
 科普中国公众号
科普中国公众号
 科普中国微博
科普中国微博

 帮助
帮助
 新疆维吾尔自治区巴音郭楞蒙古自治州尉犁县科学技术协会
新疆维吾尔自治区巴音郭楞蒙古自治州尉犁县科学技术协会 2024一开年,中美AI行业发生了两件大事,进一步把1993年启动的第三次人工智能浪潮推向高潮:OpenAI上线了GPT商店,AI的商业化进程更进一步;1月16日,中国智谱AI推出了比肩GPT-4的GLM-4大模型,为中国在全球AI领域的竞争增加了一份筹码。
人工智能风云70余载,几起几落,沉沉浮浮,拼人才、拼算力、拼资金、拼算法,哪些故事需要铭记,哪些教训又值得审视?
跨越七十年的华丽篇章
只为把“智能”装进机器
阿兰·图灵是一位传奇人物,他不仅仅是每一位当代程序员的“祖师爷”,图灵还是一位世界级长跑运动员,马拉松成绩2小时46分03秒,只比1948年奥运会金牌成绩慢11分钟。二战期间,他领导“Hut 8”小组破译德军密码,成为盟军在大西洋战役中击败轴心国海军的关键因素。

图灵也是个马拉松运动员|midjourney
当然,我们今天要说的还是“人工智能”。
图灵被誉为计算机科学与人工智能之父,1950年,图灵第一次提出“机器智能(Machine Intelligence)”的概念,“人类利用可用信息和推理来解决问题并做出决策,那么为什么机器不能做同样的事情呢?”
自那时开始,无数科学家、科技企业为之奋斗——赋予机器以“智能”的革命悄然拉开了序幕。70多年过去,“三次浪潮,两次低谷”, 人工智能终究是冲破层层阻隔,进入了大众的日常生活。
纵观三次人工智能浪潮,我们会发现一个有意思的现象:理论总是比现实更超前。不是科学家设计不出更好的人工智能,而是囿于当时的计算机技术,无法做到。
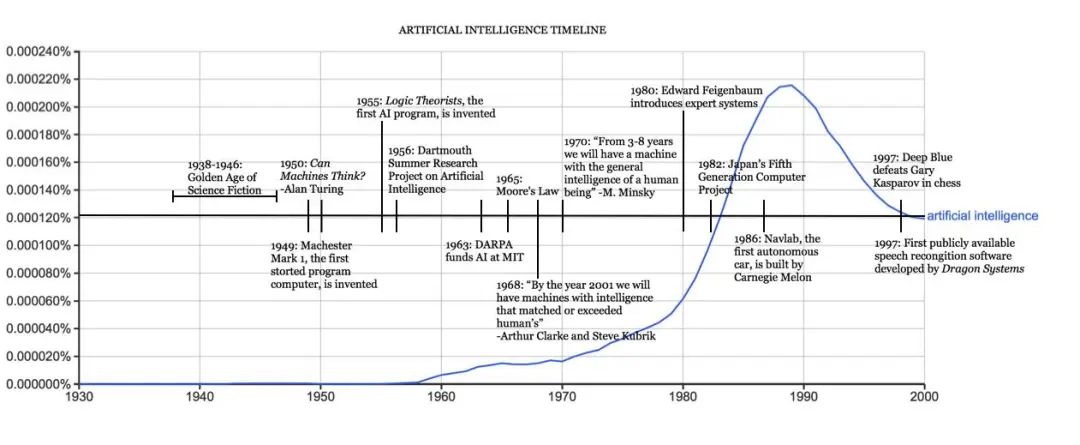
人工智能发展大事年表|哈佛大学官网
图灵在1950年的论文《计算机器与智能》中已经提出了机器思维的概念和著名的图灵测试,是什么阻止了图灵开始工作?有两个原因。首先,在那个年代,计算机缺乏智能的一个关键先决条件:它们无法存储命令,只能执行命令。这意味着,计算机只能被告知要做什么,但是不记得自己做了什么。第二,计算成本在上世纪50年代太昂贵了,租赁一台电脑每个月需要20万美元,笔者根据通货膨胀率做了换算,这相当于现在每月租金254万美元,名副其实的“有钱人的游戏”。

名副其实的“有钱人的游戏”|midjourney
科学家之所以称之为科学家,是因为他们的研究总是着眼于未来,即使当下缺乏变成现实的条件。
图灵发表那篇著名的论文后仅两年,计算机科学家阿瑟·萨缪尔(Arthur Lee Samuel)开发出一款跳棋程序,并提出了“机器学习”这个概念。1956年的达特茅斯会议上,约翰·麦卡锡(John McCarthy)正式提出了“人工智能”这个词语,1956年,也就成为了实际意义上的人工智能元年。
至此,“人工智能”跨越了混沌初开的早期阶段,进入了一个高速发展时期。多年后,当大众回看那个时代,称之为人工智能的“第一次浪潮”。

计算机科学与人工智能之父——阿兰·图灵
我们先来看看“第一次浪潮”给我们今天的生活留下了哪些遗产吧。说出来可能有些惊讶,我们今天使用的大多数软件追根溯源都是“第一次浪潮”的产物,或者说,基于一种叫“手动编码知识(Handcrafted Knowledge)”的人工智能。比如我们的Windows系统,智能手机应用程序,人行道上按下按钮等待红灯变绿的交通灯。这些都是人工智能(此处采用第一次浪潮中对人工智能的定义)。
这真算“人工智能”?
算。
人们对人工智能的理解一直在变化。30年前,如果你问路人,谷歌地图算不算人工智能,得到的答案是肯定的。这个软件能帮你规划最佳路线,还能用清晰的语言告诉你如何行驶,为什么不算?(谷歌地图应用确实是第一波人工智能的典型案例)
第一次人工智能浪潮主要基于清晰且逻辑的规则。系统会检查需要解决的每种情况下最重要的参数,并就每种情况下采取的最适当的行动得出结论。每种情况的参数均由人类专家提前确定。因此,这种系统很难应对新的情况。他们也很难进行抽象——从某些情况中获取知识和见解,并将其应用于新问题。
总而言之,第一波人工智能系统能够为明确定义的问题实现简单的逻辑规则,但无法学习,并且很难处理不确定性。
1957年,罗森布拉特发明感知机,这是机器学习人工神经网络理论中神经元的最早模型,这一模型也使得人工神经网络理论得到了巨大的突破。乐观的情绪在科学界蔓延,第一次人工智能浪潮逐渐被推向了高潮——挫败要来了。

感知器原理图|加利福尼亚州立大学
1966年,人们发现好像人工智能的路走歪了。逻辑证明器、感知器、强化学习等等只能做很简单、非常专门且很窄的任务,稍微超出范围就无法应对。为了更好的理解,我们建议读者脑补使用Windows系统的体验:一切功能都是提前设计好的,你无法教会这个系统做什么事,它也无法自己学习额外的知识。
另一方面,当时的计算机面临内存有限和处理速度不足的挑战,解决实际的人工智能问题变得十分困难。研究者们迅速认识到,要求程序具备儿童般的世界认知水平是一个过高的期望。在那个时候,没有人能够构建出满足人工智能需求的庞大数据库,也没有人知道如何让程序获取如此丰富的信息。与此同时,许多计算任务的复杂度呈指数级增加,使得完成这些任务变得几乎不可能。
科学家进入了死胡同,人工智能发展也进入了“蛰伏期”。
这一等,就是十多年。
当时间来到了20世纪80年代,两个关键突破重新点燃了“第二次人工智能浪潮”:深度学习和专家系统。
约翰·霍普菲尔德 (John Hopfield) 和大卫·鲁梅尔哈特 (David Rumelhart) 推广了“深度学习”技术,使计算机能够利用经验进行学习。这意味着人工智能可以处理那些“没有提前设定”的问题,它具备了学习能力。另一方面,爱德华·费根鲍姆(Edward Feigenbaum)引入了专家系统,它模仿了人类专家的决策过程。
总的来说,第二次人工智能浪潮改变了人工智能的发展方向。科学家放弃了符号学派思路,改用统计学的思路来研究人工智能。深度学习和专家系统的引入让机器能够根据领域内的专业知识,推理出专业问题的答案。
因此,第二次人工智能浪潮也叫“统计学习(Statistical Learning)”时代。
关于这一次浪潮,笔者想要强调两点,第一,为何它如此重要?第二,它无法克服的弊端是什么?
第二次浪潮时间很短,但通过引入“统计学习系统”,工程师和程序员不会费心去教授系统要遵循的精确规则(第一次浪潮的理念)。相反,他们为某些类型的问题开发统计模型,然后在许多不同的样本上“训练”这些模型,使它们更加精确和高效。
此外,第二波系统还引入了人工神经网络的概念。在人工神经网络中,数据经过计算层,每个计算层以不同的方式处理数据并将其传输到下一个级别。通过训练每一层以及整个网络,它们可以产生最准确的结果。

神经网络示意图|Pixabay
这些都为第三次人工智能浪潮奠定了基础,而且留下了庞大的遗产,我们今天依然在使用。比如人脸识别、语音转录、图片识别,以及自主汽车和无人机的部分功能,都来自于这次浪潮的成果。
但是,这套系统有一个巨大的弊端。根据美国国防高级研究计划局(DARPA)指出,我们尚不清楚人工神经网络背后的实际运行规则,也就是说,这套系统运行良好,但是我们不知道为什么运行的这么好。这就好比人可以把球抛到空中,并且能大概判断球会落在哪里,如果你问他,你是如何做出判断的,是根据牛顿力学定律计算的吗?他无法回答,但他就是知道。
这暴露了一种因果关系挑战,因为“看不到因果”。第二套系统依赖数据输入,数据输出做决策,缺乏因果会导致严重后果:这个系统容易学坏。
微软曾经设计了一个机器人叫“Tai”,他可以顺畅的和人聊天,但如果有越来越多的人告诉他“希特勒是个好人”,它就会逐渐接受这个结论。
这些难题,留给了第三次人工智能浪潮来解决。
这次浪潮也是目前我们所正在经历的,也称之为“情景适应(Contextual Adaptation)”。如果非要确定一个时间节点,应该是1993年之后。摩尔定律让计算机算力急速提升,大数据的发展让海量数据存储和分析成为可能。

来源:开源图库Pixabay
为了更好的说明和上一次人工智能浪潮的区别,我们可以用一张图片举例。如果用第二次的系统来回答“图片里的动物是什么?”你会得到“图片里是一头牛的可能性为87%”。如果同样的问题给到第三次系统,它不仅告诉你这是一头牛,还会给出符合逻辑的理由,比如四只脚、有蹄子,身上有斑点等等。
换句话说,第三次的系统更讲逻辑。
笔者认为,第三次人工智能浪潮有3个重要节点(通常认为是前两个)。2006年,杰弗里·辛顿(Geoffrey Hinton)发表了《一种深度置信网络的快速学习算法》,在基层理论上取得若干重大突破。2016年,谷歌DeepMind研发的AlphaGo在围棋人机大战中击败韩国职业九段棋手李世乭,这标志着“人工智能”从科研领域开始迈向公众领域,从学术主导走向商业主导。
此后便是2022年11月30日,OpenAI发布ChatGPT,让AI成为了一款消费级产品。“生成式AI”和“大语言模型”一时成为大众热议的焦点。
生成式AI的竞赛,
我们要拼的是什么?
“生成式AI”是人工智能的一个分支,通过利用大型语言模型、神经网络和机器学习的强大功能,能够模仿人类创造力生成新颖的文字、图片和音、视频等内容。
大众看到的OpenAI有多辉煌,那成立之初就有多落寞。那时候的OpenAI面临两个困境:一是缺乏资金,二是其技术路线不被主流所认可。
根据机构测算,直到2019年OpenAI共接受的捐助总额仅为1.3亿美元,也就10亿人民币,马斯克个人捐助最多。当然,这点钱和国内创业公司动辄上百亿的融资比不值一提。由于缺乏资金,OpenAI不得不依靠捐赠,2016年,英伟达赠送给OpenAI一台DGX-1超级计算机,帮助其缩短了训练更复杂模型的时间(从6天到2小时)。
2018年,就连之前的最大捐赠来源马斯克也离开了OpenAI。他曾经提议接管OpenAI,但遭到董事会拒绝,于是离开,并且此后没有再进行捐赠。
另外一方面,OpenAI选择了一条不好走的路——先研发预训练模型。2018年,OpenAI推出了具有1.17亿个参数的GPT-1(Generative Pre-training Transformers, 生成式预训练变换器)模型,这一年也叫预训练模型元年。
为何这个于预训练模型的发布如此重要?这标志着AI进化路线的转变,在此之前,的神经网络模型是有监督学习的模型,存在两个缺点:
首先,需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;第二,根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP(自然语言处理)。
预训练模型则很好的解决了上述问题。
2020年,OpenAI发布了第三代生成式预训练 Transformer,即GPT-3。这一事件同样成为了大洋彼岸另一家中国AI初创企业的转折点——智谱AI。
GPT-3 的发布给了大家非常明确的信号,即大型模型真正具备了实际可用性。在反复纠结和讨论后,智谱 AI 终于决定全面投身大模型,成为了国内较早介入大模型研发的企业之一。
同样,智谱AI投入了大量的研发资源在预训练模型上。2022年,GLM-130B发布,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。评测报告显示GLM-130B在准确性和公平性指标上与GPT-3 175B (davinci) 接近或持平,鲁棒性、校准误差和无偏性优于GPT-3 175B。

实际上,GLM-130B是中国科技公司智谱AI发布的一个“预训练模型”。“预训练模型”是训练“大预言模型”的模型。它的位置比大众接触到的“生成式AI”更加前置,是埋藏在海平面之下的基础设施。现在市面上可供使用的预训练模型不多,比较主流的是来自OpenAI的GPT,以及来自谷歌的Bert。GLM-130B正是结合了以上两个框架优点的国产自主研发预训练模型。
智谱AI则是奋起直追,对标OpenAI,成为了阿国内唯一一个对标OpenAI全模型产品线的公司。
2020年,OpenAI推出GPT-3
2021年,OpenAI推出DALL-E
2022年12月,OpenAI推出了轰动一时的ChatGPT
2023年3月,OpenAI推出GPT-4
对比智谱AI和OpenAI的产品线,我们可以看到:
GPT vs GLM
- ChatGPT vs. ChatGLM(对话)
- DALL.E vs. CogView(文生图)
- Codex vs. CodeGeeX (代码)
- WebGPT vs. WebGLM (搜索增强)
- GPT-4V vs. GLM4 (CogVLM, AgentTuning) (图文理解)
为何抢占生成式AI的高地如此关键?
2023年的一句论断可以回答这个问题,“所有产品都值得用AI重做一遍”。AI对各个行业的的效率提升是革命性的,这种提升发生在服务业、新药研发、网络安全、制造业升级各个方面。
根据中国信通院的数据,2023年中国的人工智能专利申请量和论文发表量都位居世界第一,中国的人工智能市场规模也在不断扩大,预计到2023年将达到5132亿美元,占全球的近四分之一。
“工欲善其事必先利其器”。在“利器”GLM-130B训练下,智谱在2023年10月推出了自研第三代对话大模型 ChatGLM3,此时距离发布上一代产品ChatGLM2仅过去4个月。
2024年1月16日,距离ChatGLM3发布不到3个月,公司又推出了GLM-4,GLM-4 相比 GLM-3 性能全面提升 60%。其各项参数已经达到了比肩GPT-4的程度。在基础能力指标MMLU 81.5、GSM8K 87.6、MATH 47.9和BBH 82.25等项目上,GLM-4已经达到GPT-4 90% 以上水平。HumanEval 72 达到 GPT-4 100%水平。
对齐能力上,基于AlignBench数据集,GLM-4超过了GPT-4在6月13日发布的版本,逼近GPT-4最新效果,在专业能力、中文理解、角色扮演方面超过GPT-4精度。
GLM-4 还带来了 128K 上的长文本能力,单次提示词可处理文本达到 300 页。在 needle test 大海捞针测试中,128K 文本长度内 GLM-4 模型均可做到几乎百分之百精度召回。
同时,GLM-4大大增强了多模态能力以及Agent能力,GLM-4 可以实现自主根据用户意图,自动理解、规划复杂指令,自由调用WebGLM搜索增强、Code Interpreter代码解释器和多模态生成能力以完成复杂任务。GLMs个性化智能体定制能力也同步上线。不需要代码基础,用户用简单的提示词指令就能创建属于自己的GLM智能体。
其实智谱AI的发展路径也符合AI行业的内在规律。“人工智能不是一个简单的从1到100进步的过程,它往往趋向于两个极端:要么90分以上,其它的都是10分以下。”换言之,要么“快速突破”,要么“原地打转”,不奋力前进就只能滑入另一个极端。
回到历史时间线里,我们目前正处在第三次人工智能浪潮当中,既然有浪潮,就有高潮与低谷。第三次浪潮会结束,什么才是推动它的关键?
有一种观点认为“深度学习算法”带来的技术红利,将会支撑我们前进5-10年,随后瓶颈就会到来。在瓶颈到来之前,我们急切需要一个“技术奇点”拿过接力棒,把这次浪潮推到更高的高度。
“技术奇点”在哪里尚不可知。但有一点可以确定,它的出现有赖于企业的长期投资、深度研发和对科技的信念。
来源: 果壳
