
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 HyperAI超神经
HyperAI超神经 
人与人交往中,说话表达是最基本的能力和方式,可世界上有很多人,却「有口难言」。
「失语症」中,由中风引起的最为常见。他们的声音无法传达,他们的诉求不为人所知,他们遭受着社交孤立,他们的沉默震耳欲聋。
每一个因中风而失语之人,无不渴望恢复完全、自然的交流能力,尽管目前全世界范围内瘫痪无法根治,但如今在 AI 加持下,丧失说话能力的瘫痪患者也可以重新恢复声音,并以丰富的表情、动作与人实时交流。
作者 | 铁塔
编辑 | 三羊
本文首发于 HyperAI 超神经微信公众平台~
茨威格曾言,「一个人生命中最大的幸运,莫过于在他的人生中途,即他年富力强的时候发现了自己的使命。」
而人最大的不幸是什么呢?
在小编看来,一个人生命中最大的不幸,莫过于在风华正茂的年纪,突然丧失所有语言和行动能力——一夕之间,梦想、事业、愿望统统化为泡影,生活被整个掀翻。
Ann 就是其中不幸的代表。
三十而立,中风失语
2005 年某天,一向身体倍儿棒的 Ann 突然出现头晕、吐字不清、四肢瘫痪和肌无力等症状,经诊断,她患上了脑干梗死(即我们日常所说的「中风」),伴有左椎动脉夹层和基底动脉闭塞。
这场毫无预兆的中风给 Ann 带来了名为「闭锁综合征」的副产品——罹患此病者,所有感官意识俱在,但无法调动身体任何一块肌肉,患者既不能活动,也不能自主说话,有的甚至无法呼吸。
正如「闭锁」字面所体现的,带领常人走遍千山万水的身体,成了封印患者灵魂的牢笼。
彼时, Ann 才 30 岁,结婚 2 年零 2 个月,女儿刚出生 13 个月,在加拿大一所高中当数学老师。「一夜之间,我的一切都被夺走了。」 Ann 后来借助设备,在电脑上缓慢地敲下了这句话。

参与研究的 Ann
经过多年的物理治疗, Ann 才可以呼吸、稍微转动头部、眨眨眼、说几句话,但仅此而已。
要知道,正常生活中,一般人的讲话语速在 160-200 字/分钟之间,而 2007 年来自美国亚利桑那大学心理学系的研究结果显示:男性平均每天要说 15,669 个单词,女性平均要说 16,215 个单词(平均一个单词对应 1.5-2 个汉字)。
在语言是人际交流主要手段的世界里,可以想见,表达受限的 Ann 有多少需求被堙灭在无声之中?伴随失语而失去的,不仅仅是生活质量,乃至人格和身份。而全世界又有多少瘫痪失语者和 Ann 处于同样的境地?
瘫痪18年,重新开口
恢复完全、自然的交流能力,是每一个因瘫痪而失语之人的最大渴望。在科技高度发达的今天,有没有办法借助技术的力量,将人际交流的能力还给患者?
有!
近期,来自美国加州大学旧金山分校和加州大学伯克利分校的研究团队利用 AI 开发出一种新的脑机技术,让失语 18 年的 Ann 重新「开口说话」,并基于数字化身产生生动的面部表情,帮助患者以符合正常人社交的速度和质量与他人实时交谈。

Ann 借助数字化身与人交谈
这是人类历史上首次从大脑信号中合成语音和面部表情的创举!
加州大学团队此前的研究表明,从瘫痪者的大脑活动中解码语言是可能的,但只能以文本的形式输出,而且速度和词汇量有限。
此番他们想更进一步:既能实现更快的大词汇量文本交流,又能恢复与说话相关的语音和面部动作。
基于机器学习与脑机接口技术,研究团队实现了以下成果,发表于 2023 年 8 月 23 日的《Nature》上:
► 对于文本,将受试者的脑信号以每分钟 78 个单词的速度解码为文本,平均单词错误率为 25%,比受试者当前使用的通信设备(14 个单词/分钟)快了 4 倍多;
►对于语音音频,将脑信号快速合成为可理解和个性化的声音,与受试者受伤前的声音一致;
►对于面部数字化身,实现了语音和非语音交流手势的虚拟面部运动控制。

论文链接:
https://www.nature.com/articles/s41586-023-06443-4
你一定很好奇,这种划时代的奇迹怎么实现的?接下来,咱们具体拆解一下这篇论文,看研究人员如何妙手回春。
1.底层逻辑:脑信号→语音+面部表情
人类大脑通过外周神经和肌肉组织实现信息输出,而语言能力由大脑皮质中的「语言中枢」所控制。
中风患者之所以失语,原因在于血液循环受阻,大脑语言区域因缺少氧气和重要营养物质而受损,导致一个或多个语言沟通机制无法正常运作,从而出现语言功能障碍。
对此,加州大学旧金山分校和伯克利分校的研究团队设计了一个「多模态语音神经假体」,使用大范围、高密度的皮质脑电图 (ECoG) 来解码分布在整个感觉皮层 (SMC) 发音声道表征的文本和视听语音输出,即从源头上捕捉大脑信号,通过技术手段将其「翻译」成对应的文本、语音甚至面部表情。
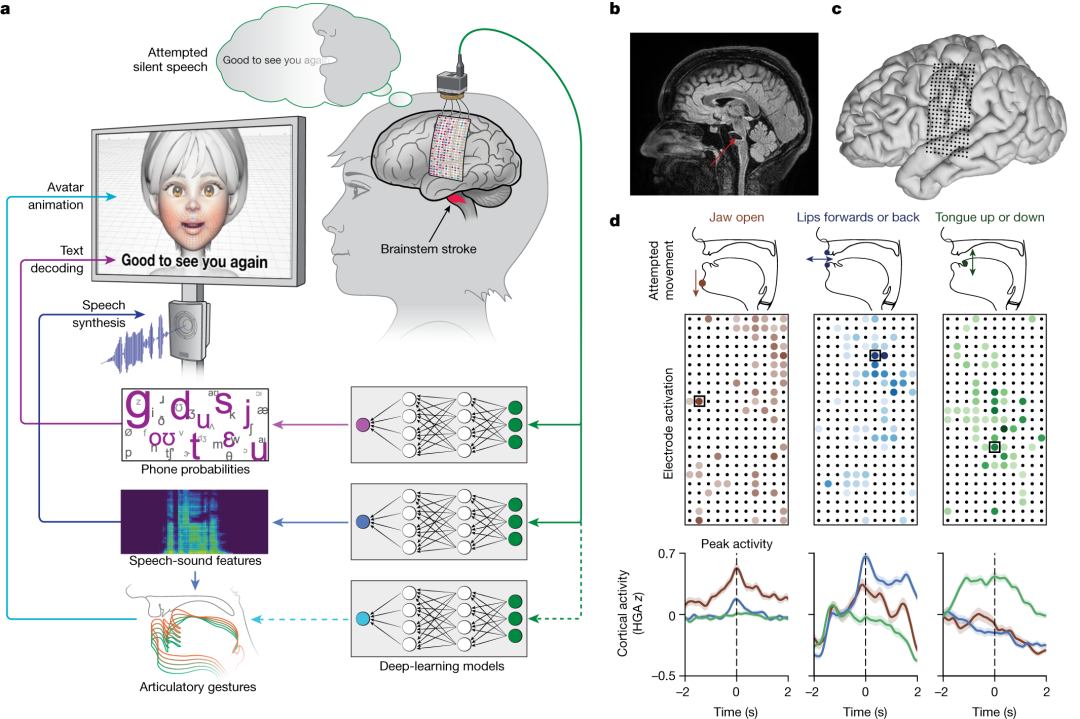
声道瘫痪患者的多模态语音解码
2.过程及实现:脑机接口 + AI 算法
首先是物理手段。
研究人员通过硬膜在 Ann 大脑左半球的脑顶表面植入了一个高密度脑电图阵列和经皮底座连接器,覆盖与语言产生和语言感知相关的区域。
该阵列由 253 个圆盘状电极组成,用于拦截原本传送到 Ann 舌头、下巴、喉咙及脸部肌肉的大脑信号。一根电缆插入固定在 Ann 头上的端口,将电极与一组计算机相连。
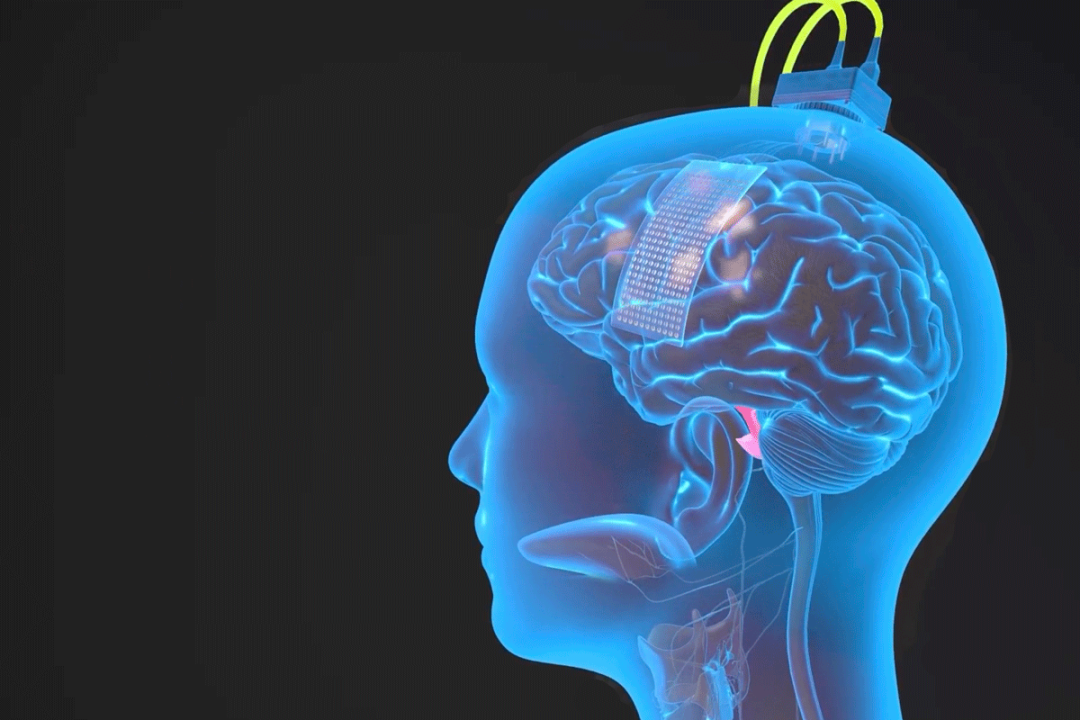
电极阵列植入受试者大脑皮层表面的语言控制区
其次是算法构建。
为识别 Ann 独特的大脑语音信号,研究团队与她一起花费了几周时间来训练和评估深度学习模型。
研究人员基于 nltk Twitter 语料库和 Cornell 电影语料库创建了 1,024 个单词的通用句子集,指示 Ann 以自然语速无声说话。她一遍又一遍地从1,024 个单词的会话词汇中默念不同的短语,直到计算机识别出与这些声音相关的大脑活动模式。
值得注意的是,这个模型并非训练 AI 识别整个单词,而是创建了一个系统从「音素」中解码单词,如「Hello」包含四个音素:「HH」、「AH」、「L」和「OW」。
基于这种方法,计算机只需学习 39 个音素就能解读任何英语单词,既增进了准确性,又将速度提升了 3 倍。
注:音素是语言的最小声音单位,可描述语音的发音特征,包括发音部位、发音方式和声带振动等,如 an 的音素由 /ə/ 和 /n/ 组成。
这个音素解码的过程,类似婴儿学说话的过程。根据目前发展语言学界较为公认的观点,刚出生的婴儿就能分辨全世界语言中的 800 个音素。学龄前儿童可以不懂词句的写法与意思,但却能通过对音素的感知、区分和模仿来逐渐学会发音和理解语言。
最后是语音和面部表情合成。
基础已经打完,接下来是语音和面部表情的显化呈现,研究人员通过语音合成和数字化身来解决这个问题。
语音方面,研究人员开发了一种合成语音算法,使用了 Ann 中风前的声音录音,尽可能使数字化身的声音听起来像她。
面部表情上, Ann 的数字化身由 Speech Graphics 公司开发的软件创建而成,呈现为屏幕上的女性脸部动画。
研究人员定制了机器学习过程,使软件与 Ann 试图说话时大脑发出的信号相协调,从而表现出下巴张开和闭合、嘴唇突出和收缩、舌头上下运动,以及表达快乐、悲伤和惊讶的面部运动及手势。

Ann 正与研究人员一起进行算法训练
未来展望
加州大学旧金山分校神经外科主任、医学博士 Edward Chang 表示,「 我们的目标是恢复一种完整的、具体的沟通方式,这是我们与他人交谈最自然的方式……将可听到的语言与真人化身结合起来的目标,能让人类语言交流得到充分体现,而这远远不止语言。」
研究团队的下一步是创建一个无线版本,摆脱脑机接口的物理连接,使瘫痪的人们能利用这项技术自如地控制个人手机和电脑,而这将对他们的独立性和社会交往产生深远影响。
从手机上的语音助手、电子刷脸支付到工厂里的机械臂、生产线上的分拣机器人,AI 正在延伸人类的四肢与五官,并逐渐渗透到我们生产生活的方方面面。
科研人员关注瘫痪失语者这一特殊群体,利用AI的力量帮助其恢复自然的交流能力,有望促进患者与亲友之间的联络,扩大他们重新获得人际互动的机会,并最终提高患者的生活质量。
我们为这一成就感到振奋,期待更多 AI 造福人类的捷报传来。
参考链接:
[1] https://www.sciencedaily.com/releases/2023/08/230823122530.htm
[2] http://mrw.so/6nWwSB
本文首发于 HyperAI 超神经微信公众平台~
来源: HyperAI超神经
