
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中启行
中启行 千亿参数的广告模型,是怎样炼成的?
在今天,计算广告产品技术的资料都不难查到,甚至很多工具都是开源的,那么大厂的技术优势,究竟还有多大呢?
容我打个比方:你是个格斗爱好者,今天就算你得到一本《如来神掌》,练成绝世武功,给你扔到俄乌战场上,那也只是炮灰的命。广告市场也是如此:大厂的技术武器,与一般团队已经有代际差距。这是因为他们服务于大量客户的市场动力,以及流量和数据规模上的优势,进化出了技术体系上的巨大进步。
因此,要服务好大量客户的增长需求,毋庸置疑需要一个强大的广告系统,拼技术实力的时候到了!而广告技术上的难度,不在原理,在于规模与精细程度。
数字广告的业务规模,与传统广告不可同日:动辄几十上百万的客户,数亿的用户,再加上各种APP环境。相应的广告调度问题,是在(用户,环境, 广告)三元组上做决策,学过初中数学的可以算算,这是多大的一个建模空间!应该说,计算广告大概是人类历史上最大规模的自动调度问题之一。
从精细程度上来看,很多人也有误解:啥建模?不就是算个广告点击率么!只要有数据,我也会算除法,用得着啥高深技术!这里的误解在于,以高效服务客户为目的,广告建模算的还真不是“广告的点击率”,而是“(用户,环境, 广告)三元组的点击率”。您想想看,如果不能区分出不同用户对同一个广告的点击率差异,那么还怎么为客户找到自己的精准人群呢?瞧瞧这个三元组,您的那点祖传除法功底还能用上么?
那么,对一个业界领先的广告系统来说,需要解决什么技术问题呢?核心是两点:
一、模型规模:如今,大规模的深度学习模型已经成熟,而大模型对与客户的精细化增长需求至关重要。
二、基础架构:要想玩转大模型,要有稳定性、扩展性强的分布式机器学习平台作为支持。
广告模型为什么这么大
先说第一点,在现代AI实践中,对大规模、高精度的建模问题,都采取了“数据多多益善、模型不厌其大”的态度。当然,数据怎么个多法、模型怎么个大法,大家未必有直观感受,我们就以腾讯广告的大模型来说,其特征规模就有千亿之多!
为啥这么多呢?一则普通的广告素材,人类发达的大脑在瞥见它的一瞬间,就理解了个底儿掉。可是要交给机器决策,就得从中提取各种各样的特征。比如在腾讯的广告大模型中,会提取如下这些特征:广告卖的是培训班,还是花裙子;广告的主要卖点是什么,在第几秒出现;广告的主要风格是煽情感人,还是搞笑活泼;有没有品牌侵权或其他违法内容……
简单看看就知道,这些特征可不是在文本文件里找个单词那么简单,要有比较成熟的OCR、计算机视觉和自然语言理解这些多模态的AI能力才行。腾讯广告在这方面有很多的技术积累,具备了跨模态的AI理解能力。
广告素材提取这么多特征,用户身上的特征当然只多不少。更关键的是,因为要建模的是“(用户,环境,广告)上的点击率”,这三元组不同维度上任取一个特征,两两配对或三个一组,就会爆炸式地产生几乎无穷无尽的“组合特征”,筛掉那些很不常见的组合以后,在广告的大模型中,实际用到的特征仍然有千亿之多!
其实,模型越大越好这个概念,并不是工业界自古以来的共识。在实用GPU以前,业界普遍认为浅层模型更实用,而在浅层模型下,过多的数据和模型带来的增益很小。直到深度学习普及,大家才发现用海量的数据和特征构建大模型,实践效果突飞猛进。这就好比,原有的浅层模型像个盘子,太多水是装不进去的,而深度学习是个桶,新的学习平台好比水龙头,这样新的理念和基础设施,让大模型的实践越来越有效。

那么,大模型在广告中的实用效果如何呢?把千亿参数、大小数GB的模型用于广告的精排阶段后,明显得到了更好的分析和匹配效果,特别是对长尾部分的分析和匹配改善显著。定性地说,用户可以看到更符合自己兴趣的广告,广告主也可以期待更高的转化率。定量地说,在广告大模型的帮助下,腾讯广告整体的消耗水平累计提升了20%以上。
所以,把模型搞大,收益是非常可观的!其实,模型的进展也不难被客户所感知:因为广告大模型提高了预估的准确性,这使得冷启动更快,空耗情况减少;同时,因为更多领域特征的引入,它还可以支持更深层转化目标的优化。
大模型背后的“生产线”
再说说前文提到的另一个问题:这千亿参数、数百GB的模型,加载到服务器上做计算就够复杂的了,这玩意是怎么在更庞大的原始数据集上训练出来的呢?
其实,这背后需要一个强大的、体系化的机器学习平台。打个比方,广告大模型好比高制程芯片,可是比芯片本身更难搞的,是生产芯片用的光刻机。大规模深度学习模型,背后的光刻机就是机器学习平台。对于腾讯的广告大模型来说,它背后的光刻机,就是太极机器学习平台。
千亿参数的广告大模型,模型是有点大,很多流行的开源工具肯定是玩不转了。这么大规模的模型训练,有两个具体的困难:
一、数据和模型实在太大了,必须采用分布式的方案。更麻烦的是,随着数据量的增长和模型的演进,整个分布式的方案也必须能够水平扩展,而不能重头来过。
二、在单机局部的数据处理和梯度计算过程中,最好能够使用GPU而不是仅仅使用CPU,这样整个训练过程才能大大提速。
在太极机器学习平台中,担负广告大模型训练和推理这一重要任务的,是AngelPS平台。PS,指的是参数服务器 (Parameter Server),这是针对上面的问题一,业界提出的一种将数据处理节点(Worker)和模型更新节点(Server)分离,并且都能够水平扩展的架构。然而,在千亿参数的广告大模型训练任务中,原理距离实用的产品还很远,这是因为广告特征虽然维度很高,但是在嵌入到模型前非常稀疏,必须有更高效的处理方案,于是,AngelPS应运而生。
另外,针对上面的第二个要求,AngelPS实现了在Worker节点上直接嵌入成熟的深度学习工具,比如PyTorch,以利用GPU大大提速。整体上来看,PS架构提供了大模型的规模扩展性,单节点上的GPU能力提供了充沛的算力,才使得广告大模型的生产和使用成为现实。关于AngelPS的系统架构,大家可以简要参考下图。
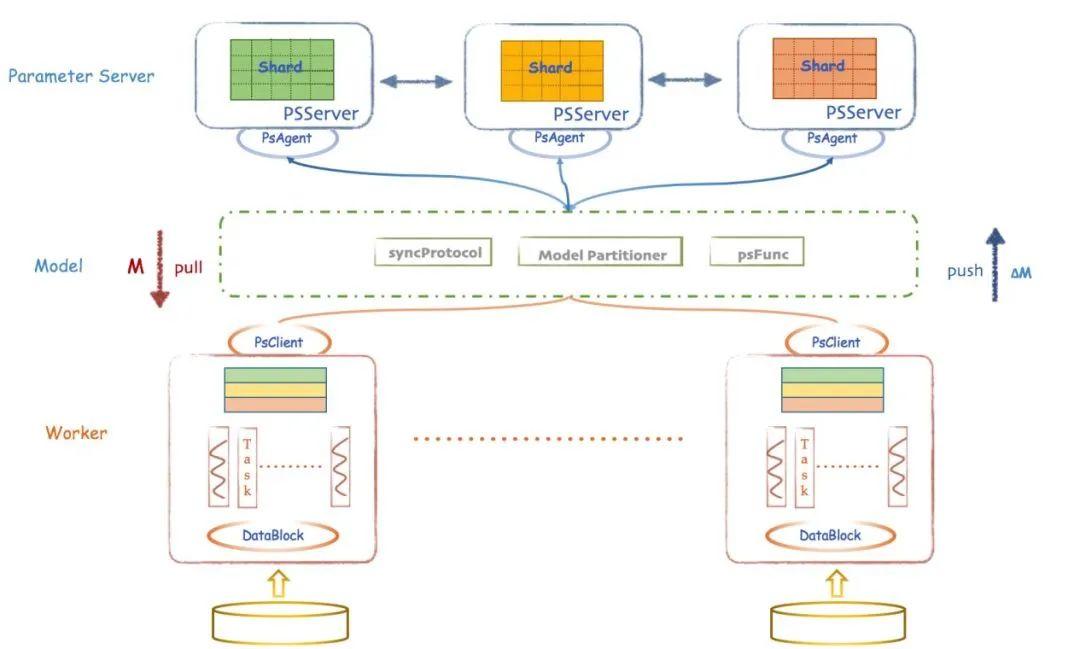
另外,AngelPS还分为训练和推理两个版本,前者负责在海量数据上构建模型,后者负责以高度实时性计算某次广告展示中的精排结果。
现代数字商业的规模和精细化程度,必然要求由人类经验决策转向机器智能决策,这带动了背后AI技术和基础设施的蓬勃发展。从腾讯广告系统的实践来看,以广告大模型为核心的技术演进正在以超乎我们想象的速度发生;另外,大模型的建设,又促进了机器学习平台的快读进步,两者形成了螺旋上升的良性循环。
不过,我更想说的是,以上这些的业界进展,并非只是花拳绣腿的炫技,而是正实实在在地为广大客户带来更加高效的增长,大大加快在数字世界的业务进程。因此,如果您希望升级自己在互联网的增长武器,一定要对这些技术上的进展保持关注,理解平台能帮你解决哪些问题。
作者:刘鹏,清华大学博士,大数据与互联网商业变现专家,奇虎360高级总监。
来源: 中国科技新闻学会
