
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 HyperAI超神经
HyperAI超神经 
在生命的复杂调控网络中,蛋白质-蛋白质相互作用(PPIs)协调着细胞内的信号传递、能量代谢和基因活动,是维持生命正常运转的基础。无论是健康状态下的生理平衡,还是疾病发生时的异常变化,PPIs 都发挥着核心作用。研究表明,PPIs的失常与癌症、神经退行性疾病及多种感染性疾病密切相关。因此,针对 PPIs 的药物开发已成为一个新药研发的重要方向。
早期科学家通过研究如 MDM2-p53 等蛋白质间相互作用,证实干预这类互作具有治疗疾病的潜力,尤其为以往难以靶向的疾病靶点提供了新思路。**然而,PPIs 的特殊性在于其作用界面通常较平坦,缺乏适合小分子药物嵌入的明确结构特征,这为药物研发带来巨大挑战。**尤其对新发现或结构信息有限的 PPIs 而言,寻找能够调控其功能的分子更为困难。
研究人员发现,尽管 PPIs 界面广阔平坦,但仍存在一些关键区域——称为「热点区域」(hot spots),它们如同互作中的「开关」,成为药物设计的理想靶点。
随着人工智能技术,特别是机器学习和深度学习的快速发展,针对 PPIs 的药物研发进程显著加快。多种创新算法与工具相继涌现,例如:2P2IHUNTER 可高效识别潜在 PPIs 抑制剂;PPIMpred 实现了大规模虚拟筛选;SMMPPI 不仅能预测调控分子,还在抗新冠病毒研究中展现出实用价值。尽管进展显著,挑战依然存在。传统计算方法多依赖相似性筛选,难以全面捕捉 PPIs 界面复杂的相互作用特征;同时,现有模型在不同类型蛋白质间的泛化能力有限,制约了新靶点药物开发的效率。
近年来,基于 Transformer 的预训练语言模型为上述问题提供了新思路,这些模型能够从大量蛋白质序列中自动学习关键特征,从而更智能地预测相互作用。
基于这一方向,中国石油大学和延世大学的联合研究团队整合了多项先进技术,构建了名为 AlphaPPIMI 的新框架。**该工具结合大规模预训练模型和自适应学习机制,旨在解决 「发现特异性靶向 PPIs 界面的调节剂」 这一核心挑战,**充分利用预训练大规模模型的优势,并通过专用交叉注意力模块有效建模复杂的结合模式,显著提升了模型在不同 PPIs 家族间的泛化能力,为未来 PPIs 靶向药物的开发提供了有力支持。
相关研究成果以「Alphappimi: a comprehensive deep learning framework for predicting PPI-modulator interactions」为题,发表于 Journal of Cheminformatics。

论文地址:
https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01077-2
关注公众号,后台回复「AlphaPPIMI」获取完整 PDF
更多 AI 前沿论文:
https://hyper.ai/papers
数据集:以 DLiP 为核心的 PPIs 数据集体系构建
**该研究以 DLiP 数据集为训练核心,这个数据集包含 120 种 PPIs,以及对应的 12,605 个独特调节剂,**还能提供每对蛋白复合物的序列、三维结构和实验活性数据,能为模型搭建提供全方位支撑。
为了做独立验证,研究团队从 DiPPI 和 iPPIDB 两个数据库里,构建了两个基准测试集——两个测试集里都有经过实验验证的界面调节剂,以及它们的结构和结合信息。整理数据时,团队做了三项质量把关:只保留异源二聚体形式的 PPIs,去掉结合位点不明确的样本,把范围限定在人类 PPIs;另外,对能作用于多个靶点的化合物进行拆分,确保注释准确。
最终两个基准集的具体情况如下:**DiPPI 包含 201 种调节剂,对应 1,316 个 PPIs 靶点,**每个样本都有分子结构、蛋白序列、界面结构和活性标签;iPPIDB 则涵盖 2,203 种调节剂和 34 种 PPIs,所有蛋白序列都来自 UniProt 数据库,保证了数据一致性。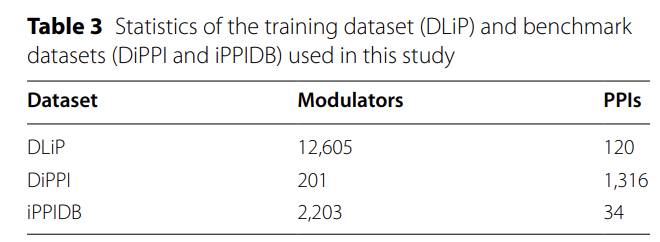
本研究中使用的训练数据集(DLiP)和测试数据集(DiPPI 和 iPPIDB)
对两个基准集做理化性质分析后发现,它们在界面靶向特性和化学空间分布上差异很明显,这会增加模型泛化的难度。**通过计算 ECFP4 分子指纹还发现,两个基准集里化合物的平均塔尼莫托相似性很低,**说明这些化合物的结构多样性比较高。
针对某一个 PPIs 家族,该研究还挑选对其他 PPIs 家族有选择性的调节剂作为潜在非活性样本,同时排除和已知活性调节剂结构相似的分子,以此降低假阴性风险。考虑到正负样本数量不平衡,团队对阴性样本进行下采样,构建出数量均衡的数据集。后续敏感性分析显示,不管正负样本比例怎么调整,模型表现都很稳定,对比例的依赖性不高。需要说明的是,虽然有已验证的非活性化合物,但因为它们分布不均匀,加入后可能导致数据偏差,所以没被纳入阴性样本集。
为了验证这套方法的实际应用价值,**研究团队还对 ChemDiv 数据库中的「PPIs 专用库」进行了筛选——这个库包含 205,497 种专门针对 PPIs 界面特性设计的化合物。**通过这次大规模虚拟筛选,证实了这种方法在药物研发场景中的实用效果。
AlphaPPIMI 框架:多源特征提取、双向交叉注意力及 CDAN 泛化优化
如下图所示,**该研究开发了一款新型计算框架 AlphaPPIMI,专门用于预测 PPIs 与调节剂的结合关系,**特别侧重于靶向界面结合位点类的相互作用。这款框架整合了 Uni-Mol2、ESM2、ProTrans、ECFP、PFeature 等多个先进模块,力求全面提取 PPIs 相关特征,同时实现高效的表征学习。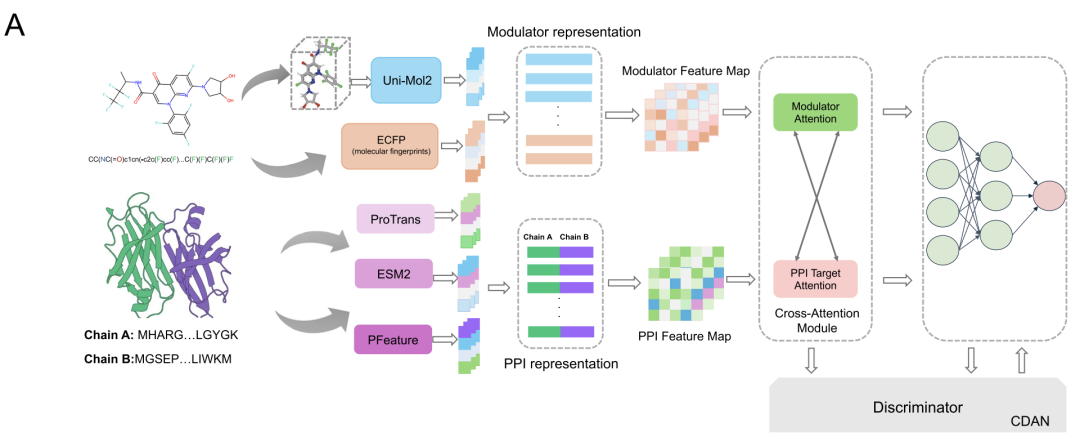
AlphaPPIMI 的架构概述
**在分子表征环节,研究团队采用了含 8,400 万参数的 Uni-Mol2 模型,将原子、化学键、几何信息与分子指纹整合起来,**为每个调节剂生成 768 维的全局特征向量。同时,团队还引入 ECFP4 指纹,生成 1,024 维二进制向量,以此捕捉环状子结构等关键化学信息。最终,这两类特征整合得到 1,792 维特征向量,既涵盖分子拓扑结构、三维几何形态,也包含化学子结构,为界面结合预测提供了可靠的数据支撑。
**蛋白质特征提取(protein feature extraction)则采用了三种互补方法:**ESM2-150M 模型基于 Transformer 架构,在 6,000 万条 UniRef50 序列上完成训练,能生成 640 维特征向量,专门捕捉与界面形成相关的氨基酸关系;ProtTrans 模型在超过 4,500 万条蛋白质序列上训练,输出 1,024 维嵌入向量,其捕捉到的进化模式可与 ESM2 形成互补;还有 PFeature 方法,通过 19 类描述符提供蛋白质的结构与理化属性信息。这三种方法融合后,生成 3,366 维的蛋白质表征,全面覆盖了蛋白质的序列模式和界面特异性属性。
为了建模蛋白质与调节剂之间的复杂相互作用,如下图所示,AlphaPPIMI 设计了双向交叉注意力模块(Cross-Attention Module)。这个模块先对调节剂特征矩阵 FM 和靶点特征矩阵 FP 做线性变换,再输入注意力子模块,从而实现键-值对层面的双向信息交换:PPIs 特征会通过调节剂来源的注意力权重优化,调节剂特征则借助 PPIs 驱动的注意力机制调整。**模块中还加入了残差连接和最大池化操作,**能在保留各模态特有信息的同时,动态学习两者的相互作用模式,最终输出更全面的相互作用表征。
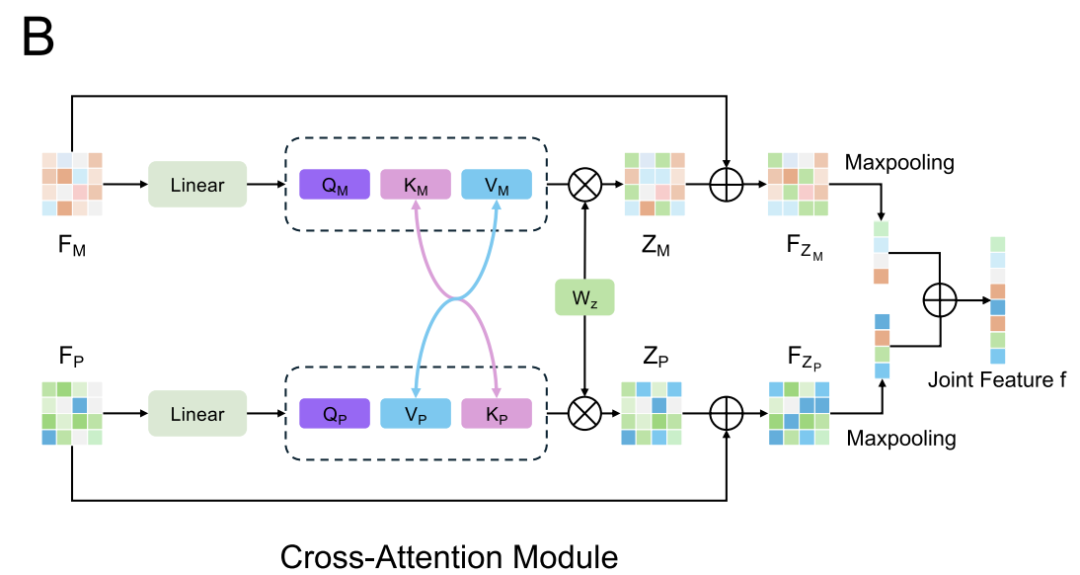
交叉注意力模块
考虑到不同数据集的特征分布存在差异,比如 DiPPI 主要关注界面靶向调节剂,而 DLiP 这类通用数据集却缺乏此类信息,如下图所示,AlphaPPIMI 还引入了条件域对抗网络(CDAN,Conditional Domain Adversarial Network)。CDAN 以 「特征嵌入与分类预测的联合表征」 作为域判别器的条件,既能保留有判别价值的特征,又能实现源域与目标域间的分布对齐。**训练过程采用极小极大博弈:特征提取器(Feature Encoder)和交叉注意力模块负责生成域不变表征,鉴别器则用来区分特征的来源。**这一机制大幅提升了模型在不同蛋白质家族间的泛化能力,为识别新颖的界面靶向调节剂提供了更稳健的支持。
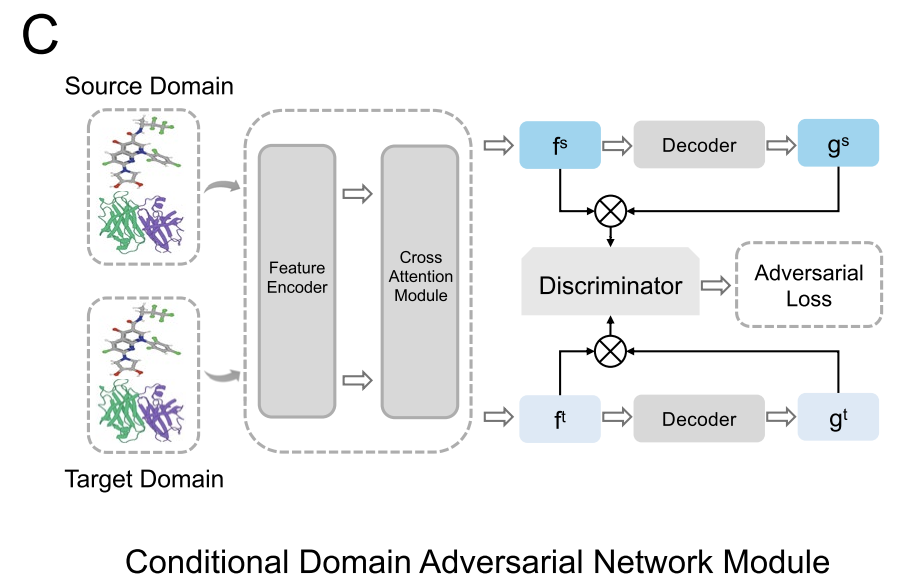
条件域对抗网络模块
AlphaPPIMI 的跨领域泛化能力评估与应用验证
**为了检验 AlphaPPIMI 在预测 PPIs 调节剂时的跨领域适应能力,研究团队设计了迁移实验——**把 DLiP 数据集当作「源域」(source domain,用于模型训练的数据),DiPPI 和 iPPIDB 数据集当作「目标域」(target domains,用于模型验证的数据)。
**实验结果显示,所有模型在领域偏移下性能均下降,但 AlphaPPIMI 稳健性更强,**其在 DiPPI 上的 AUROC 与 AUPRC 显著高于 MultiPPIMI,跨域与域内性能差距凸显领域自适应策略的必要性。如下图所示,研究进一步提出 AlphaPPIMI-CDAN 架构,通过条件特征对齐实现跨域分布适配,该模型在 DiPPI 与 iPPIDB 上全面优于基准模型;不同于传统边缘对齐方法,其依据类别条件分布指导特征对齐,生成更具判别性的表征,可有效应对 PPIs 领域功能性细微差异带来的分布偏移,同时减轻负迁移以提升跨域预测稳健性与泛化能力。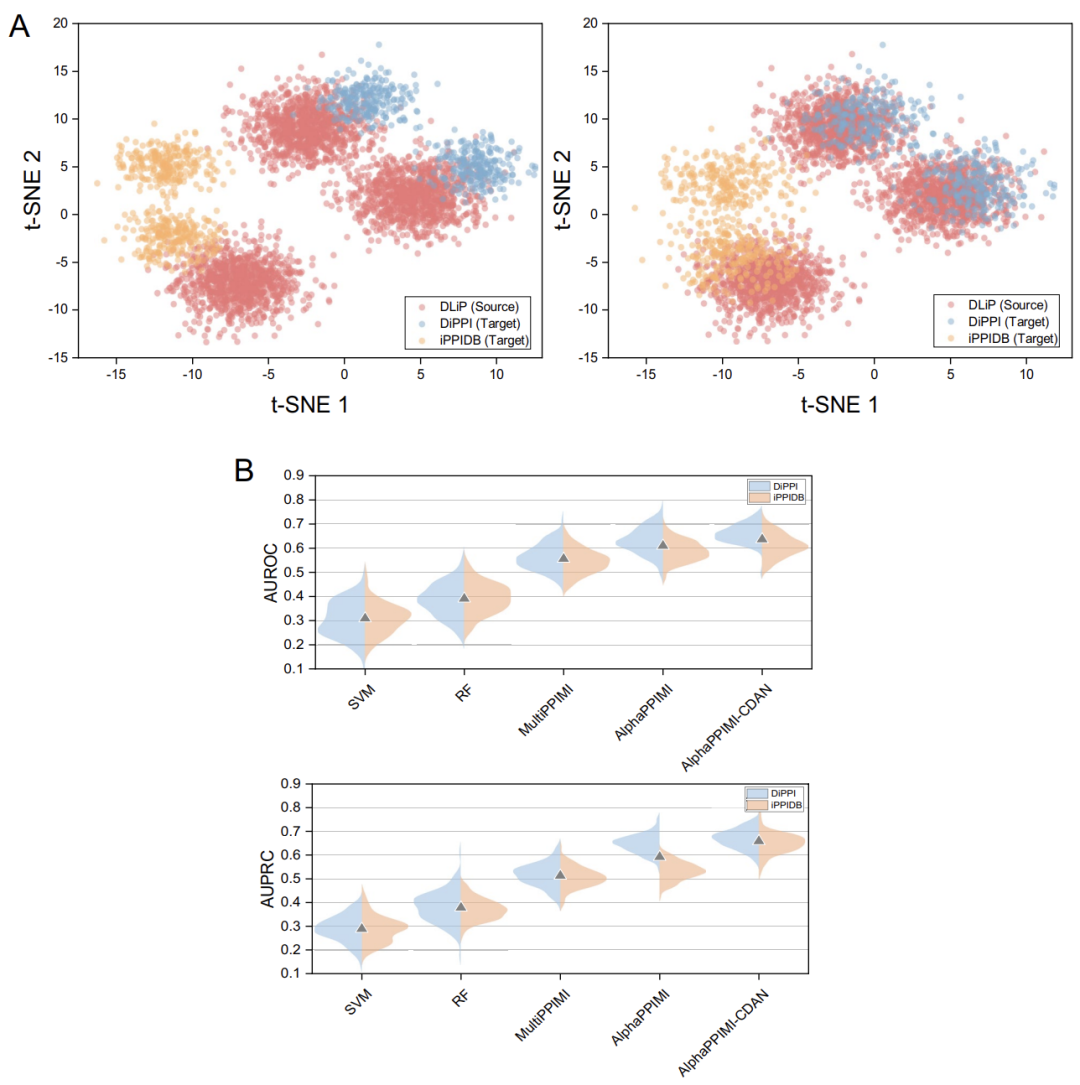
跨域特征分布分析与性能比较
**在实际应用验证中,该研究还以界面结构明确且为抗癌关键靶点的 Hsp90-Cdc37 PPIs 为对象,**如下图 A 所示,AlphaPPIMI 筛选 ChemDiv 库中预测分数>0.8 的化合物,其化学空间与已知活性抑制剂分布接近;如下图 B 所示,研究人员以已验证抑制剂 DCZ3112 为参考,经结构相似性与药效团分析筛选出 3 个候选化合物;如下图 D–E 所示,分子对接显示这些化合物可与 Arg32、Ser36 等关键残基形成类似参考分子的相互作用,提升其抑制剂潜力。
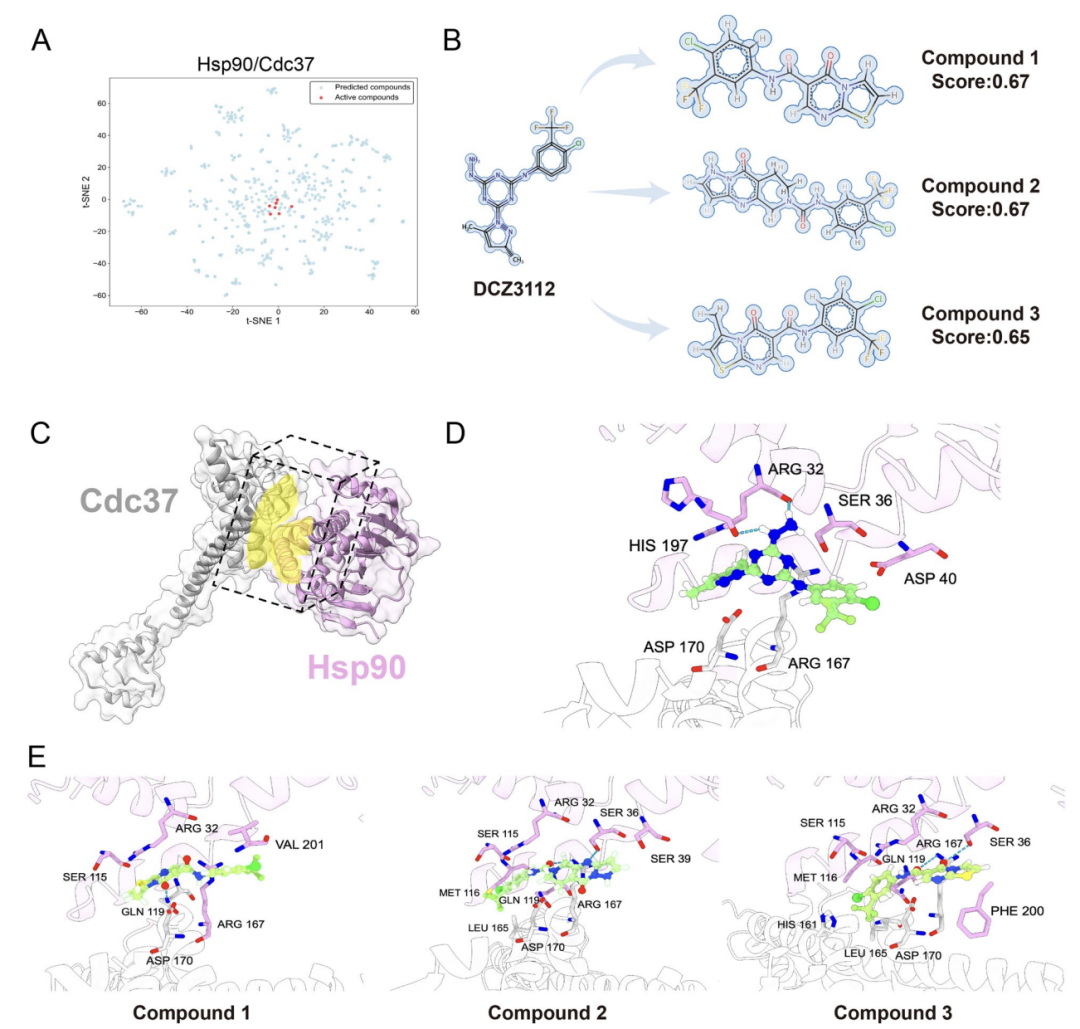
Hsp90-Cdc37 潜在 PPI 抑制剂的鉴定和结构分析
针对 AlphaPPIMI 在筛选变构 PPIs 调节剂中的应用,如下图 A 所示,研究人员以 HIV-1 gp120 与 CD4 的相互作用为例,AlphaPPIMI 筛选出预测概率>0.8 的化合物,其化学空间与已知活性抑制剂重叠度高;如下图 B-C 所示,基于非典型界面结构(PDB: 6L1Y)的分子对接结果显示,候选化合物可与 THR51、LEU52、PHE53 等关键残基相互作用,表明 AlphaPPIMI 可发掘针对难成药 PPIs 界面的别构型抑制剂,为相关药物开发提供新途径。
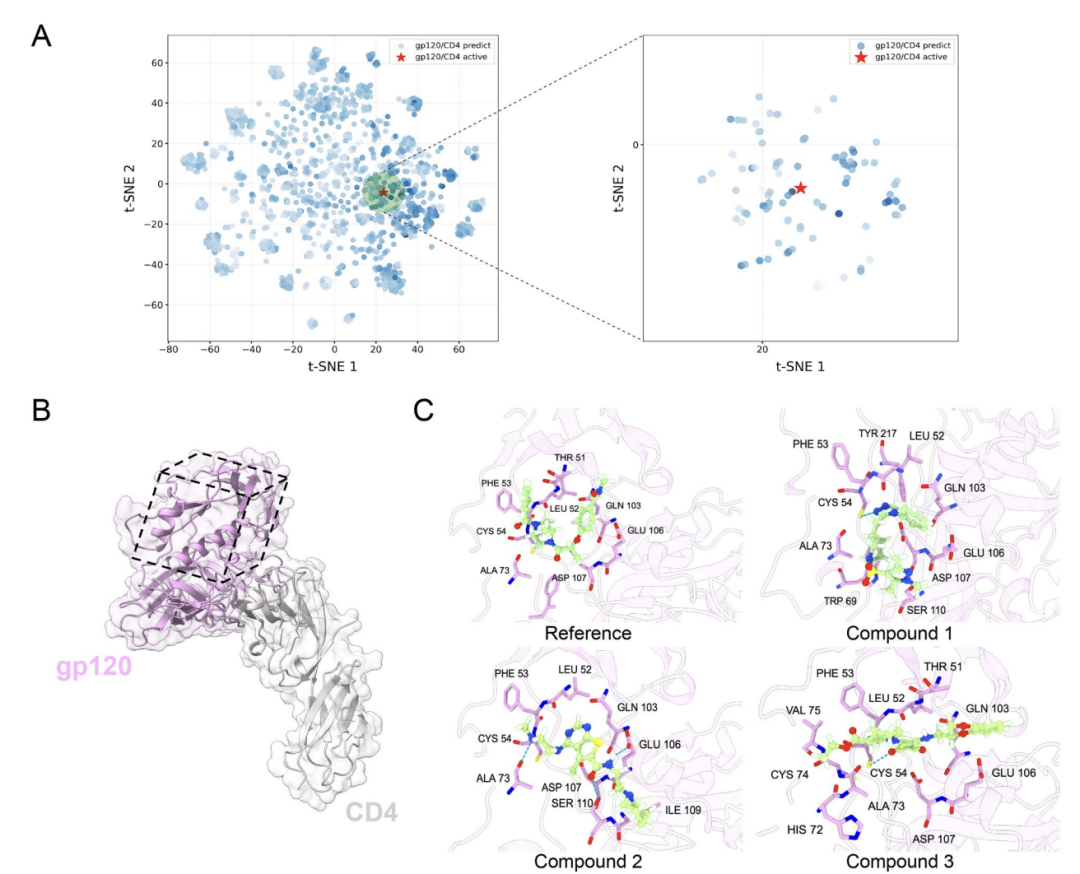
gp120/CD4 PPIs 抑制剂的虚拟筛选
产学研推动 PPIs 靶向药物从基础研究到临床应用
在 PPIs 靶向药物的研发中,学术界和工业界正靠紧密合作,一步步把这个领域的基础研究推向临床应用。
在学术前沿,不少研究团队都在探索更精准、更高效的 PPIs 预测和靶向方法。**比如斯坦福大学的团队,就研发了一款通用生物医学 AI 智能体——Biomni,**该智能体能够自主完成横跨遗传学、基因组学、微生物学、药理学和临床医学等多个生物医学分支领域的复杂研究任务。Biomni 的诞生标志着 AI 在生物医学研究中从「工具使用者」向「自主决策者」的跃迁。通过将分散的科研资源整合为可操作的智能体行为单元,不仅破解了传统研究流程的碎片化瓶颈,更可能催生跨学科、高通量的自主化科学发现引擎。
还有一项有代表性的研究,**中山大学提出了一种基于融合特征提取与新型无监督特征选择机制的 PPIs 预测方法。**大量实验表明,该方法在五个涵盖种内和种间相互作用的数据集上表现优异,预测性能显著优于 16 种现有机器学习方法。该研究不仅为大规模 PPIs 预测任务提供了高效可靠的框架,还展现出广泛的功能适应性,为药物-药物及药物-食物相互作用预测研究提供了新的解决方案。
到了产业转化环节,企业也在积极把这些学术突破推向临床。比如中国生物医药科技公司 Adlai Nortye 公司基于从诺华获得全球授权所开发的 AN2025(通用名buparlisib),是专门靶向 PI3K 信号通路的泛抑制剂,现在已经进入全球 III 期临床试验,主要用于治疗那些接受过抗 PD-1/PD-L1 治疗后仍进展的复发或转移性头颈部鳞癌患者。
再比如法国知名药企 Ipsen 公司推出的 Iqirvo(elafibranor),作为近十年首个获批的 PBC 新疗法,它验证了非肿瘤领域 PPI 调控的临床价值,为复杂代谢疾病提供了全新治疗范式,其获批也推动了对 PPAR 家族蛋白相互作用网络的深入探索。
学术界和工业界在 PPIs 靶向药物领域的深度配合,不光加快了科研成果向临床价值的转化,还大大提高了新药研发的效率和成功率。从多模态 AI 预测模型,到能带来明确临床获益的候选药物,这种跨领域协作的模式,正在重新定义生物医学创新的路径。未来,随着更多数据、算法的整合,加上跨机构、跨学科合作的进一步深化,PPIs 靶向药物说不定能给复杂疾病的治疗带来更多突破。
参考链接:
1.https://mp.weixin.qq.com/s/ryYJ6T7qEjnjvkhBL4-dAA
2.https://mp.weixin.qq.com/s/7upIPYam1LR0TiGBYXmkOw
3.https://mp.weixin.qq.com/s/69GU1R5lXHdTLttlT8apyw
来源: HyperAI超神经
