
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 科普中国创作培育计划
科普中国创作培育计划 
2018年,计算机领域最重要的奖项图灵奖被颁发给了3位计算机科学家,表彰他们在深度学习领域的开创性工作。
我们今天的生活已经离不开深度学习技术,从手机上的语音助手到聊天机器人,从自动驾驶到自动导航,从搜索引擎到机器翻译,再到最近的大规模预训练模型GPT-4和chatGPT,这些人工智能的应用领域都离不开深度学习。因为深度学习是机器学习的一种重要的技术,而机器学习又是人工智能的重要领域。

图片来源:pixabay
一、深度学习的起源
深度学习最早的灵感来自人脑。不过,深度学习搭建的模型和人脑还是有本质的区别,就像早期的飞机也是从鸟类身上获得灵感,但飞机飞行的原理和鸟类飞行的原理却很不相同。
相关的研究最早可以追朔到1949年,加拿大神经心理学家唐纳德·赫布(Donald Hebb)提出,如果两个神经元同时被激活,它们的突触连接就会被增强,反之有可能减弱。他认为这种神经元之间连接强度的变化是人类学习的生理基础。
1958年,弗兰克·罗森布拉特(Frank Rosenblatt)根据神经元的连接方式,设计了一个最简单的神经网络,将其命名为感知机。
感知机里的节点类似神经元,而神经元之间也有权重,类似突触。感知机只有一层神经元。
【感知机结构】:
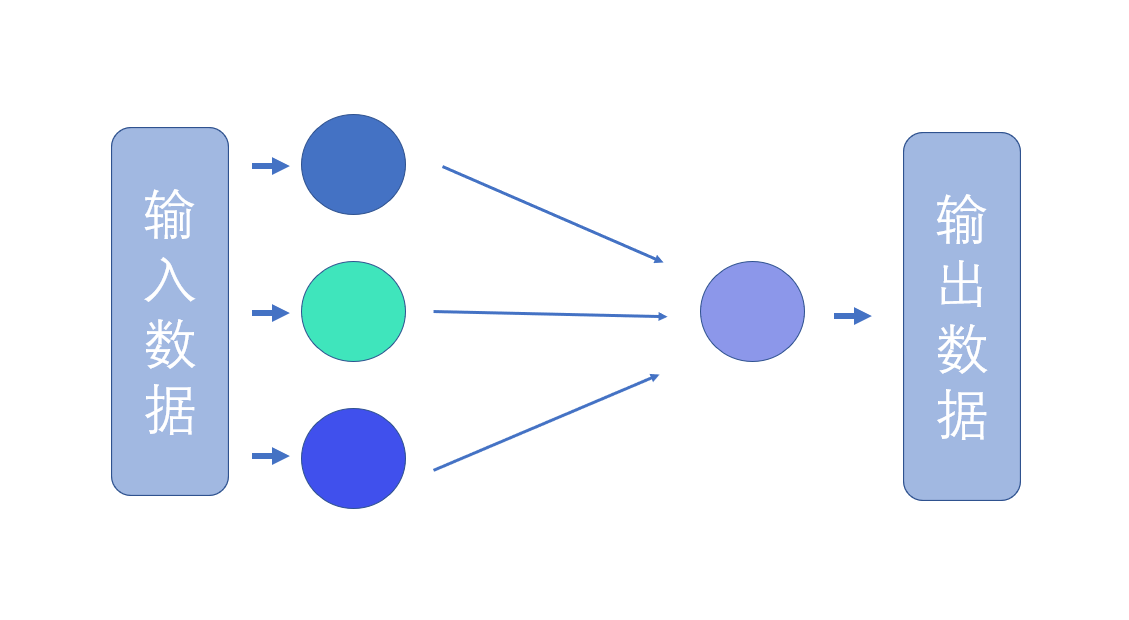
笔者供图
虽然在今天,感知机模型可以用几行代码就能写出来,但在上世纪50年代,罗森布拉特只能在提及占了一屋子的IBM 704大型计算机上进行测试。随后,他在康奈尔大学自己专门建了一个实体感知机,并命名为Mark 1。
感知机可以用来完成图片分类的任务。它有很多光传感器,可以用来“看”图片。传感器的接受的数据可以被很多电线连到计算单元里。这些计算单元可以扮演神经元的角色。神经元之间连接的强度则可以通过电位器编码。例如,研究人员把一些人脸的照片输入机器,并且告诉感知机这些照片对应的性别。感知机可以调整神经元之间的连接强度。经过这样的训练后,感知机就能判断图片中人物的性别,让正确的文字亮起来。
多层神经网络的问世
不过,感知机的结构还是过于简单了,很快人们认识到,这种只有一层神经元的简单神经网络只能解决比较简单的问题,但却无法解决过于复杂的问题。
而多层神经网络则面临理论和计算机能力的瓶颈,无法得到应用。到了20世纪60年代末期,神经网络的研究已经基本上停滞了。
到了1985年,可以训练多层神经网络的反向传播算法出现。同时,更强大的也可以支持快速的小数乘法,从而让多层神经网络的出现成为了可能。
1988到1989年,法国计算机科学家杨立昆(Yann Le Cun)在贝尔实验室设计了一个深度神经网络LeNet。这个神经网络包含三层神经元,可以识别各种手写数字。
LeNet经过纪念的迭代后,变成了一个有7层神经元的深度学习模型。这个深度学习模型还采用了一些被称为卷积的方法,可以更全面准确地捕捉图片中的信息。到了90年代中期,贝尔实验室商业化了一批神经网络系统,用于自动识别邮政编码和银行支票。据估计,到20世纪90年代末,全美国大概10%到20%的支票是由深度学习模型识别的。这可能是深度学习最早期的商业应用之一。
然而,还是有很多因素限制了深度学习的广泛应用。例如,当时的计算机速度仍然很慢。杨立昆需要用好几天时间才能训练一个简单的手写数字识别模型。此外,如果想要完成更复杂的任务,需要更多的数据和更复杂的网络结构。这些问题直到21世纪才得到解决。在那之后,深度学习才开始席卷全球,成为人工智能领域最重要的技术,甚至还产生了深刻的社会变革。
文章由科普中国-星空计划(创作培育)出品,转载请注明来源。
作者:管心宇 科普作者
审核:于旸 腾讯玄武实验室负责人
来源: 星空计划
内容资源由项目单位提供
