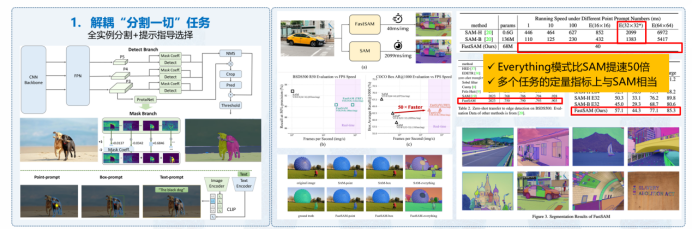
图8 通用物体快速分割大模型:FastSAM
这些应用覆盖了图像级别的少样本数据集,尤其在工业数据集方面,模型性能显著提升。在碎片化场景中,例如高铁的缺陷检测,视觉大模型的初始化可以使基础能力提高10%,再加入一些样本后,精度可以提升30%。在开放式场景中,例如道路缺陷检测,面对可能的各种障碍物,使用视觉大模型可提高巡检精度10%,显著降低30%的误报率。
在医疗器械管理方面,原本需要人工操作的工作,现在通过大型模型,手术器械的准备时间可以从一个小时缩短至半个小时,培训护工的时间也大大减少,工作效率提高了30倍,精度高达到99%。使用一个模型可以实现智能化的管理,仅需2台服务器即可为10家医院的所有手术提供管理服务。
最后,交通违章违法检测也将受益于大模型的泛化能力。通过积累的违章数据,可以直接生成检测模型,其精度基本能够超过人工审核,目前已经在全国60多个省市区县部署。以上示例突显了视觉大模型在多个领域的广泛应用。
尽管视觉大模型在通用能力上具有明显优势,但由于结合了视觉和语言,推理成本相对较高。未来,还需构建更高效的模型以及提升多场景能力以优化推理过程。此外,基于目前OCR和分割方面呈现出的强大潜力,未来还需继续专注于通过指令实现更精确的理解和生成。我们已经推出多模态照片说话平台,目前已对外开放,每个用户都可以生成更加精准的个性化视频内容。
最后,由于数据涉及敏感信息和语义信息,视觉大模型格外强调视觉数据的安全性和可控性。语义信息和内涵必须与价值观和形态意识相一致,因此需更加关注数据的清洗和生成过程,以确保数据的安全性和可控性。
(本文根据作者论坛报告速记整理而成,经作者授权发布)
作者简介:

王金桥,中国科学院自动化研究所紫东太初大模型研究中心常务副主任,研究员,博导,武汉人工智能研究院院长,中国科学院大学人工智能学院岗位教授,多模态人工智能产业联盟秘书长,主要从事多模态大模型、视频分析与检索、大规模目标识别等方面的研究。共发表包括IEEE国际权威期刊和顶级会议论文300余篇,国际期刊50余篇,国际会议220余篇。完成国家标准提案3项,发明专利36项,10项国际视觉算法竞赛冠军,新时代中国经济创新人物,北京市科技进步一等奖,世界人工智能大会SAIL奖,吴文俊人工智能科技进步二等奖,中国发明创新银奖。
来源: 中国自动化学会
内容资源由项目单位提供
