
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 HyperAI超神经
HyperAI超神经 
内容一览:人脸识别可以锁定人类身份,这一技术延申到鲸类,便有了「背鳍识别」。「背鳍识别」是利用图像识别技术,通过背鳍识别鲸类物种。传统的图像识别依赖于卷积神经网络 (CNN) 模型,需要大量训练图像,并且只能识别某些单物种。近期,夏威夷大学的研究人员训练了一种多物种图像识别模型,该模型在鲸类应用中表现出色。
关键词:图像识别 鲸类动物 ArcFace
作者|daserney_HyperAI 超神经
编辑|缓缓、三羊_HyperAI 超神经
本文首发于 HyperAI 超神经微信公众平台。
鲸类动物是海洋生态系统的旗舰动物和指示性生物,对于保护海洋生态环境具有极高的研究价值。传统的动物身份识别需要对动物进行现场拍摄,记录个体出现的时间和位置,包含许多步骤,过程繁杂。其中又以图像匹配——在不同图像中识别出同一个体尤为耗时。
2014 年 Tyne 等人展开的一项研究估计,在对斑海豚 (Stenella longirostris) 进行为期一年的捕捉和释放调查中,图像匹配耗费了超过 1100 个小时的人力劳动,几乎占据了整个项目总经费的三分之一。
近期,来自夏威夷大学 (University of Hawai‘i) 的 Philip T. Patton 等研究人员,利用 5 万多张照片(包括 24 种鲸类动物、39 个目录),训练了基于人脸识别 ArcFace Classification Head 的多物种图像识别模型。该模型在测试集上达到了 0.869 的平均精确率 (MAP)。其中,10 个目录的 MAP 得分超过 0.95。
目前该研究已发布在《Methods in Ecology and Evolution》期刊上,标题为「A deep learning approach to photo–identification demonstrates high performance on two dozen cetacean species」。

该研究成果已发表在《Methods in Ecology and Evolution》
论文地址:
https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14167
数据集:25 个物种、39 个目录
数据介绍
Happywhale 和 Kaggle 与全球研究人员协作,组建了一个大规模、多物种的鲸类数据集。该数据集是为 Kaggle 竞赛收集的,要求参赛团队从背鳍/侧身的图像中识别个体鲸目动物。数据集包含 25 个物种 (species) 的 41 个目录 (catalogues),每个目录包含一个物种,其中有些目录中的物种会重复出现。
该研究去掉了两个竞赛目录,因为其中一个只有 26 张用于训练和测试的低画质图像,而另一个目录则缺少测试集。最终的数据集包含 50,796 张训练图像和 27,944 张测试图像,其中,50,796 张训练图像包含 15,546 个身份 (identities)。在这些身份中,9,240 个 (59%) 只有一张训练图像,14,210 个 (91%) 有 5 张以内训练图像。
数据集及代码地址:
https://github.com/knshnb/kaggle-happywhale-1st-place
训练数据
为了解决图像背景复杂的问题,一些参赛者训练了图像裁剪模型,可以自动检测图像中的鲸类动物,并在其周围绘制边界框。下图中可以看出,这一流程包括 4 个鲸类检测器,使用了 YOLOv5 和 Detic 在内的不同算法,检测器的多样性增加了模型的鲁棒性,并且能对实验数据进行数据增强。

图 1:竞赛集中 9 个目录的图像以及 4 个鲸类检测器生成的边界框
每个边界框生成的裁剪的概率为:红色为 0.60,橄榄绿为 0.15,橙色为 0.15,蓝色为 0.05。裁剪后,研究人员将每个图像的大小调整为 1024 x 1024 像素,以与 EfficientNet-B7 backbone 兼容。
调整大小后,应用仿射变换、调整大小和裁剪、灰度、高斯模糊等数据增强技术,避免模型出现严重过拟合。
数据增强是指在训练过程中对原始数据进行变换或扩充,以增加训练样本的多样性和数量,从而提高模型的泛化能力和鲁棒性。
模型训练:物种 & 个体识别双管齐下
下图显示了模型的训练流程,如图中橙色部分所示,研究人员将图像识别模型分为 3 个部分:backbone、neck 和 head。
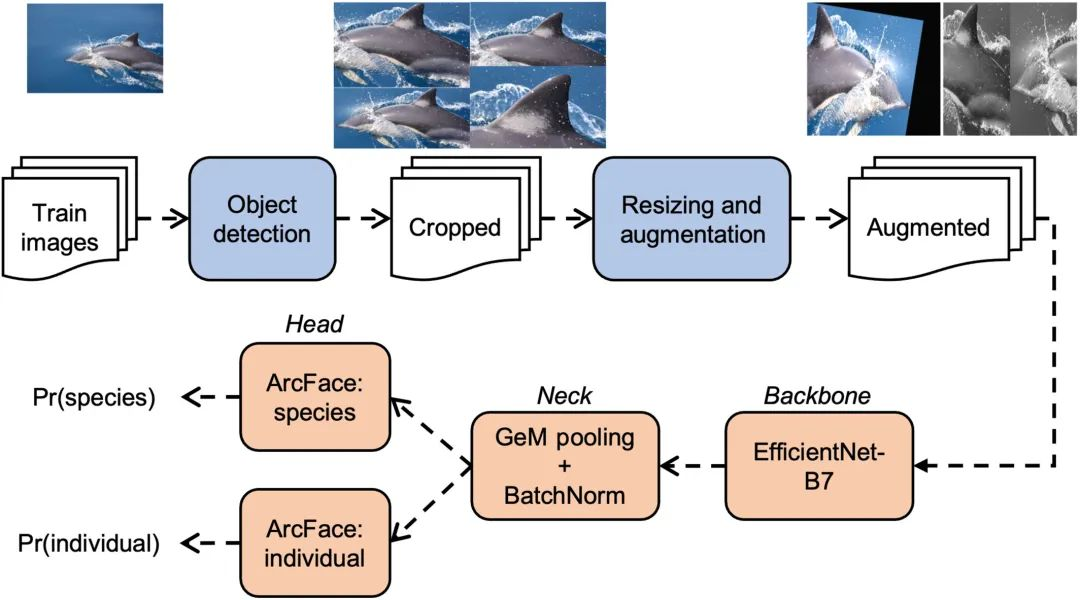
图 2:多物种图像识别模型训练 Pipeline
图中第一行是预处理步骤(以普通海豚 Delphinus delphis 图像为例),由 4 个目标检测模型生成 crops,数据增强步骤生成两个示例图像。
最下面一行则显示了图像分类网络的训练步骤,从backbone 到 neck 再到 head。
图像首先通过网络进入 backbone。过去十年的一系列研究已经产生了数 10 种流行的 backbone,包括 ResNet、DenseNet、Xception 和 MobileNet。经验证,EfficientNet-B7 在鲸类应用中表现最佳。
Backbone 获取图像后,通过一系列卷积层和池化层对其进行处理,从而生成图像的简化三维表示。Neck 将此输出减少为一维向量,又称为特征向量。
两个 head 模型,都将特征向量转换为类概率,即 Pr(species) 或 Pr(individual),分别用于物种识别和个体识别。这些 classification heads 被称为具有动态边距的次中心 ArcFace,普遍适用于多物种图像识别场景。
实验结果:平均精度 0.869
对测试集中的 21,192 张图像(24 个物种的 39 个目录)进行预测,获得了 0.869 的平均精度 (MAP)。如下图所示,平均精度因物种而异,且与训练图像或测试图像的数量无关。
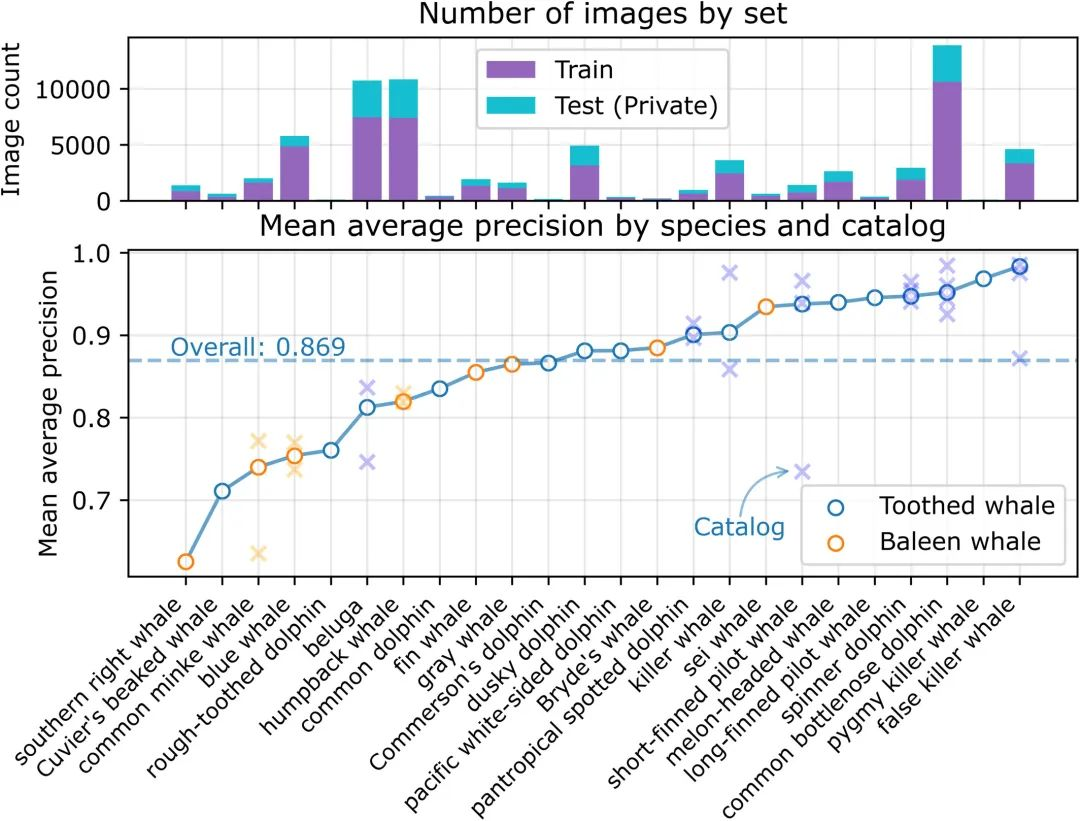
图 3:测试集的平均精度
顶部面板按用途(即训练或测试)显示每个物种的图像数量。具有多个目录的物种,则用 x 表示。
图中显示,该模型在识别齿鲸 (toothed whale) 时表现较好,而在识别须鲸 (baleen whale) 时表现较差,其中只有两个须鲸物种的得分超过了平均水平。
对于多目录物种,模型性能也存在差异。例如,普通小须鲸 (Balaenoptera acutorostrata) 不同目录之间的 MAP 得分分别为 0.79 和 0.60。其他物种如白鲸 (Delphinapterus leucas) 和虎鲸在不同目录之间的表现也有较大差异。
对此,研究人员虽然没有找到能解释这种目录级性能差异的原因,但他们发现一些定性指标如模糊度、独特性、标记混淆、距离、对比度和水花等,可能会影响图像的精度得分。

图 4:可能影响目录级性能差异的变量
图中每个点代表竞赛数据集中的一个目录,像素表示图像和边界框宽度。Distinct IDs 表示训练集中不同个体的数量。然而,目录级 MAP 与平均图像宽度、平均边界框宽度、训练图像数量、不同个体数量以及每个个体的训练图像数量之间并没有明确的关联。
综合以上,研究人员提出用该模型进行预测时,代表 7 个物种的 10 个目录平均精度高于 0.95,性能表现优于传统预测模型,进而说明使用该模型能正确识别个体。此外,研究人员还在实验过程中总结出 7 点关于鲸类研究的注意事项:
背鳍识别表现最佳。
明显个体特征较少的目录表现不佳。
图像质量很重要。
利用颜色识别动物可能较为困难。
特征相对于训练集差距较大的物种得分较差。
预处理仍然是一个障碍。
动物标记变化可能会影响模型表现。
Happywhale:鲸类研究的公众科学平台
本文数据集介绍中提到的 Happywhale 是一个分享鲸类图像的公众科学平台,其目标是解锁大量数据集、促进 photo ID 的快速匹配,并为公众创造科研参与度。
Happywhale 官网地址:https://happywhale.com/
Happywhale 成立于 2015 年 8 月,其联合创始人 Ted Cheeseman 是一位博物学家 (Naturalist),他在加利福尼亚蒙特雷湾 (Monterrey Bay) 长大,从小就喜欢观鲸,曾多次前往南极洲和南乔治亚岛探险,具有 20 余年南极探险及极地旅游管理的经验。

Happywhale 联合创始人 Ted Cheeseman
2015 年,Ted 离开了工作 21 年的 Cheesemans’ Ecology Safaris(由 Ted 父母在 1980 年创办的生态旅行社,Ted 父母同样是博物学家),投身 Happywhale 项目-- 收集科研数据,进一步理解并保护鲸类。
短短几年内,Happywhale.com 已经成为鲸类研究领域的最大贡献者之一,除鲸类识别图像的数量巨大外,对理解鲸类的迁徙模式也提供了诸多洞见。
本文首发于 HyperAI 超神经 微信公众平台。
参考链接:
[1]https://baijiahao.baidu.com/s?id=1703893583395168492
[2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0086132
[3]https://phys.org/news/2023-07-individual-whale-dolphin-id-facial.html#google_vignette
[4]https://happywhale.com/about
来源: HyperAI 超神经
