大模型时代的视觉知识:回顾与展望
王文冠,杨易,潘云鹤
浙江大学计算机科学与技术学院,中国杭州市,310027摘要:视觉知识是一种新型知识表达形式,其理论之根深植于认知科学,旨在为视觉智能的核心要素,如视觉概念、视觉关系、视觉操作和视觉推理,提供统一、全面且可解释的理论框架和建模方法。认知科学的研究实证了视觉相关知识在人类认知过程和智能行为中扮演着不可或缺的角色,由此可以推断,视觉知识的表达与学习将对发展视觉智能和机器智能起到重要作用。近年来,人工智能不断取得进步,尤其是人工智能大模型涌现出超越传统模型的智能水平,大模型能够自动从海量数据中发现普遍性规律,并将这些规律编码进超大规模神经网络的参数之中,实现了大规模知识自动提取和隐式知识参数化存储。这场由大模型驱动的新一轮人工智能技术革命,将为构建具备视觉知识的先进智能体带来新的机遇和挑战。对此,本文深入剖析了视觉知识的理论基础,并系统性地回顾了近年来视觉知识相关领域的发展状况。同时,针对大模型时代下视觉知识的发展方向以及其可能发挥的关键作用,提出了前瞻性的观点和展望。关键词:视觉知识;人工智能;基础模型;深度学习
1 引言
视觉知识[1] 是一种新型知识表示形式,有别于传统的符号人工智能(symbolic AI)和亚符号人工智能(sub-symbolic AI)所采用的知识表示手段(如知识图谱、手工制定的图像描述算子、分布式视觉表征),视觉知识理论是在认知心理学对人类视觉心象(mental imagery)和视觉记忆(visual memory)的研究[2] 基础之上,为实现更强大的人工智能所提出的统一的、抽象的、可解释的知识表示框架。该理论既能够充分表征视觉概念及其属性(如形状、结构、运动和功能等),也能够全面描述这些视觉概念之间的复杂关系,如变换、操作、预测和推理等。
语言大模型(large language models),如 GPT-3[3],显著推动了自然语言处理技术的进步:传统的“狭隘”的语言模型只能在某一单一领域执行特定任务,而在海量文本数据上训练的超大规模语言模型可以跨领域完成多种语言任务。“Segment Anything Model”(SAM[4])模型的出现开启了计算机视觉领域的“GPT 时代”,SAM 采用1100 多万张自然图像及 10 亿多个分割掩码进行训练,可以在不针对特定任务或领域进行额外训练或微调的情况下分割对象,展现出极强的跨领域适用性。总之,大模型正在以惊人的速度引发新一轮人工智能技术革命的浪潮,甚至有望为整个科学研究领域带来变革。
尽管人工智能大模型取得了重大技术突破,但仍然存在很多缺陷,影响了其可靠性和可用性。其中一个重要缺陷是大模型的高度不透明性,这对其可靠性、可解释性和可调试性构成了严重威胁。此外,大模型对数据和计算资源有着近乎无限的需求,这在道德和环境方面引发公众担忧。大模型这些缺陷源自于联结主义网络架构,并被大模型的高度复杂性和超大规模而放大。更加令人担忧的是,人工智能大模型容易产生无意义或不真实的输出,即所谓“幻觉”(hallucination)问题,这表明大模型存在严重的固有偏见、缺乏对世界的真实理解、并且难以将习得的知识策略应用到新的领域。
考虑到视觉知识在视觉概念的表征、操纵与推理方面的优势,包括其有效表达能力、综合生成能力、时空比较能力以及形象显示能力,我们有理由相信,对视觉知识更深入的理解和发展有助于克服人工智能大模型的缺陷。另一方面,鉴于人工智能大模型取得的显著进步以及构建视觉知识所面临的巨大挑战,如何利用大规模统计学习发展视觉知识,将是人工智能领域一个重要研究方向。基于以上,如图1所示,本文系统梳理了视觉知识理论的发展脉络,并探讨了视觉知识在推动人工智能发展中扮演的关键角色。具体而言,本文首先深入探讨了视觉知识理论基础,并全面回顾了有关领域近年来重要研究进展。继而,本文指出视觉知识有望为构建新一代人工智能提供关键理论和技术支撑,并为应对当前人工智能技术日益突出的可靠性、可解释性和责任归属等问题提供新的解决思路。此外,本文还探讨了若干具有前景的研究方向,即通过视觉知识与大模型的深度耦合,实现更加强大的人工智能。最后,本文指出,构建更新形式更深层次的大规模视觉知识是发展新一代人工智能技术的重要基础。我们希望通过本研究能够促进计算机视觉、图形学和机器学习等领域的协同合作,共同推动视觉知识的进一步发展,以提升机器的智能水平,使之更接近人类智能。
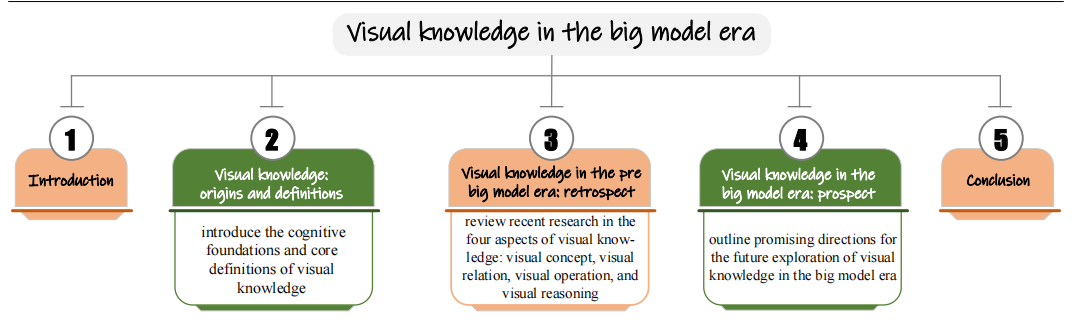
图 1 本文总体结构
2 视觉知识:源起与定义
本章通过深入探讨视觉知识的认知科学基础(第 2.1 节)和核心定义(第 2.2 节),帮助读者全面理解视觉知识理论。
2.1 源起
视觉知识理论[1]有着深厚的认知科学基础。
视觉信号在人脑信息处理中的重要作用
人类对世界的认识不仅来自文字材料和语言,还来自对真实环境的视觉感知。认知科学和生物心理学的研究成果[5] 显示,人类大脑近半数的皮层区域专门用于处理视觉信号刺激。有数据进一步揭示,人脑处理图像信息的速度是处理文字速度的6万倍,并且传输到大脑的信息中高达 90% 是视觉信息。这些发现表明,人脑对视觉信号的依赖程度远高于其他类型信号。
视觉记忆:存储内容的容量、功能和表达方式
认知科学研究表明,相较于声音记忆,人类对图像的记忆更加稳固持久[6]。视觉记忆广泛存在于人类日常活动中,并与许多高阶认知功能密切相关,例如视觉心象——即在没有外界感官输入情况下,在脑海中重现视觉场景的能力。视觉记忆,无论是主动记忆(即视觉工作记忆,visual working memory)还是被动记忆(即视觉长期记忆,visual long-term memory),都能将视觉信息有效编码并存储在大脑中,从而支持在认知任务中对此类信息的检索与操作。认知心理学家不仅研究了视觉记忆的容量和认知功能,还深入研究了视觉记忆中存储内容的表达方式。自 20 世纪 70 年代起,一系列研究与实验[7–10] 揭示了视觉记忆表征与言语记忆表征的根本差异,表明视觉记忆可以支持包括旋转、折叠、扫描以及类比等在内的多种心理操作,并具有层次结构[11]。
感知、视觉记忆和人类知识的相互作用
通常,言语记忆——即涉及到语言、单词、句子等信息的记忆处理——主要由人脑左半球承担。这是因为左半球在大多数人中负责语言和逻辑处理任务,包括阅读、写作和语言理解等。相比之下,视觉记忆则更依赖于人脑左右两个半球的协作。视觉记忆是人类对先前所见视觉信息回忆的能力,涉及图像、空间布局和视觉场景等信息的编码、存储和检索,完成这些任务需要大脑两个半球的参与。人脑右半球侧重处理空间关系、面孔识别、图像整体和艺术感知等视觉和空间信息,而左半球则主要参与处理与视觉信息相关的逻辑和顺序。因此,大脑两个半球都对视觉记忆的形成和回忆起到重要作用。
视觉记忆可以是情节性(episodic)的(即与特定时间和地点的视觉事件或体验关联的记忆),也可以是语义性(semantic)的(即与特定背景无关的一般事实或视觉概念的记忆)。目前学界普遍持有的观点是:人类视觉记忆的内容则取决于过去的经验和脑海中积累的知识[11]。视觉记忆与人脑储存的知识存不同:视觉记忆是指回忆之前看到的视觉信息的能力。因此,视觉记忆是视觉感知信息的存储和检索。而人脑中储存的知识是预先存在的表征,作为人类对视觉对象加以识别和理解的基础。例如,当我们第一次看到一幅橘子图片时,我们脑海中储存的关于橘子的视觉形象和特征知识使我们能够识别出这个物体。之后,当我们遇到另一个橘子图片时,视觉记忆就能让我们判断它是否就是我们之前看到的那个橘子。因此,我们遇到的一些特别个例,例如某个人脸,会在视觉记忆中以更高保真度被呈现出来[12],而一般视觉概念则通过统计归纳后表示[13]。认知科学研究还表明,储存的知识会影响我们如何形成和利用视觉记忆,而知识和视觉记忆也会影响我们如何感知和关注视觉刺激。
视觉知识理论的提出
上述认知科学领域的研究成果揭示视觉感知、视觉记忆以及人类知识之间存在紧密且复杂的联系:从视觉信号中感知到的信息支持不同认知行为(例如视觉记忆和心象),并且对知识构建起到关键作用;同时,这些积累的知识又在反向塑造视觉记忆,影响视觉感知过程,并极大地促进了我们对周围世界的理解。目前人工智能技术研究重点主要集中在视觉智能感知上,而忽视了对人类关于视觉物体心理表征的研究,为填补这一关键空白,视觉知识理论[1] 由此诞生。
2.2 定义
根本而言,人类的视觉知识是针对视觉对象的稳定心理表征,可以被视为完成不同(视觉)任务的共性规则。视觉知识是从人类的视觉经验和记忆中抽象出来的,并保留在人类大脑中。视觉知识使人类能够对世界进行记忆、想象和推理,并完成不同的复杂任务。神经心理学的相关研究也揭示视觉对象心理表征的一些关键特点:
• 捕捉视觉对象典型属性的能力,如形状、大小、颜色和纹理。
• 描述视觉对象之间静态和动态关系的能力,如相对位置、动作、速度和时间顺序。
• 对视觉对象进行时空操作的能力,如改变形状、运动轨迹甚至场景,进行类比和联想、以及预测未来结果。
• 推理能力,如类比、归纳和演绎新任务,对现有的概念进行组合以形成新的概念,以及基于少量样本进行泛化。
由此可见,人类的视觉知识不仅是视觉对象的稳定抽象表征,还是一个可以支持不同认知能力的、主动的、生成式过程。因此,视觉知识理论一个核心观点是:人工智能也应当采用类似方式构建和使用视觉知识。
更具体地说,视觉知识[1] 作为一种新的知识表示形式,主要包含 4 个基本组成部分:即视觉概念(第 2.2.1 节)、视觉关系(第 2.2.2 节)、视觉操作(第 2.2.3 节)和视觉推理(第 2.2.4 节)。基于这 4 部分,视觉知识能够帮助人工智能系统对视觉物体进行全面理解、鲁棒识别和推理,求解不同视觉任务。
2.2.1 视觉概念
视觉概念代表视觉物体对象所属类别,隶属同类的物体对象往往具有某些共同特征。根据视觉知识理论,视觉概念由典型和范畴构成。以“苹果”这一视觉概念为例,提到“苹果”这个概念,人们会自然地联想到一系列典型苹果图像,这些图像捕捉了“苹果”类别中最常见或最具代表性的特征或属性。这些代表性图像被视为典型,构成识别或生成属于某一概念个体对象的基础。例如,人们对于苹果的典型印象可能包括其颜色(如红色、绿色或黄色)和形状(如圆形或椭圆形)。人们可以根据依据与典型的相似程度对物体对象进行分类,即使物体对象与典型并不完全相同。例如,某个待识别的苹果个体对象与“苹果”典型的外观并不完全相同,比如该苹果个体可能比“苹果”典型颜色更浅或更深、更大或更小、更光滑或更粗糙。然而,具体物体对象与其典型的偏差程度是有一定限度或范围的。当物体对象与典型的差异在合理限度之内,它就被认定为属于该典型对应的视觉概念;但若差异过大,超出合理界限,该对象就可能属于另一个不同的视觉概念,例如“梨”或“西瓜”。一个类别(典型)可能接受的变化范围被称为范畴。决定了何种程度的特性(如形状和颜色)变化可以被视作属于该类别(典型),而超出范畴的则不被包含在内(见图 2)。
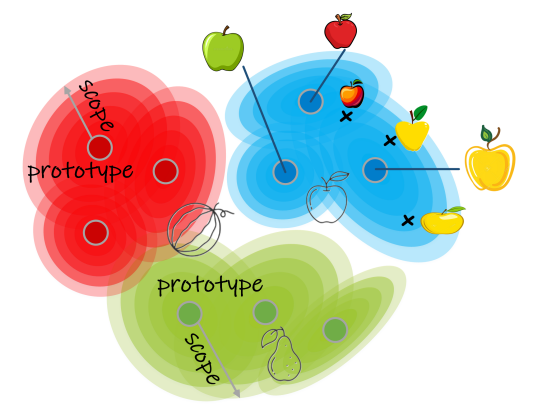
图 2 基于典型和范畴的视觉概念表示示意图。这里我们展示3个视觉概念,即梨、苹果和西瓜
用典型表示视觉概念的方法与经典的原型理论(prototype theory)相符,自 1975 年[14] 原型理论被提出后,在认知科学及其它领域得到广泛认可,成为认知分类(cognitive categorization)的重要理论基础。原型理论认为,人类大脑通过原型来表示事物,原型的本质是一种能捕捉类别成员之间规律和共性的认知表征。根据原型理论,人类大脑在分类过程中,首先需要将待识别物体对象与存储在记忆中的原型进行比较,并评估它们特征的相似性,之后根据最相似的原型对对象进行分类。形式上,假设 𝒳 是数据空间,𝒴 ={𝑦1,⋯, 𝑦𝐶} 是 𝐶 个类别的集合。给定一个数据实例 𝒙 ∈ 𝒳,原型分类模型将其划分为最相似原型的类别 𝑦 ∈ 𝒴:
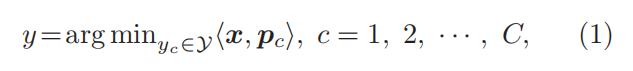
这里 ⟨⋅, ⋅⟩ 表示某种距离度量,𝒑𝑐 指类别 𝑦𝑐 的典型,𝒙 和 𝒑 的每个维度用于表征/编码某些特定的属性。这种简洁优雅的原型模型帮助研究人员开发出许多用于分类的计算模型,包括著名的 𝑘-近邻(𝑘-NN)和最近中心分类器(Nearest Centroids)[15,16]。这些基于原型的分类模型的不同之处主要在于如何得到原型。例如,𝑘-NN 算法将数据样本的 𝑘 个近邻作为原型,而最近中心分类器则将每个类别的中心点或平均值作为原型。
原型理论被广泛认为是一种可行的视觉分类方法,这是因为视觉类别往往展现出显著的家族相似性结构(family-resemblance)。但是,由于原型理论不包含类别范畴的概念,其对类内差异的建模能力不足。
从统计学角度来看,使用原型和范畴共同描述类别的方法,本质上是在建模数据分布 𝑝(𝑥|𝑦)。因此,基于原型和范畴的视觉概念模型是一个生成式分类器(generative classifier),它通过估计类别的条件概率,使用贝叶斯法则进行分类[17]:
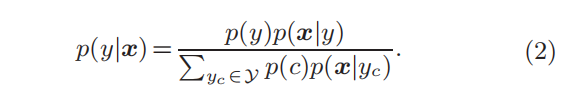
这与当前常用的判别式分类器(discriminative classifiers)有本质不同,判别式分类器简单将输入直接映射为标签来执行分类任务,而生成式分类器需要对数据的分布进行建模[18],这也导致生成式分类器的训练难度较大,这也部分解释了为什么构建视觉知识非常困难。
2.2.2 视觉关系
视觉知识理论中,“视觉关系”一词指视觉概念之间的联系和相互作用,它在指导复杂视觉认知时发挥着关键作用。人类拥有与视觉对象属性相关的广泛知识,包括固有属性(如颜色、形状和纹理),以及超越固有属性的关系属性(视觉关系),即如何关联不同的视觉对象,如视觉对象的相对位置、语义依赖关系和功能性(affordance)。这些关系属性(视觉关系)可分为不同的类别,对应视觉认知的不同方面:
几何关系(geometric relations):该关系根据物体或概念的空间构型和几何构造,如相对位置、方向、距离、交叉、对齐、平行、垂直等,勾勒物体或概念之间的相互联系(见图 3a)。该关系揭示了自然的秩序与和谐,有助于人类理解环境中物体的结构和组织。例如,果核位于苹果的中心位置;同样,我们对人脸的识别不仅仅依赖对眼睛、鼻子等五官的认识,还依靠对这些关键面部元素确切空间布局的理解(见图 3b)。
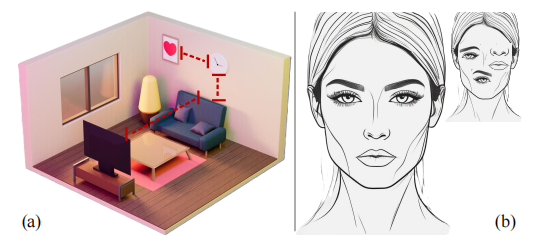
图 3 几何关系示意图
时序关系(temporal relations):该关系虽然并不总是直接以视觉形式呈现,但却能通过标记视觉场景中事件和变化的顺序或时间丰富视觉知识。例如,时序关系可以描述动作进程,如“之前”“之后”和“期间”,这对于理解环境和活动的动态变化非常有用。图 4描述了 Allen 等人定义的 13 个基本时间关系[19]。
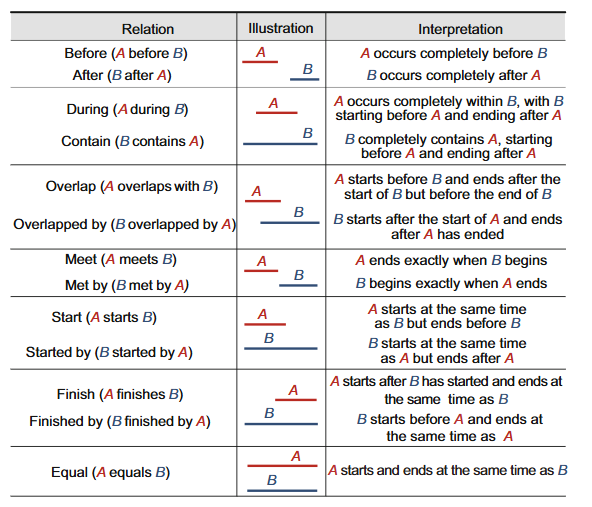
图 4 艾伦区间代数(Allen’s interval algebra)定义的 13 种基本时间关系示意图[19]
语义关系(semantic relations):该关系明确了物体或概念之间以其意义或重要性为基础的关联,增强人们对视觉信息中的意义、部分-整体关系、相似性、差异性、包含-排除标准和语义依赖性的把握。例如,部分与整体关系,帮助人们将视觉概念进行分解,得到其组成部分,且这些子概念-子概念和子概念—总概念之间均保持着各自的语义联系,如苹果可以分解为果核、果肉、果皮和果梗,人体可以分解如图 5a 所示的不同部分;分类关系,即视觉概念可以与其他概念(包括属性相同的视觉概念和上位概念)进行分类,这些概念之间以及与类别之间存在相似性和差异性的语义关系,如狗和猫是不同类型动物(图 5b);语义关系,涉及更抽象的关联,如“鸽子”与“和平”之间的隐喻关系(图 5c),以及根据特定标准或规则(是否属于某个领域等)纳入或排除视觉概念,如苹果和橘子被归类为水果,而不是蔬菜(图 5d)。
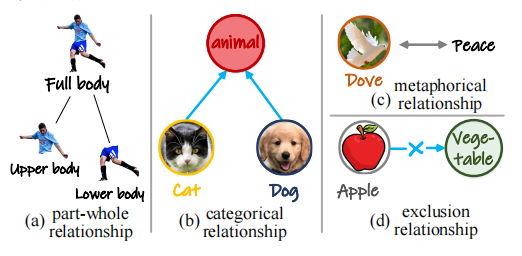
图 5 语义关系示意图
功用关系(functional relations):该关系旨在根据物体的物理特性或功能来解释物体之间的相互作用,从而促进人们对目的、效用、效果、原因和行动相关结构的理解,如刀可以切面包、椅子可以支撑人、笔可以在纸上写字等。该关系建立了行为与其环境前因(刺激)和后果(强化者或惩罚者)之间的因果联系,例如,如果一个孩子知道按下按钮会发出声音(前因),他/她可能会频繁地按下按钮(行为),以更频繁地听到声音(后果)。功能关系是推理和解决问题的基础,它促使人们从现有事实或行为中推断出新的事实或行为。因此,通过确定问题行为与其环境变量之间的功能关系,人们可以设计干预措施,改变问题行为的前因后果,或利用具有相同功能的行为进行替代。例如,人们可以利用功用关系推断——如果一把刀可以切面包,那么它也可以切奶酪;如果想把石头砸成碎片,就需要一把锤子(图 6)。此外,功能关系可以为事实或行为提供解释,如为什么用刀切面包、为什么坐在椅子上等。
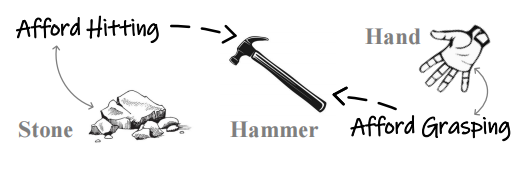
图 6 功用关系示意图
因果关系(causal relations):该关系确定了视觉概念之间的因果联系,对于解释视觉场景中为何发生变化以及变化如何发生至关重要,可以对视觉环境中的行为和事件的结果进行预测推理,如下雨会导致街道潮湿(图 7)。

图 7 因果关系示意图
建模视觉关系是视觉知识理论的核心,它使得人工智能系统能够以结构化和有意义的方式处理和解读视觉信息。通过对以上视觉关系进行分类和分析,研究人员可以开发出更复杂的人工视觉感知模型,从而增强机器模拟人类理解和推理的能力。
2.2.3 视觉操作
视觉概念是视觉知识的关键要素,它使人们能够识别、分类和命名在环境中观察到的实体。视觉关系则增强了人们对实体相关联系和功能的理解。进一步,视觉知识理论中的“视觉操作”,指在空间或时间上对视觉概念进行变换,如构成、分解、替换、组合、变形、运动、比较、破坏、还原和预测等。认知科学研究[20–24] 表明,视觉概念可以通过认知过程进行操作,如在空间或时间上对其进行转换,改变其组成部分或特征,以及对视觉概念的各种操作。视觉操作有助于增强人们对世界的理解,提升创新和执行复杂任务的能力。同时,视觉操作描述了视觉知识的动态呈现,展示了静态图像或场景如何通过认知参与来重建:
合成(composition)和分解(decomposition):合成,即将多个视觉元素融合在一起,形成一个新物体或概念;分解,即将一个物体分解成其组成元素。这些操作可以加深对复杂系统的理解,即分析复杂系统及其组成部分,以及各部分的组合方式;可以产生具有创造性的概念或物体。例如,将苹果与其他物体(如面粉)进行合理融合,可以创造新的物体(如苹果派;图8)。
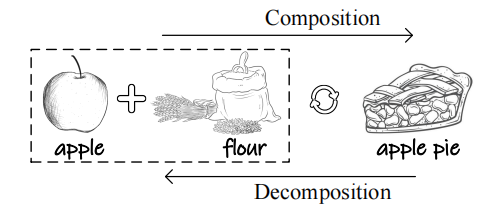
图 8 合成和分解操作示意图
替换(replacement)和组合(combination):替换,即用一种视觉元素代替另一种视觉元素。组合,即将不同元素合并成一个新实体。这些操作是创造性思维和解决问题的基础,促进其他配置和解决方案的探索。它们还可以使人们想象出各种场景,从而加深对物体功能的理解,如用苹果代替汽车的轮子(图 9)等。
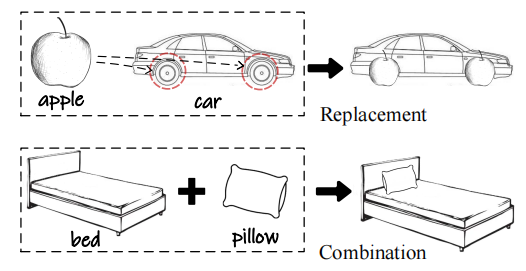
图 9 替换和组合操作示意图
变形(deformation)和运动(motion):变形,即改变物体的形状或结构。运动,即随着时间的推移改变物体的位置。这些操作有助于理解物体的内外属性、解释各种物理和生物过程,以及通过动画和仿真实现真实现象的复现。例如,在空间中可对一张纸进行缩放、旋转或平移操作;或通过加速、减速、反转、循环或对轨迹进行差值来改变下落纸球的运动(图 10)。
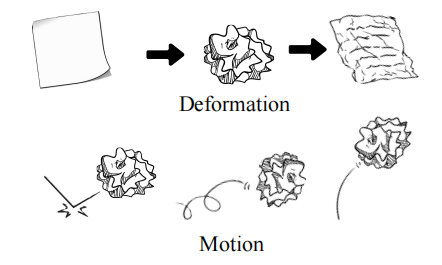
图 10 变形和运动操作示意图
比较(comparison):该操作需要评估视觉元素之间的异同,帮助分类和决策过程。例如,将一个苹果与其他苹果或物体进行大小、重量等方面的比较(图 11)。该操作对于模式辨别、决策制定和视觉经验学习至关重要。
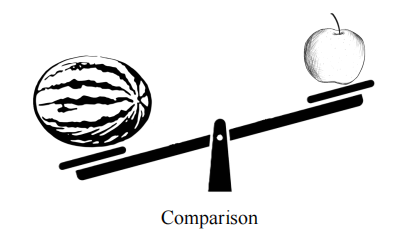
图 11 比较操作示意图
破坏(destruction)和恢复(restoration):破坏包括移除或解构视觉元素,恢复侧重于修复或使其还原(图 12)。这些操作可应用于多种场景,如研究自然灾害及后果、文物保护等。
图 12 破坏和恢复操作示意图
预测(prediction):该操作旨在根据当前或过去的信息预测视觉元素未来的状态或变化(图13),对规划、预测和预知行动及事件结果至关重要。
图 13 预测操作示意图
视觉知识理论中的视觉操作,为理解如何动态操作和利用视觉信息提供了框架。这些操作表明视觉知识的强大及多样性,展示了视觉知识在提升人们与视觉世界互动、修改和作出预测的能力方面的关键作用,以及它在各个领域的巨大应用潜力。
2.2.4 视觉推理
视觉知识理论中,“视觉推理”一词指运用从视觉概念、关系和操作中获得的知识来归纳视觉数据、解决问题和作出合理决策的过程(见图 14)。该复杂的过程通常需要对视觉概念和关系进行一系列有条理的操作,从视觉观察和已有知识(常识和知识)中得出有效、合理的结论。

图 14 视觉推理示意图
简言之,视觉概念(第 2.2.1 节)涉及视觉对象的识别和分类;视觉关系(第 2.2.2 节)旨在理解这些对象/概念之间的联系;视觉操作(第 2.2.3 节)应用于操作或分析视觉对象/概念的过程;视觉推理即为使用视觉概念、关系和操作来解决问题、做出决策或从视觉信息中得出合理结论的过程(第 2.2.4 节)。
3 大模型时代前的视觉知识:回顾
本节提供视觉知识的近期研究概述,并围绕第 2 节介绍的视觉知识的 4 个核心组成部分进行讨论,即视觉概念、视觉关系、视觉操作和视觉推理。
3.1 视觉知识:视觉概念
第 2.2.1 节提出的利用原型和范畴来表示视觉概念的思想,已经在一些核心的计算机视觉任务中得到应用,如场景识别和场景解译。例如,通过将每个类别表示为一个或多个原型,基于原型的神经网络(prototype-based networks)[25]、非参数神经分类器(nonparametric neural classifier)[26] 和基于最近质心的神经分类器(nearest centroids based neural classifiers)[27] 等方法根据观测样本与原型的相似度进行分类。这些方法在小样本和通用场景中均获得较好结果,但它们无法捕获每个类别或原型的范畴特性。为更全面建模数据分布,深度生成式分类器(deep generative classifiers)[28] 采用高斯混合模型(GMM)来估计每个视觉概念或类别的数据密度。该方法通过高斯混合模型的参数,即均值向量和协方差矩阵,来表示原型和范畴,在封闭和开放场景中都取得优异表现,初步展示了使用原型和范畴表示视觉概念这一思想的强大。
3.2 视觉知识:视觉关系
正如第 2.2.2 节所讨论的,视觉概念之间可以通过多种方式相互关联,形成各种类型的视觉关系,包括几何关系、时序关系、语义关系、功用关系和因果关系。
几何关系涉及物体在空间中的排列和变化,包括位置、方向、大小和形状。胶囊网络(capsule network)[29] 是对视觉元素间几何关系(包括空间层次结构表示和姿态信息)建模的一次重要尝试。胶囊网络的核心思想是使用一组神经元(即“胶囊”)来表示图像中不同视觉对象及其各自的状态。在胶囊网络中,每个胶囊都会输出一个向量,向量的长度(即模长)表示视觉对象存在的概率,向量的方向则用于描述视觉对象的空间关系和变换,如位置、旋转、缩放和反射。虽然胶囊网络在理论上颇具吸引力,但在实际应用中的效果并不尽如人意,这表明视觉几何关系建模是一个非常有挑战性的任务。
语义关系定义了不同视觉概念在语义上的相互联系。近期相关研究主要集中在视觉理解(visual understanding)[30] 和人类语义解译(human parsing)[31,32] 任务上。例如,Li 等人[30] 提出一种基于预定义语义层级关系的神经解析器(neural parser),能够生成结构化的、像素级的视觉场景描述。在训练过程中,该解析器通过将语义概念间的组合与分解关系纳入约束条件,增强了模型的判别能力。例如,如果当前观测被认为可能是猫,那么该观测被认为属于任何车辆类别的概率都应当非常低。值得注意的是,这些语义层级关系并非自动学习得到,而是预先定义的。这一点表明学习视觉语义关系的复杂性和挑战性,也指明未来研究方向。
时序关系即视觉事件和动作发生的顺序关系,相关研究领域包括动作识别(action recognition)和视频物体检测(video object detection)等。例如,在动作识别领域,Something-Something 数据集[33] 要求进行细粒度的运动分析和时序建模,以区别诸如拾起某物与放下某物的行为,为时序关系理解提供了有效的评估基础。视频物体检测是另一个经典的、与时序关系理解相关的任务,旨在对视频序列中的物体实例进行分类、定位和跟踪[34,35]。
功用关系描述了物体和其能够支持的行为之间的关系。多种计算机视觉任务研究视觉概念间的功用关系,主要包括人物-物体交互(human-object interaction)检测和可供性估计(affordance estima-tion 或 functional recognition)。其中,人物-物体交互检测[36–38] 任务旨在识别视觉场景中人、物之间的交互关系,如 < 女孩,吃,苹果 >。可供性估计[39,40] 要求根据视觉信息预测动作—物体之间的功用性,如判断一个物体是否可以吃(eatable)、可以打开(openable)等。
场景图生成(scene graph generation)[41,42] 是另一个与视觉关系理解紧密相关的任务,目标是构建图结构的视觉场景描述,即场景图。在场景图中,节点表示视觉对象,边表示视觉对象之间的关系(包括空间关系、部分-整体关系和交互关系)。每对物体间的关系通过三元组 < 主体,谓语,宾体 > 来表示,如 < 男孩,驾驶,汽车 >,< 汽车,有,轮子 >,< 汽车,靠近,建筑物 >。尽管场景图生成任务,在某种程度上,通过一个任务覆盖了几何关系、语义关系和功能关系等三种视觉关系,但其包含的关系种类较为有限,如功用关系通常聚焦以人为中心的动作,较少考虑以物体为中心的功用性关系。此外,场景图生成往往需要耗费大量人力,用于显式标注视觉关系作为训练数据。
因果关系描述了视觉场景中事件、动作和物体对象是如何影响彼此的。近年来,深度学习技术取得可喜进展,但其严重依赖对数据分布的拟合,即倾向于学习数据中基于相关性的模式(correlation-based patterns,即统计依赖性,statistical dependencies),难以从数据中学习更本质的因果关系。因此,深度学习技术会受到数据偏见的影响,并且泛化能力较弱[43]。为应对这一挑战,近期有研究致力于揭示视觉数据中的因果关系。这类方法是在深度学习框架的基础上,从视觉数据中提取因果表达,进行因果推理[44,45]。利用基于因果性的视觉特征,研究者们在视觉识别[46]和视觉问答(visual question answering)[47] 等领域取得显著进展。此外,这些方法还可以自动从视频数据中发现环境和物体变量之间的因果依赖关系[48],从而提高深度学习模型的可解释性[49]和领域泛化能力[50]。
3.3视觉知识:视觉操作
如第 2.2.3 节所述,视觉操作旨在对视觉概念或对象在空间或时间维度上进行操作。定制化视觉内容生成(customized visual content generation)是与视觉操作非常相关的研究领域,即根据文本描述创作个性化的视觉内容。文本描述可以灵活的表达用户的编辑意图,可以支持替换、组合等多种视觉操作。多年来,基于文本的图像生成一直是学界研究的热点,如各类深度生成模型——GAN[51]、VAE[52]及自回归模型[53]。近期,扩散模型(diffusion model)极大提升了生成图像的保真度和与文本的一致性[54,55],但这些模型在针对特定目标对象(例如仅在单个参考图像中出现的某一个动物或物体对象)的定制化生成方面存在局限。为应对该挑战,研究者研发出多种定制化视觉内容生成算法[56,57]。这些算法主要是通过改进经过预训练的基于文本的图像生成模型,使其能够针对一个或几个由用户提供的参考图像所指定的目标对象,实现下在人类自然语言指令指引下的内容生成。这些方法能够创建符合人类意图的具有创意的静态图像[56,57] 和时序连贯的视频内容[58],但难以执行更复杂的视觉操作(如分解、破坏和恢复)。
新视角合成(novel view synthesis),指的是利用单个或多个视角下的观测图像生成指定新视角下的观测图像,主要涉及变形和运动两种视觉操作。在合成视角中模拟物体的形变和运动对新视角合成非常重要,这需要深入理解物体的空间和时间属性,确保生成的场景图像外观真实,并且生成场景中的物体以符合物理世界规律的方式运行。三维建模(3D modeling)和神经辐射场(NeRF)[59]等技术极大推动了该领域的发展。其中,神经辐射场能够创建细节丰富且连续的三维场景,以及实现不同视角之间的平滑过渡和逼真形变[60],但在训练和推理过程中一般需要较多的计算资源。最近,三维高斯泼溅(3D Gaussian splatting)[61,62]技术通过使用数百万个三维高斯表征一个三维场景,可以在实时条件下实现高质量视角合成。并通过引入额外的操作,如空间—时间模块(spatial-temporal module)[63]和高斯属性(Gaussian properties)[64],三维高斯泼溅能够对给定场景的动态变化和物体形变进行更加有效地建模。
预测这一视觉操作是指基于视觉预测数据预测未来的状态、动作或事件,在计算机视觉领域有多个相关任务,主要包括:
• 人类轨迹预测:预测人类在环境中的未来移动路径,如行人在人行道上或购物者在商场中的路径。该任务需考虑社会行为规范和周围环境对人类轨迹的影响[65]。
• 未来帧预测:生成视频序列的未来帧,以准确描述观察场景和物体的持续演变[66]。
• 动作预测:预测视频中目标主体的未来动作,如预测运动员在体育比赛中的下一步动作或司机在交通场景中的行为[67]。
• 物理交互预测:预测物体之间物理交互的结果,如预测碰撞后物体的运动[68]。
• 事故预测:在事故发生前识别潜在危险,如通过监控视频预测车辆碰撞或工业事故[69]。
3.4 视觉知识:视觉推理
视觉推理是指通过综合利用视觉概念、关系和操作来从已知的前提或证据中推导出合理结论的过程。举例来说,通过功用性关系可以得出结论:“如果A能够切割B,则可以推断B 是柔软的”,或“如果A能够支撑B,则可以推断A是稳定的”。推理是人类理解世界的根本认知过程,根据论据的性质和强度,推理可被细分为演绎推理、归纳推理、溯因推理和类比推理等类型。机器推理(machine reasoning)是人工智能领域的一个关键分支,旨在实现自动化推理,与机器学习互为补充。推理过程涉及将已知的(可能是不完整的)信息与背景知识相结合,借助认知神经科学、心理学、语言学及逻辑学等多学科知识,对未知或不确定的信息进行推断[70]。
在自动推理系统发展初期,主要有两种方法:连接主义和符号主义。20 世纪 40 年代,McCulloch和 Pitts 提出首个简化的神经元模型[71],为神经网络和连接主义研究奠定了基础。从连接主义角度来看,推理是由多个简单处理单元相互连接共同工作的结果。深度神经网络是连接主义的典型代表,其灵感来源于认知神经科学,即人类的神经网络能够储存和检索短期及长期记忆,并通过分析处理新的复杂信息进行推理。尽管连接主义模型(尤其是神经网络)在捕捉数据中的统计模式方面表现出色,但受到当时计算资源和数据规模的限制,难以实现精细的类人推理。这一挑战促使学界转向符号主义,符号主义根植于逻辑和哲学,并从 20 世纪 50 年代中期到 80 年代末成为“老牌人工智能”(good old-fashioned AI)的主流方法。符号主义认为,世界中的物体对象和概念的符号表征是人类智能的基础,而推理则是通过操作给定的结构化符号表征,从符号编码的信息中推导出额外信息的过程。符号主义通常应用一系列严格的规则和形式逻辑来操作离散符号,从而以精确的方式进行推理。规则定义了如何操纵符号以得出结论或做出决策,例如,根据“所有人都是凡人”和“苏格拉底是人”的前提,通过符号规则可以推导出“苏格拉底是凡人”。符号主义方法以其透明的推理过程和逻辑步骤的可验证性,在处理规则明确和离散问题方面具有优势。然而,由于定义规则的难度和现实问题的高度不确定性,这类方法在处理包含噪声的真实数据时并不理想,难以满足实际应用需求。概率推理(probabilistic reasoning)技术,例如贝叶斯网络、马尔可夫决策过程和随机模型,通过概率论的框架来表达和处理不确定性,为推理提供了概率估计。尽管这些技术赋予了符号方法处理不确定性的能力,但由于其固有局限性,即缺乏真正的学习能力和对手工定制规则的过度依赖,在实际场景中的应用仍然有限。
最近,大规模数据集的出现和计算能力的显著增强使连接主义——尤其是深度神经网络——迎来复兴。深度神经网络在模式识别和预测建模方面表现出色,但在执行显式符号操作方面却面临挑战。具体而言,尽管深度神经网络擅长学习子符号(即连续的嵌入向量),但其结构对于推理过程中经常涉及的离散符号操作则适应性不足。
此外,深度神经网络主要通过归纳方法从数据学习,其决策过程往往缺乏透明度,这与基于明确预设规则和知识库进行逻辑推理的演绎过程相反,前者难以解释其结论是如何得出的,后者则基于明确、预设的规则和知识库进行透明易懂的逻辑推导。深度神经网络的这种不透明性,在涉及重要决策的应用场景(如自动驾驶)中构成严重问题。再者,符号主义方法虽然在学习能力上相对较弱,但在进行原则性判断(例如演绎推理)方面表现优异,且具备高度的可解释性,即基于清晰和逻辑的原则进行操作,其推理过程易于追踪和理解。鉴于深度神经网络在执行明确推理任务方面的局限性以及连接主义与符号主义方法的互补性,神经-符号计算(neuro-symbolic computing)尝试将人工智能的这两种基本范式进行系统性整合,以期实现更强大、更透明和更鲁棒的推理框架[73],在近年来受到越来越多关注[72]。
传统上,与视觉推理相关的任务主要包括视觉问答(visual question answering)和视觉语义解析(visual semantic parsing)。视觉问答任务的目标是基于视觉内容对问题作出回答,这需要对视觉和语言信息进行全面的理解和推理。Andreas 等人[74] 提出一种基于神经-符号计算的视觉问答系统,该系统将问题求解转化为由一系列可学习的神经模块组成的可执行程序,每个模块通过神经注意力机制实现,并对应于某个特定的基本推理步骤,这些模块可以直接用于分析图像,如对象识别、颜色分类等。这项开创性工作激发了诸多后续基于神经-符号计算的视觉问答相关研究[75–77]。视觉语义解析任务的目标是以层次化语义结构的形式为视觉观测提供全面的解释。语义层次结构作为预先给定的知识库,定义了视觉语义概念之间的符号化关系。Li等人[78] 在网络的训练和推理阶段以端到端的形式嵌入符号逻辑,构建了一个强大的基于神经—符号计算的视觉语义解译器。此外,其他相关研究任务还包括视觉溯因推理[18] 和视觉常识推理[79]等。
近期,受益于语言大模型强大的语言理解能力,许多研究着手探索如如何利用语言大模型解决复杂的视觉推理任务。VisProg[80]是该领域一项开创性工作,该方法通过将复杂任务分解为一系列更易于处理的子任务(如文本解析、对象检测和计数等)来进行求解。例如,在处理“这两张图片总共包含六个人和两艘船吗?”这一任务时,VisProg 首先对文本进行解析,将整体任务细分为对象检测和计数两个子任务。在逐个完成这些子任务之后,得出整个问题的答案。在此基础上,HuggingGPT[80]利用语言大模型调用公共网络上可用的 AI 模型,进而解决更为复杂的推理任务。
为进一步解决现实世界中包含动态观测的实际任务,DoraemonGPT[81]为语言大模型配备了符号记忆,用于收集和存储与任务相关的时空信息;同时,该模型通过综合利用 AI 工具、搜索引擎、教科书和知识数据库,扩展了知识来源。此外,它还采用基于蒙特卡洛树搜索的规划器,以提升在庞大解空间内的搜索效率。这些研究不仅展示了语言大模型在复杂视觉推理任务中的潜力,也为未来研究提供了新的方向和思路。
3.5讨论
通过回顾近年来学界在视觉知识的4个关键方面(即视觉概念、视觉关系、视觉操作和视觉推理)的研究进展,可以得到以下几个重要结论:
第一,视觉知识与人工智能两大基础范式(即连接主义与符号主义)紧密相关,被广泛应用于众多研究领域(如计算机视觉、图形学、机器学习和逻辑学),关联着一系列基础且具有挑战性的任务(如视觉识别、适应性估计、文本到图像合成、新视角合成、未来预测),涉及多种先进技术(如胶囊网络、神经-符号计算和语言大模型等)。这凸显了视觉知识的重要性,以及为实现这一目标而进行跨学科合作的必要性。
第二,在某些与视觉知识相关的领域虽然取得一定进展,但许多核心问题仍然充满挑战或尚未被充分探索,如基于原型和范畴的视觉概念、因果关系、复杂的视觉操作(如分解、破坏、和恢复)和视觉推理。这一点凸显了构建视觉知识的难度,也体现了提出视觉知识理论的主要动机之一:学界缺乏一个统一的、能够涵盖视觉智能各个方面的原则性框架。
第三,尽管语言大模型展现出处理复杂问题的强大能力,但也加剧了神经网络算法固有的“黑盒”问题。语言大模型拥有数十亿甚至数万亿的参数,为试图解析其内部工作原理的尝试带来巨大阻碍,这些大模型的推理方式与人类的方式有所不同,生成的答案只是表面上看似合理,经受不起仔细检查。这揭示了语言大模型缺乏真实的理解能力,同时,其不透明性阻碍了在推理过程中进行识别和纠错的能力。因此,未来研究需深入探索如何在视觉知识的框架下构建语言大模型。
4 大模型时代的视觉知识:展望
本章首先探讨如何利用视觉知识增强人工智能大模型,之后探讨如何利用大模型辅助视觉知识构建。
4.1 视觉知识赋能人工智能大模型
大模型的出现标志着人工智能的发展进入一个新阶段,但大模型在透明性、逻辑推理和灾难性遗忘等方面面临诸多挑战。接下来我们将讨论将视觉知识整合到人工智能大模型有望解决这些挑战。
缺乏透明性(transparency)是大模型一个较为突出的局限。透明性指模型内部运作机制及其决策过程能否被人类理解。由于大模型包含海量的参数,理解其得到特定结论的过程变得异常困难。缺乏透明度不仅严重影响了人们对大模型决策结果的信任——特别是在医疗诊断、自动驾驶等关键应用领域,同时还引发公众关于责任、偏见、公平性和可调试性等问题的担忧。尽管学界研发了一些用于解释神经网络的技术,这些技术主要是通过对逆向工程重要性(reverse-engineer importance values)和输入扰动敏感性(sensitivities of inputs)进行分析,获得经过训练的深度神经网络的后验解释(posteriori explanation)。然而,这些解释本质上是通过模拟特征与输出之间的关系来近似深度神经网络的局部决策行为,并不能真正揭示深度神经网络的决策逻辑[82]。然而,通过整合视觉知识——尤其考虑到基于原型和范畴的视觉概念表征所固有的透明性——则有可能提高大模型的可解释性。在这方面一个具有代表性的工作是 Wang 等人提出的 DNC(deep nearest centroids)模型[27]。DNC 是一种端到端的、基于原型的神经分类器,通过将视觉概念表示为一组从数据中自动挖掘的原型(即类别子质心,class sub-centroids),模拟人类基于经验/案例的推理行为(experience-/case-based reasoning),为大规模视觉识别提供了一个强大又先天可解释的(ad-hoc interpretable)计算框架。这种方法可以进一步扩展,以实现基于原型和范畴的视觉概念表征。如果能够将这种视觉概念表征作为大模型的基础构件,则有望利用视觉知识提高大模型的透明性。
人工智能大模型虽然擅长模式识别和文本/图像生成,但缺乏对生成内容底层逻辑的理解。这一局限在需要理解因果关系、抽象概念或进行复杂逻辑推理的任务中尤为明显。例如,大模型可能生成看似合理但实际上不准确或荒谬的回答,这种现象被称为“幻觉”,这反映了大模型仅仅只是对人类行为进行表面模仿,而非深层次理解[83]。这一问题根源在于大模型基于统计模式和浅层相关性特征进行学习和生成,而不是深入挖掘和理解问题背后的因果关系。虽然最近提出一些旨在增强大模型推理能力的策略,例如思维链(chain of thought)[84]和思维树(tree of thought)[85],能够在一定程度上提升大模型处理复杂任务的能力,但这些方法距离实现真正的推理(比如涉及复杂符号概念的操作、理解因果关系、将抽象规则泛化到新场景)还存在很大差距。可贵的是,视觉知识提供了一种明确、强大且统一的知识表示框架,不仅能够全面建模视觉概念及其关系(包括因果关系),还能够有效支持视觉操作和推理。因此,引入视觉知识有望将大模型的推理能力提高到新的水平;推理不再仅限于大模型的隐性知识,还受到视觉知识建模的显性知识的驱动。通过这种方式,大模型能够像人类一样处理包含多个实体和复杂关系的动态场景,解决需要对视觉概念及其关系进行序列化操作的问题,并将学到的知识应用于复杂多变的新场景中。考虑到最近学界在整合基于符号知识的逻辑推理与数据驱动的神经亚符号学习方面的进展[78],我们相信,结合大模型的隐式知识与显式视觉知识,建立多重知识表达[86,87],是一个极具发展前景的方向。
灾难性遗忘是指深度神经网络在接触新数据或任务时,表现出遗忘之前所学知识的倾向。这个问题的根源在于深度神经网络更新其参数的方式;在学习新知识的过程中,深度神经网络会覆写与之前任务相关的参数权重,导致模型在之前任务上的性能迅速下降。而当需要构建能够像人类一样、随时间不断学习不断更新的人工智能系统时,灾难性遗忘构成了重大挑战。灾难性遗忘的一个核心问题在于难以对人工智能大模型进行知识追踪(knowledge trace)。知识追踪是指识别、跟踪和理解一个模型中信息的表示以及处理过程,它能够帮助了解模型所掌握的知识以及模型是如何学习到这些知识的。对人类的学习过程进行知识追踪后,发现人类能够将新知识与旧知识高效融合,实现经验累积。然而,大模型的知识追踪非常困难,例如,由于大模型的复杂网络架构和庞大参数量,很难找到特定知识在大模型中对应的具体位置。视觉知识的理论基础深植于认知心理学,为大模型提供了一种明确的、结构化的、持久的、可编辑的、可追踪的知识表示方式,从而允许在大模型外部更新知识,并进行针对性干预继而防止灾难性遗忘的发生。此外,借助视觉知识,大模型能够构建更为持久且可检索的记忆体系,进而实现类似人类的记忆回溯和理解能力。
4.2 大模型增强视觉知识
在强调视觉知识对于增强人工智能大模型的重要性之后,我们将深入探讨大模型在推动视觉知识发展方面可能发挥的重要作用。
首先,人工智能大模型将成为构建视觉知识的重要基础。大模型非常擅长从海量数据中自动挖掘有效模式。因此,利用大模型进行大规模统计学习,以得到视觉概念的鲁棒表征,并对基本视觉关系(如时间和空间关系)及操作(包括组合、变换和动态变化)进行有效建模,就显得尤为合适。
其次,人工智能大模型可以作为视觉知识的知识来源。大语言模型通过海量文本数据(包括科技论文、维基百科条目、书籍及其他多种信息源)训练得到,不仅能够习得上下文语境,还掌握了大量世界知识和常识[88]。这表明大模型在增强视觉知识方面拥有巨大潜力。例如,大模型可以帮助更加精确地理解概念间的语义关系,这些关系往往在视觉数据中不明显,例如通过文本更容易理解“猫”与“动物”之间的层级关系。但是,大模型习得的知识深藏于神经网络的参数之中,难以直接分析和利用。更棘手的是,这些知识并非完全可靠,而是掺杂着错误、偏见、噪声和一些琐碎信息。因此,要有效利用这些知识,需要特别的方法[89],常用手段包括知识分析(识别并定位大模型中学习的知识)、知识提取(从大模型中提取并表示知识)及知识增强(验证并精炼所提取的知识)。
最后,人工智能大模型可以为视觉知识提供重要补充。大模型依靠文本数据理解世界,从文本中获得的知识不仅能够增强视觉知识,还可以为其提供重要补充。例如,某些知识,如人类内在思想、动机和情绪,以及一些常识性知识(比如“北京是中国首都”),是很难通过视觉数据学习得到的。同理,尽管中国长城的照片可以展现出其雄伟壮丽,但关于长城的历史意义、建设目的及其在中国文化中的特殊地位等信息,主要依赖文本数据获得。此外,认知科学研究表明,视觉记忆与言语记忆并非彼此独立存在,而是以复杂方式相互作用。例如,文本信息可以提供与当前视觉刺激相关的上下文语境,进而影响到视觉记忆;类似地,视觉信息可以为当前语境提供视觉细节线索,进而影响到言语记忆。因此,利用大模型中的知识来补充视觉知识,有助于实现对世界更全面、更深入的理解和建模。
5 结论
在过去十余年中,人工智能取得了一系列突破性进展,尤其是联结主义方法解决了计算机视觉、自然语言处理、语音识别和自主系统等领域长期存在的挑战。得益于海量互联网数据以及不断增强的计算资源,人工智能技术——特别是人工智能大模型——正迅速成为人类社会不容忽视的一部分、甚至有望变成科学发现的重要工具。尽管这一轮人工智能革命已经取得令人瞩目的成绩,并在很大程度上改变了人们的生活方式,但一个共识是,我们今天看到的只是人工智能革命的开始。目前的人工智能模型在透明度、责任归属、以及符号推理等方面仍然存在明显不足。视觉知识在全面建模视觉概念、视觉关系、视觉操作和视觉推理方面具有独特优势,因此有望克服人工智能技术的上述限制,并为发展下一代人工智能技术提供理论支持和实践指南。本文首先从回顾认知科学领域关于视觉心象和视觉记忆的研究入手,探讨视觉知识的源起和核心概念,随后概述了在视觉概念、视觉关系、视觉操作和视觉推理等视觉知识几个主要维度的最新研究进展。通过对当前视觉知识研究现状的全面分析,本文进一步讨论了在大模型时代视觉知识所面临的机遇与挑战,并基于此展望了下一代人工智能可能的发展方向。