
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中启行
中启行 极简介绍大模型Transformer架构选型
To be [decoder], or not to be [decoder], that is the question. -- William Shakespeare
Google 2017年《Attention Is All You Need》论文中提出Transformer模型,基于Encoder-Decoder架构。

并在之后论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中提出 BERT 模型,特点如下:
利用 Transformer 的 Encoder 架构;
预训练和 Fine-tuning;
预训练任务先在句中随机掩码几个词,后利用上下文预测这些词,进而预测下一句;
双向,上文+下文;
BERT 一度空前流行,国内很多公司的大模型都是基于Bert进一步训练的。OpenAI 则默默坚守GPT方向,直到ChatGPT 横空出世。GPT 模型特点如下:
利用 Transformer 的 Decoder 架构;
预训练+Prompts(提示);
预训练任务先在句中掩码最后一词,后利用上文预测这个词,把预测的这个词用作上文,预测再下一个词(自回归);
单向,从左到右,仅上文;
两者演化为如下的谱系:

两者对应的预训练的优化目标函数分别如下,我们先看GPT
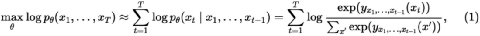
自回归(AR: Auto Regression)在学什么?“上文”中每个词与它们的组合的联合概率最大。
AR 是在反复学习遣词造句,语料是别人造好的句子,捂住最后面的,只看前面的,试着续写出来整个句子。训练的是事前诸葛亮的能力,符合人类正常的思维方式。某种意义上,AR其实是对人类思维流机理的学习。
很多情况下,AR学到了不仅仅有概率,还有因果,仔细体会:石头打人很 [ ],预测得到“疼”。
回过头再看 Bert,
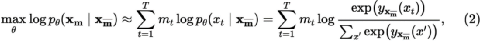
自编码(AE:Auto Encoding)在学什么?“上文”加上“下文”中每个词与它们的组合的联合概率最大。
AE 是在反复学习完形填空,语料是整篇文章,随机捂住中间的单词,通过上下文猜出这些单词。训练的是事后诸葛亮的能力,不符合人类正常思维方式。大家写作文,常打个腹稿,下笔还是思维流的方式补全调整细节措辞,很少整篇文字一次性喷涌而出。
很多情况下,AE学到了完形填空的精髓,为了考试而考试的机巧,石头 [ ] 人很疼,或许能预测出“打”字,但会更吃力,而且缺少泛化能力。
“事实证明,完型填空通常是同学们较难把握的题型之一,且失分率较高。”这是谷歌搜索完形填空第一条搜索结果。“托福雅思都没有,表示这个已经不适合语言学发展”,模型在针对这样的题目训练,其实除了自虐,学不到多少机理。

籍此,笔者有一个可能让不少人恼火的判断,所有基于Bert的模型都因为使用了Encoder而很难涌现,反倒是仅用 Decoder的GPT 类的容易涌现。Google Bert and Bard 都是成本高昂的试错,其技术成果与发现,为GPT做了嫁衣裳。
AR 在学写作的机理,机理学习多了,容易涌现;而AE 将模型注意力放到了写作的机巧,机巧学习多了,反而造成混乱。
来源: 中国科技新闻学会
