
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 中移科协
中移科协 
随着人工智能技术不断发展和应用,大语言模型在各个领域展现出了惊人的潜力和应用价值。其中,结合大语言模型与大型赛事的碰撞产生了独特的魅力,引发了人们对AI智能解说的探讨与关注,大语言模型的应用为赛事解说注入了全新的活力和新鲜感,同时也为观众带来了更加生动和沉浸式的观赛体验。本文将继续探讨AI智能解说大模型技术的应用和趋势。
1、应用实践
当前体育行业大部分为解说员人工输入,还有一些基于模板规则,解说形式比较单一,内容比较简单机械。传统体育解说人员解说词往往受限于个人风格,且难免会存在知识瓶颈和人工解说体力限制,直播行业兴起,体育直播二台大量主播赛事专业水平参差不齐。

图5 2024年巴黎奥运会AI智能文字解说(图源:咪咕视频)
而AI智能解说完美解决了如上问题。AI智能解说能按照赛况进程分为赛前分析、赛中解说、赛后小结环节,赛前分析主要对主客队的历史表现、基础信息做前瞻分析;赛中解说是对射门、进球、拦截、越位等42种重要事件类型做内容解说;赛后小结是对上下半场结束做进攻、防守、纪律等表现做小结分析,以此来丰富解说内容维度,提供沉浸式解说体验。
AI智能解说能力在2024年已上线“咪咕视频”欧洲杯和巴黎奥运会的足球比赛,支持40多种重要核心事件解说和TTS语音播报功能,以足球为试点后续扩展模型能力支持篮球、乒乓球、羽毛球等各大主流赛事,进一步提高行业影响力。
2025年世俱杯期间,AI智能解说全新升级,通过文体大模型自动生成多种风格文本供球迷选择:以诗化语言点燃赛场激情的“足球诗人”、用精准数据拆解战术博弈的“行走的数据库”,还有专注技术细节分析的“冷静客观”,三种风格可自由切换,不仅实时解读场上数据,更融入球队历史、球星故事等丰富周边信息,每场比赛都能拥有独一无二的听觉体验。
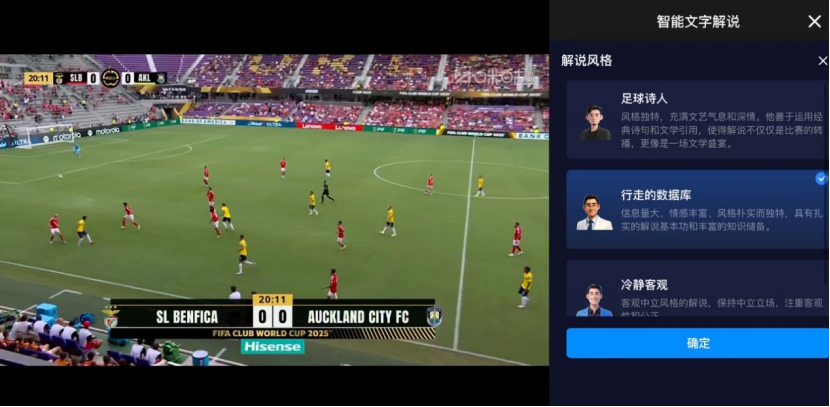
图6 2025年世俱杯多风格智能文字解说(图源:咪咕视频)
2、未来趋势
2.1 多模态数据深度融合:从“文本理解”到“全景感知”
目前大语言模型的输入和输出是文字,只有文本数据对比赛理解能力有限,后期可以使用多模态大模型同时处理视频图像、音频和文本数据,从而提供更全面的信息理解和更丰富的解说内容。
多模态大模型通过引入视觉信息,可以实现对比赛场景的实时分析,包括运动员的动作、球的位置、比赛节奏等。这不仅能够提高解说的准确性和实时性,还能够为观众提供更加生动和直观的观赛体验。
2.2 数智人解说:从“形象选择”到“个性化定制与情感共鸣”
数智人形象是指通过人工智能技术生成的虚拟人物形象,具有多种音色和多种形象选择。数智人形象不仅可以模拟真实主持人的语音和语调,还可以根据不同的比赛场景和观众需求,选择合适的形象和音色。
多种音色和形象选择可以满足不同观众的个性化需求。例如,年轻观众可能更喜欢活泼、幽默的解说风格,而年长观众可能更偏好传统、稳重的风格。通过选择合适的音色和形象,数智人解说员可以更好地与观众建立情感连接,提高观赛体验。
2.3 实时战术预测与沉浸式分析:从“事件播报”到“策略解读”
当前AI解说已能完成“赛后小结”,未来将升级为“实时战术预测+沉浸式分析”,让用户从“看比赛”升级为“懂比赛”,满足深度球迷对战术细节的需求。
基于大数据的实时战术预测:AI将整合球队过往5年的交锋数据、本赛季战术变化趋势、球员伤病与状态数据,在比赛过程中实时生成“概率性战术预测”。沉浸式战术可视化解说:结合AR技术,AI解说将同步生成“战术图示文字描述”(适配非AR观看场景)与“动态战术板”(适配AR观看场景)。
跨赛事的战术对比分析:AI将打破单一赛事的局限,实现“不同赛事、不同球队”的战术关联解读。
未来,AI智能解说将不再是“替代人工解说”的工具,而是“延伸人工解说能力、拓展观赛边界”的伙伴——它既能用大数据满足深度球迷的专业需求,也能用个性化互动吸引年轻观众,更能用无障碍服务让每一位体育爱好者感受到赛事的魅力,最终推动体育赛事传播进入“技术赋能、体验普惠”的新时代。
参考资料
[1] Vaswani A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.
[2] [2] Koroteev M V. BERT: a review of applications in natural language processing and understanding[J]. arXiv preprint arXiv:2103.11943, 2021.
[3] Guo M, Ainslie J, Uthus D, et al. LongT5: Efficient text-to-text transformer for long sequences[J]. arXiv preprint arXiv:2112.07916, 2021.
[4] Floridi L, Chiriatti M. GPT-3: Its nature, scope, limits, and consequences[J]. Minds and Machines, 2020, 30: 681-694.
[5] Recognition—ASR A S. Automatic Speech Recognition—ASR[J]. 2013.
[6] 高峰. 中国移动发布 “灵犀云” 智能语音平台[J]. 计算机与网络, 2016, 42(2): 14-15.
[7] Sangwan A, Chiranth M C, Jamadagni H S, et al. VAD techniques for real-time speech transmission on the Internet[C]//5th IEEE International Conference on High Speed Networks and Multimedia Communication (Cat. No. 02EX612). IEEE, 2002: 46-50.
[8] Mithe R, Indalkar S, Divekar N. Optical character recognition[J]. International journal of recent technology and engineering (IJRTE), 2013, 2(1): 72-75.
[9] Lin J, Tang J, Tang H, et al. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration[J]. Proceedings of Machine Learning and Systems, 2024, 6: 87-100.
[10] Frantar E, Ashkboos S, Hoefler T, et al. Gptq: Accurate post-training quantization for generative pre-trained transformers[J]. arXiv preprint arXiv:2210.17323, 2022.
[11] Dao T, Fu D, Ermon S, et al. Flashattention: Fast and memory-efficient exact attention with io-awareness[J]. Advances in Neural Information Processing Systems, 2022, 35: 16344-16359.
作者:
中国移动咪咕公司深圳研究院高级AI算法工程师 江利勤
中国移动咪咕公司北京研究院系统开发总监 毕蕾
审核:
中国移动咪咕公司北京研究院技术项目总监 邢刚
中国移动咪咕公司北京研究院资深系统架构与分析总监 徐嵩
中国移动咪咕公司科技创新部高级系统开发总监 何志
中国移动咪咕公司北京研究院前端开发总监 赵磊
来源: 中移科协
