
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中国科普博览
中国科普博览 
出品:科普中国
作者:李晓庆研究组(中国科学院心理研究所行为科学重点实验室)
监制:中国科普博览
在日常语言交流中,人们经常会预测对方即将说出的内容,比如朋友跟你说“我早餐吃了豆浆和……”,可能还没说完,你就已经根据“豆浆”等信息,预测他即将说出的是“油条”。
如果他说的真的是“油条”,相比于他说出“馒头”,你的理解会更快、更容易。
这种预测加工普遍存在于语言理解过程中,是人脑能够实现高效语言理解的重要原因之一。然而,以往的科学研究主要聚焦于被预测的目标信息(例子中的“油条”)出现之后,人们是怎么加工目标信息的。但是,一个更加值得探讨也非常具有挑战性的研究问题是:这种预测是怎么产生的?
工作记忆:临时的记忆工作站
诺贝尔经济学奖得主,心理学家丹尼尔·卡尼曼在《思考,快与慢》一书中,系统阐述了思维过程涉及的两个系统:系统1是“快系统”,是自动化的、无意识的;系统2是“慢系统”,需要付出认知努力,讲逻辑、有意识的。
他认为听到豆浆而想到油条,这种概念之间的联想加工依赖于系统1。那么,语言理解中的预测过程只依赖于系统1就能够完成吗?想要回答这一问题,我们先了解一下“工作记忆”。
工作记忆是指一种对信息进行临时存储和处理的记忆系统,因为是一个临时的“工作站”,所以能够存储及加工的信息容量是有限的。
工作记忆容量受到很多因素的影响,比如年龄。它在儿童以及青少年时期随龄增大,而在老年时期逐渐缩小。
1956年,米勒提出工作记忆容量为7±2个“组块”,即工作记忆中一般存储5—9个组块信息。对于不同的人,每一个“组块”所包含的内容不同,就导致了工作记忆中能够存储和加工的信息量具有很大的个体差异。

工作记忆容量(图片来源:作者)
例如,人们很难记住一串18位的数字,但如果这个数字是身份证号时,将其划分为省、市、区(县)编码,以及出生日期等几个“组块”之后,就会更容易被记住。
语言理解中的预测过程是怎样的?
我们再回到语言理解中的预测过程,鉴于工作记忆容量有限的特点,如果只依赖于自动化的系统1,那么预测过程将不受工作记忆容量的影响。如果系统2也参与了预测加工,那么不同工作记忆容量的个体在预测加工中的表现也会有所差异。
为了验证不同的猜想,中国科学院心理研究所李晓庆研究组近期开展了一项脑电研究。

脑电实验过程示例(图片来源:Pixabay)
研究者招募了160名大学生,通过工作记忆容量测试,从中筛选出了两组,一组包含24名高工作记忆容量个体,另一组包含24名低工作记忆容量个体。
两组大学生阅读并理解电脑屏幕上呈现的一系列句子。句子共有三种类型:高限制性、中等限制性、低限制性。
这里的限制性指的是根据句子语境中的信息,人们在多大概率上能够预测某一个相同的词。
例如,如果10个人当中有9个人能够在语境“为了把钉子钉到木板里,他买了……”中预测后面出现的是“锤子”,那我们就说这个语境的限制性是90%。
相应地,被预测的名词“锤子”具有90%的预测概率。同理,“锤子”在中等限制性语境“为了能敲开坚硬的核桃,他买了……”中具有中等预测概率;“书籍”在低限制性语境“为了能完成好这个任务,他买了……”中具有低预测概率。
脑电波概念图(图片来源:veer图库)
研究记录了个体在阅读句子时的脑电信号,并主要分析了脑电波的波幅。简单来讲,通常脑电波幅越大,认知加工越困难。
通过研究,科研人员有以下几个发现:
第一个发现:在目标名词出现之前的动词处(如例子中的“买了”),与低限制性语境中的“买了”相比,大学生们在阅读到高限制性语境中的“买了”时,脑电波幅更大,这一现象只在高工作记忆容量组中被观测到。
科研人员进一步通过数学模型分析发现,高限制性语境中动词处的脑电波幅与后续目标名词的预测概率正相关,即名词的预测概率越大,动词所引起的脑电波幅也越大。
比如“蛋糕”在高限制性语境“为了庆祝妈妈的生日,她买了……”中的预测概率为100%,那么这个语境中的“买了”所诱发的脑电波就比前文高限制性例子中的“买了”更大,因为“锤子”的预测概率为90%。
这一结果表明,高工作记忆容量者此时正在努力地激活随后即将出现的名词,并将其存储在工作记忆中。
第二个发现:在目标名词,如例子中的“锤子”和“书籍”出现之后,高工作记忆容量组中名词诱发的脑电波幅随着名词预测概率的增大而逐渐减小,即高限制性语境中的“锤子”<中等限制性语境中的“锤子”<低限制性语境中的“书籍”,而低工作记忆容量组只表现出了“高限制性<低限制性”的脑电效应。
这表明高预测性名词由于与工作记忆中存储的名词相同,因此具有更好的语义理解效果、且高工作记忆容量个体具有一定的语言理解优势。
科研人员进一步通过数学模型分析发现,目标名词的预测概率差异越大,所诱发的脑电波幅差异也越大,表明目标名词在不同条件下所诱发的脑电波幅确实与它的预测概率有关。
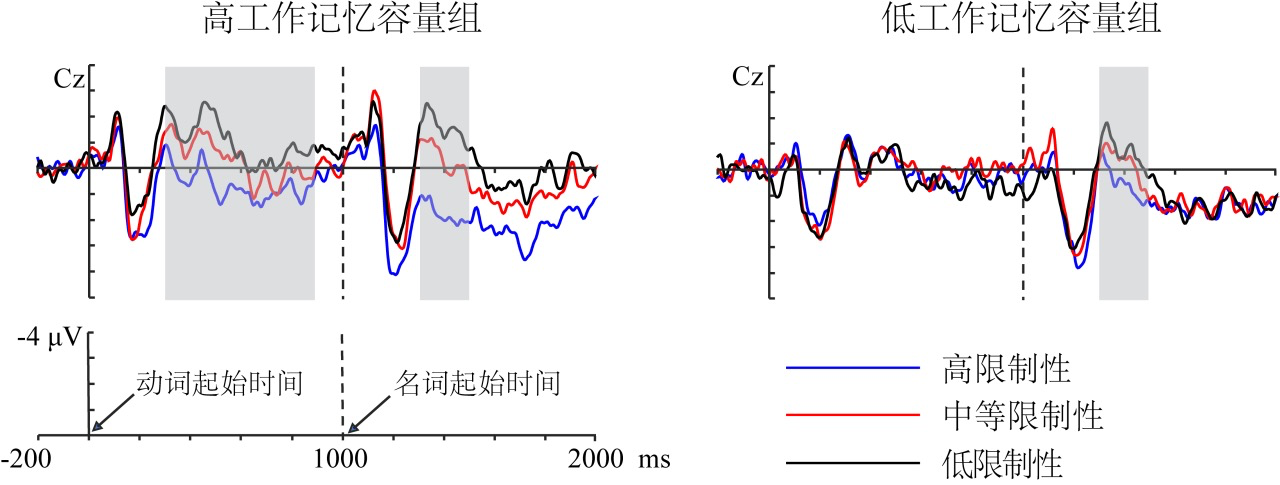
高工作记忆容量(左)和低工作记忆容量(右)个体在预测产生(动词位置)和预测整合(名词位置)阶段在Cz电极点的脑电波(图片来源:参考文献[1],有改编)
总结来讲,不同工作记忆容量的个体在预测性语言理解中所表现出的差异表明,语言理解中的预测加工确实可以促进人们的理解过程,但预测本身是一个需要消耗认知努力的意义计算建构过程,并不像丹尼尔·卡尼曼所举的例子那样,仅仅源于概念之间自动化的联想激活。
我们可以称之为语言理解中的“鸭子凫水”现象,水面上的鸭子看起来轻松自在,实际上鸭蹼在水下一刻不停,即看起来我们理解语言轻松快速,实际上大脑时刻不停地在进行预测加工。

鸭子凫水(图片来源:Pixabay)
如何提高大脑的信息容量与预测能力?
既然本研究发现了工作记忆容量与语义预测加工息息相关,那么是否可以通过提高工作记忆容量来促进语言理解呢?
未来研究可以进一步考察这一问题。但回答这一问题之前,需要明确工作记忆容量是否可以通过训练而得到提高?
已有科学研究给出了肯定答案。研究者将工作记忆分为领域特异性工作记忆和领域一般性工作记忆。
前者是指与特定信息类型有关的工作记忆,比如言语工作记忆、数字工作记忆等。后者则不限于特定的信息类型,可以称为一个控制系统,包括控制注意力、控制信息在工作记忆中的流入和流出、控制不相关信息的干扰等过程。

各种汉字语言(图片来源:veer图库)
针对特异性和一般性的工作记忆,会有不同的训练方式。
领域特异性工作记忆一般采用策略训练,比如可以通过反复练习,增加每一个“组块”中所包含的信息量,例如在“身份证”例子中,可以将多个数字“组块”放在一起,以提工作记忆中存储的数字容量。
领域一般性工作记忆则采用核心训练,这种训练通常会包括多种模态的任务或刺激,设置较强的干扰,或者需较高强度的认知参与等。比如可以通过注意力训练、认知训练等方法提高一般性工作记忆能力。

人工智能示意(图片来源Pixabay)
结语
现在我们已经大概了解了语言理解中预测性加工的认知机制,即语言理解并没有看上去的那么简单容易。
目前,市面上诸如ChatGPT等各种大语言模型都纷纷投入应用。这些模型虽然能够快速地进行人机互动,并在很大程度上可以模拟人类的语言理解过程,但其背后的算法还缺乏人类认知神经机理的支撑。
未来的研究如果能够进一步揭示语言理解中预测性加工的神经机制,相信一定会对通用人工智能的发展起到重要的促进作用。
参考文献:
[1]Ding, J., Zhang, Y., Liang, P., & Li, X. (2023). Modulation of working memory capacity on predictive processing during language comprehension. Language, Cognition and Neuroscience.
[2]Ding, J., Wang, L., & Yang, Y. (2020). The influence of emotional words on predictive processing during sentence comprehension. Language, Cognition and Neuroscience, 35(2): 151–162.
[3]Zheng, Y., Zhao, Z., Yang, X., & Li, X*. (2021). The impact of musical expertise on anticipatory semantic processing during online speech comprehension: An electroencephalography study. Brain and Language, 221, 105006.
[4]Zheng, Y., Gao, P., & Li, X*. (2023). The modulating effect of musical expertise on lexical-semantic prediction in speech-in-noise comprehension: Evidence from an EEG study. Psychophysiology.

来源: 中国科普博览
内容资源由项目单位提供
